Un corpus parallelo allineato può essere un'utile risorsa per il traduttore, come si cercherà di illustrare facendo riferimento all'esperienza personalmente effettuata durante la traduzione di Grimus. Si rimanda a sulla traduzione italiana per una discussione delle caratteristiche più generali del romanzo inglese e della sua traduzione italiana.
La versione elettronica del testo inglese di Grimus, creata a partire dall'edizione Vintage 1996 come descritto in dalla carta al formato digitale, è stato il "testo" effettivo su cui è stata portata a termine la traduzione.[1]
Il corpus parallelo allineato è stato solamente uno degli strumenti utilizzati durante la traduzione. Tra le altre risorse sono da annoverare innanzitutto i dizionari bilingui (il Dizionario Inglese-Italiano Sansoni e il Dizionario Inglese-Italiano Garzanti-Novamedia su CD-ROM, il dizionario elettronico Babylon Personal Translator, English to Italian)[2] e monolingui (il Dizionario della lingua italiana Devoto-Oli e il Dizionario italiano Sabatini-Coletti su cd-rom; il COBUILD Dictionary e l’Oxford English Dictionary su CD-ROM); altre risorse monolingui sono state: il Dizionario dei sinonimi, delle analogie e dei contrari Mondadori e la base dati dei sinonimi presente nel programma di videoscrittura utilizzato, Microsoft Word 97; l’Oxford Dictionary of Current Idiomatic English; Il British National Corpus;[3] diversi testi letterari italiani e inglesi in formato elettronico, reperiti in primo luogo attraverso la rete Internet.[4] Il Wold Wide Web ha svolto la funzione di biblioteca elettronica globale: la parola requition, ad esempio, che compare due volte in Grimus,[5] non è registrata in alcun dizionario, né bilingue né monolingue (non esiste nemmeno nell'OED), e non compare né nel CPR né nel BNC. Una ricerca di requition su vari motori di ricerca sul World Wide Web ha invece portato a tre diversi documenti elettronici contenenti questa parola.[6] A questa funzione si è affiancata quella enciclopedica, ad integrazione di strumenti come la Nuova Enciclopedia Universale Garzanti (edizione 1988) e l’Enciclopedia Microsoft Encarta su cd-rom (edizione 1996). Di particolare utilità per interpretare il testo inglese è stata la produzione critica su Rushdie e su Grimus e, in alcuni casi, la traduzione tedesca del romanzo.[7] Infine durante la traduzione ci si è rivolti ad alcuni esperti consultati, ad esempio, su questioni inerenti la mitologia islamica.
Le concordanze parallele sono state consultate attraverso due strumenti distinti: in primo luogo attraverso la funzione Concordance del software Trados Translator's Workbench, e secondariamente attraverso il programma Concord presente nel pacchetto software Wordsmith Tools. Nel primo caso il corpus parallelo allineato su cui vengono effettuate le concordanze è in formato Trados Translator's Workbench Memory, nel secondo si presenta invece come un insieme di sei testi bilingui in formato solo testo. Entrambi questi prodotti sono stati creati per mezzo del programma di allineamento Trados WinAlign, come descritto in allineamento del CPR.
Trados Translator's Workbench è un prodotto commerciale sviluppato appositamente per i traduttori tecnici professionisti, una “stazione di lavoro per il traduttore” che agisce come interfaccia tra un programma esterno di videoscrittura, in cui viene prodotta la traduzione sostituendo a segmenti del testo di partenza segmenti del testo di arrivo, e che può includere, oltre alla memoria traduttiva, una banca dati terminologica e un sistema di traduzione automatica. Le memorie traduttive sono particolarmente utili nella creazione di banche dati terminologiche e nella traduzione di materiale tecnico e informativo. Esse consentono infatti di aumentare la produttività in presenza di testi ripetitivi, come spesso sono molti testi tecnici/informativi (come i manuali di istruzioni) in quanto sono in grado di richiamare sullo schermo la traduzione di frammenti di testo uguali o molto simili ad altri già tradotti. Una memoria traduttiva può essere costituita attraverso l'utilizzo progressivo di una stazione di lavoro come Trados Translator's Workbench e l'archiviazione dal materiale testuale bilingue che viene accumulato mano a mano che vengono portate a termine delle traduzioni, oppure può essere creata importando all’interno di una nuova memoria un file di testo contenente un corpus parallelo allineato, come nel caso del CPR.[8]
Una prova inizialmente effettuata sulle prime pagine di Grimus ha confermato l'ipotesi che nella traduzione di un testo letterario di questo tipo le potenzialità di una stazione di lavoro per traduttori (translator's workbench) non trovino completa espressione, in quanto funzionali alla standardizzazione piuttosto che alla creatività linguistica. Tuttavia, la funzionalità Concordance presente all'interno del programma, che permette di visualizzare tutti i segmenti traduttivi in cui compare una "parola", alternati alle rispettive traduzioni, è risultata particolarmente utile come supporto per la traduzione. Una volta avviato, il programma rimane attivo nello sfondo, e la memoria traduttiva può essere consultata interattivamente durante la traduzione effettuata con un programma di videoscrittura. La figura che segue mostra come appare sullo schermo del computer una concordanza ottenuta con la funzionalità presente all'interno della stazione di lavoro.
