3.3 Strumenti CAT/TM
3.3.1 OmegaT
| Autori: | K. Godfrey, M. Prior, D. Briel, H. Pijffers et al. |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://www.omegat.org |
| Versione: | 2.2.3 (gennaio 2011) |
OmegaT è uno dei programmi di traduzione assistita più diffusi nell'ambito del SL. L'applicazione è scritta in Java e, in quanto tale, può essere eseguita su qualsiasi architettura e su qualsiasi sistema operativo a condizione che sia installato il JRE.
Per questioni di licenza, la gran parte delle distribuzioni GNU/Linux adotta OpenJDK come piattaforma Java, tendendo a includere nei propri archivi il rilascio stabile di OmegaT (2.0.5) o addirittura versioni ancora precedenti (es. 1.8.1.2),65 pienamente compatibile con tale implementazione.
Questa versione, seppur molto affidabile e adatta alla maggior parte delle situazioni, manca di alcune delle funzionalità più interessanti introdotte di recente dal gruppo di sviluppatori (la compatibilità con TBX, l'analisi on demand delle TM, le statistiche di progetto sensibili alla possibilità di leverage da TM, ecc.) e non è compatibile con i plug-in più recenti (il supporto ai dizionari, i tokenizer e il pacchetto language-tool).
Per tutte queste ragioni si è ritenuto opportuno basare la presente trattazione del programma sull'ultima versione disponibile, che è possibile scaricare dalla pagina del progetto corredata dal Java SE 6 Runtime Environment di Oracle,66 anche se una simile scelta non può essere considerata del tutto ‘ortodossa’ rispetto alla filosofia del SL. Volendo distinguere la piattaforma di base (il JRE) dalla sua implementazione, il codice di OmegaT resta rilasciato sotto licenza GPL, il che tutela ugualmente la libertà dell'utente e ne permette l'utilizzo per qualsiasi scopo (anche professionale), la modifica e la redistribuzione nei termini previsti dalla licenza (cfr. sez. 2.2.1).
Il programma è in grado di elaborare correttamente e senza bisogno di intermediazione di software di terze parti sia documenti dal contenuto puramente testuale, senza informazioni sulla formattazione, sia documenti di testo formattato, in cui il materiale testuale è accompagnato da informazioni di formattazione sotto forma di tag o altri elementi di markup [Helary et al., 2010].67 Esempi di file supportati da OmegaT sono: documenti testo semplice (es. .txt), DTD e .properties Java, file INI, documenti (X)HTML e HTML, HTML compilato (tipico delle guide in linea), ODF e tutti i formati compatibili con OpenOffice.org, file PO, DocBook, Microsoft OpenXML, contenuti QuarkXPress esportati con CopyFlow Gold, documenti XLIFF, sottotitoli SRT di SubRip, file di risorse RC, ResX e di Android, LaTeX, contenuti web esportati attraverso Typo3 LocManager o nativi, nel caso di DokuWiki. A partire dalla versione 2.2.3 è stato aggiunto anche il supporto ai TTX bilingui del vecchio formato di SDL-Trados, che prima per essere letto richiedeva il ricorso a plug-in esterni o applicazioni di terze parti.68
L'unità di lavoro di base sui cui è incentrato il programma non è il file singolo quanto piuttosto il ‘progetto’. Un progetto può contenere al proprio interno uno o più file dei formati elencati in precedenza, anche organizzati in un albero di directory con diversi livelli di profondità.
I progetti di OmegaT sono entità virutali: vengono visti dal programma come elementi indivisibili ai fini dell'apertura e del salvataggio ma ad un livello di astrazione immediatamente inferiore si presentano come una serie di directory e di file accessibili con qualsiasi gestore di file tramite interfaccia grafica o da riga di comando più un documento XML, chiamato omegat.project, che contiene i metadati di progetto.
Questi sono essenzialmente dei riferimenti alle sottodirectory di progetto, che possono in realtà trovarsi in una qualsiasi posizione del file system in cui l'utente corrente abbia privilegi di accesso in scrittura, più una serie di impostazioni, come le lingue di lavoro (rappresentate dai rispettivi codici ISO identificatori). Fanno parte del progetto anche impostazioni come le regole di segmentazione (sulla base dell'unità frase o paragrafo), che è possibile modificare anche in un secondo momento.
Tutte le informazioni sono registrate nel file omegat.project e tutte le operazioni che comportano la modifica di tale file comportano che il progetto sia ricaricato. Pertanto i successivi cambiamenti alle lingue di partenza e di arrivo, alla segmentazione, alla posizione di una delle cartelle di progetto così come l'eventuale aggiunta o l'eliminazione di file di partenza, richiedono la riapertura del progetto affinché possano essere caricate le nuove impostazioni.
Chiaramente, esiste anche una serie di impostazioni ‘globali’ che riguardano il trattamento dei file di partenza a livello di programma, più che di singolo progetto. La segmentazione, ad esempio, che a livello di progetto può essere basata sulla frase o sul paragrafo, può essere personalizzata in maniera molto flessibile anche a un livello superiore, vale a dire, stabilendo i delimitatori delle unità concettuali. OmegaT, pur non supportando nativamente lo standard SRX, prevede un meccanismo molto potente e flessibile di impostare le regole di segmentazione attraverso espressioni regolari SRX-like.