Trados Translator's Workbench,
output della funzionalità
Concordance
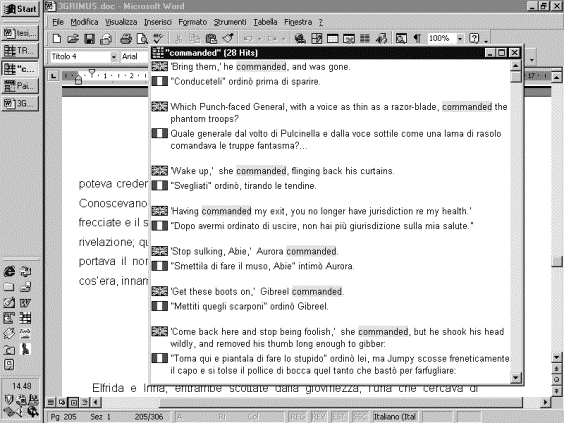
L'apparizione della finestra di concordanze sullo schermo è quasi immediata, ma una notevole limitazione è rappresentata dal fatto che la possibilità di manipolare l'output è ristretta: l'ordine in cui vengono presentate le concordanze è determinato dal programma ed è possibile effettuare una ricerca solo per precise "parole" singole.[9]
Il programma di concordanze incluso in Wordsmith Tools permette invece di visualizzare la parola (o le parole) cercata al centro di una riga di contesto, interrogando uno o più files in formato solo testo. Nel caso di files bilingui ottenuti come risultato dell'allineamento di un testo con la sua traduzione, la visione dei segmenti in entrambe le lingue avviene ampliando il contesto di visualizzazione di ciascuna riga di concordanza. La figura che segue mostra come appare sullo schermo una concordanza parallela generata da Wordsmith Tools.

Wordsmith Tools, output della componente Concord
L'appartenenza del testo a una lingua o all'altra non viene in alcun modo evidenziata, e il programma non distingue confini di frase, proponendo contesti bilingui sempre più ampi in cui originali e traduzioni si alternano indiscriminatamente così come nel testo contenuto nel file bilingue su cui si svolge la ricerca.[10] Wordsmith Tools permette però di effettuare ricerche più flessibili, ad esempio ricercare contemporaneamente più parole, utilizzare caratteri jolly per individuare delle "espressioni regolari"[11] e identificare contesti definiti dalla co-occorrenza di due o più parole o espressioni regolari. Anche l'output può essere inoltre manipolato ordinando le concordanze ottenute in base a diversi criteri, ad esempio l'ordinamento alfabetico della/e parola/e chiave. Risultati ottimali si ottengono quindi alternando l'utilizzo dei due strumenti: la funzione Concordance di Trados Workbench e la memoria traduttiva permettono una migliore e più rapida visualizzazione delle concordanze parallele, mentre Wordsmith Concord ha maggiori potenzialità per analisi che richiedano manipolazioni più raffinate, ad esempio l'ordinamento delle concordanze in base alle parole di contesto o l'interrogazione del corpus a partire da contesti allargati.
La memoria traduttiva non costituisce una risorsa esaustiva dal punto di vista lessicale, dato che non tutte le parole presenti in Grimus sono contenute nel database, ma ha, rispetto ad altre risorse bilingui come dizionari generali o corpora di riferimento (peraltro non esistenti per l'italiano), il vantaggio di una maggiore selettività, dato che le concordanze bilingui offrono un rapido accesso ad equivalenze stabilite da altri traduttori in contesti d'uso spesso molto simili e che numerose sono le parole nel testo di Grimus che compaiono anche nelle opere successive. Questo significa anche che durante la traduzione è più veloce consultare una concordanza dalla memoria traduttiva che cercare la pagina del dizionario bilingue che contiene quella parola.
Una fondamentale distinzione tra l'uso di un dizionario bilingue e di un corpus parallelo è inoltre il fatto che mentre nel primo è necessario compiere un passaggio di astrazione, ricavando la "forma base", il lemma, passando da "come si traduce questa forma di parola" a "come si traduce questo lemma", la ricerca di "parole" in un corpus procede sempre da forme, o "espressioni regolari", e spetta a chi consulta il corpus decidere quali generalizzazioni trarre dalle diverse conformazioni ricorrenti in una concordanza.[12]
Una qualsiasi voce di un dizionario bilingue presenta normalmente per ciascun termine in L1 una serie di “equivalenti” in L2 ponendoli in un rapporto pressoché sinonimico (un elenco separato da virgole, presumibilmente in ordine discendente di salienza) e/o distinguendo tra equivalenti con sensi diversi nel caso di termini polisemici. In un corpus parallelo è possibile manipolare i dati (le righe di concordanza) in modo da raggruppare diverse categorie di traducenti per uno stesso termine, individuando eventuali costanti contestuali in L1 che rendano conto della ricorrenza di determinate scelte traduttive.
Ad esempio, la ricerca di chiarificazioni sulla parola “commanded”, se condotta sul dizionario, implica la sua scomposizione morfologica nella radice “command” e nel suffisso “-ed”, dato che un dizionario normalmente registra unicamente le forme cosiddette di base. Si tratta spesso di un procedimento sufficientemente elementare, che porta a identificare rapidamente la forma di base, distinguendo tra la voce “sostantivo” e la voce “verbo”, e ricostruendo successivamente un equivalente del verbo flesso in italiano. In altre parole, la forma della parola viene analizzata, ridotta alla forma base, e a partire da questa viene poi sintetizzata una traduzione. Il dizionario Inglese-Italiano Garzanti, ad esempio, riporta per il verbo "command" quanto segue: "V. tr. 1. Comandare, ordinare 2. Controllare, dominare (anche fig.) The castle commands a view over the valley (Il castello domina la vallata). V. intr. Comandare, esercitare il comando." Il dizionario Sansoni è più esteso ed elenca otto sensi come verbo transitivo (altri verbi proposti sono pretendere, disporre, esigere) e tre sensi come verbo intransitivo, fornendo un maggior numero di esempi ma sostanzialmente non allargando di molto le proposte di “equivalenti” lessicali del Garzanti.
La ricerca sul corpus parallelo parte invece dalla forma della parola, selezionando in prima istanza solamente le occorrenze della forma cercata, in questo caso “commanded”. La ricerca può invero avvenire attraverso l’uso delle cosiddette “espressioni regolari”, cioè stringhe di caratteri che contengono elementi “aperti” o caratteri jolly: ad esempio la stringa “command*” in cui l’asterisco indichi qualsiasi sequenza di caratteri, porta alla selezione delle forme “command”, “commands”, “commanded” e “commanding”, nonché “commander”, “commandment” ecc. (se presenti nel corpus). In ogni caso la ricerca procede non dall’individuazione di una forma base, ma dall’esplorazione di una serie di realizzazioni contestuali di precise forme. È infatti attraverso l’interpretazione dei dati che si potrà comprendere il significato delle forme di parola e delle somiglianze e differenze tra termini o contesti correlati. Tale analisi sarà da un lato meno comprensiva, essendo ristretta al particolare gruppo di testi che costituiscono il corpus parallelo, e più dispersiva, richiedendo un maggiore sforzo di sintesi per rintracciare delle regolarità all’interno delle diverse occorrenze, ma dall’altro lato consentirà un livello di analisi più profondo di quanto possa consentire una voce, necessariamente sintetica, di un dizionario bilingue, permettendo di distinguere tra eventuali sensi diversi, e quindi diverse traduzioni, in associazione con forme di parola diverse.
Una concordanza di “commanded” nel Corpus Parallelo Rushdie fornisce, ad esempio, 27 citazioni. Di queste 21 sono tradotte con forme del verbo “ordinare”, 3 con forme del verbo “intimare”, 2 con forme del verbo “comandare” e infine 1 (n. 27, “as he commanded”) ricorrendo alla formulazione “obbedendo alle sue istruzioni).[13]
Il corpus parallelo è stato consultato principalmente a partire dall'inglese, per verificare come è stata tradotta in altri romanzi dello stesso autore una determinata parola o espressione. Il corpus parallelo si è rivelato particolarmente utile nei casi in cui le informazioni ricavate dai dizionari fossero insufficienti, contraddittorie o poco contestualizzate. Non sempre si è agito in conformità con quanto "suggerito" dai ritrovamenti nel corpus parallelo, così come non sempre soluzioni suggerite da dizionari o altre fonti sono state adottate.
La traduzione di Grimus ha evidenziato come per alcuni problemi di traduzione legati a caratteristiche linguistiche un corpus parallelo allineato sia uno strumento complementare a un dizionario bilingue. Ad esempio, uno dei punti problematici è risultato essere quello relativo alla traduzione di verbi di "dire" (speak, tell, say) modificati da un avverbio di modo, oppure di verbi che introducono o commentano un discorso diretto indicando un movimento o un atteggiamento fisico piuttosto che un'espressione verbale (shrug, pout). Il corpus parallelo ha cioè il vantaggio, rispetto a un dizionario bilingue, di fornire traduzioni di contesti discorsivi piuttosto che di semplici elementi lessicali.
Alcuni "aspetti problematici" emersi durante la traduzione e legati non solamente a relazioni di equivalenza lessicale ma anche a scelte traduttive di carattere più generale, sono stati utilizzati come punto di partenza per l'analisi qualitativa delle concordanze parallele descritta in analisi quantitative.