Le regole possono essere organizzate in ‘gruppi’, corrispondenti in via approssimata agli schemi linguistici (per locale). A ciascun gruppo è associato un criterio, sotto forma di espressione regolare, che stabilisce i casi di applicazione in base allo schema linguistico del testo di partenza, ad esempio, EN.* vale per tutti i testi in inglese, IT-CH per i testi in italiano (Svizzera) e così via.
Quando più criteri sono soddisfatti allo stesso tempo le corrispondenti regole vengono applicate nell'ordine in cui compaiono nella lista (modificabile a piacere), in fondo alla quale si trovano le regole di segmentazione generali (criterio .*): quelle predefinite, per i file di testo e per i documenti (X)HTML e ODF.69
Creare nuove regole di segmentazione non è difficile e per capire il funzionamento è sufficiente osservare quelle preesistenti. Ogni regola è formata da un campo Modello prima che contiene la definizione di quanto precede l'eventuale interruzione di segmento, da un campo Modello dopo con la definizione di quanto segue, più una casella di spunta Interruzione/Eccezione che, se abilitata, provoca l'interruzione e, se disabilitata, blocca il controllo delle regole successive. Consideriamo, ad esempio, le regole predefinite:
 |
La prima regola prevede che la presenza di tre caratteri di punto consecutivi seguiti da uno o più caratteri di spaziatura, a loro volta seguiti da qualsiasi carattere che non sia una lettera maiuscola, non comporti un'interruzione dopo i tre punti come vorrebbe la terza regola (si tratta infatti di un'eccezione).
La seconda regola, invece, prevede che un eventuale numero arbitrario di caratteri di spaziatura a inizio di riga, seguiti un punto o una cifra decimale (eventualmente in sequenza), da un numero qualsiasi di caratteri di spaziatura e da una lettera maiuscola, comporti un'interruzione di segmento prima della maiuscola.
La terza regola, infine, implica che dopo uno o più punti fermi, punti interrogativi o esclamativi seguiti da un carattere di spaziatura provochino l'interruzione di segmento.70
Questo approccio alla segmentazione ha l'indubbio vantaggio di essere altamente personalizzabile in base alle esigenze dell'utente e facile da modificare, correggere o integrare in un secondo momento in base alla necessità. Per contro, lo svantaggio implicito è che non è direttamente compatibile con lo standard SRX anche se molto simile ad esso nel contenuto.
Questo può rappresentare un ostacolo alla portabilità fra strumenti CAT, allo scambio di queste regole fra colleghi o fra il cliente e il traduttore, aspetto da non sottovalutare dato che al variare dei confini e del numero di segmenti varia anche la qualità e la quantità di corrispondenze in TM.71
La directory source posizionata nella radice del progetto contiene i file di partenza (anche organizzati ricorsivamente in sottodirectory), parimenti target contiene la medesima struttura e gli stessi file, i cui contenuti sono però tradotti e vengono creati solo nel momento in cui l'utente compila i documenti d'arrivo al termine del lavoro.
La gestione dei file di partenza e di arrivo e la politica per i nomi da assegnare a questi ultimi è affidata ai filtri associati a ogni tipo di file. I filtri sono responsabili della lettura e dell'estrazione del contenuto traducibile dal file di partenza, nonché della sostituzione del contenuto tradotto nei documenti di arrivo. Disabilitando un filtro per un determinato progetto, ad esempio, tutti i file del relativo formato non saranno considerati da OmegaT e nella sottodirectory d'arrivo saranno posizionate delle copie identiche al sorgente.
Alcuni filtri presentano speciali opzioni accanto a quelle predefinite sulla codifica e sul nome del file tradotto. Nei documenti (X)HTML, ad esempio, è possibile tradurre o non tradurre i valori di determinati attributi (come la destinazione dei collegamenti ipertestuali o la posizione delle immagini), considerare o meno l'elemento <br>/ come un'interruzione di paragrafo e specificare tramite espressioni regolari ulteriori porzioni di testo che eventualmente non devono essere tradotte.
Nei documenti ODF è possibile scegliere attraverso il filtro se tradurre le note, i commenti, i segnalibri e i riferimenti a segnalibri, le voci di indice, le note delle presentazioni e la destinazione dei collegamenti. In modo analogo, nei documenti in formato OpenXML di MSOffice è possibile scegliere se tradurre o meno le testatine e i piè di pagina, i commenti, le note a piè pagina e di chiusura, i nomi dei fogli di MSExcel, i commenti diapositiva di MSPowerPoint, e via dicendo. Le impostazioni dei filtri sono, in ogni caso, potenti e molto complesse e si rimanda alla documentazione ufficiale per approfondimenti.
Il fatto che in source sia possibile inserire i file anche su più livelli di annidamento di directory permette una facile gestione anche dei progetti che hanno una struttura complessa: tutti i file compatibili per la traduzione saranno caricati nel progetto, ognuno sarà pretrattato in base al filtro per lo specifico tipo di file e a tutti saranno applicate le regole di segmentazione nel medesimo ordine.
La struttura predefinita dei progetti prevede, oltre a quella dei file di partenza e di arrivo, la presenza di tre ulteriori sottodirectory: una per le TM in consultazione, una per i glossari dell'utente e, infine, una cartella per i dizionari off-line che l'utente desideri utilizzare.
OmegaT utilizza nativamente i TMX come formato per la memorizzazione dei progetti, così come per i salvataggi intermedi, caratteristica che lo rende adatto per la revisione e la condivisione del lavoro fra più traduttori in uno stesso progetto. A seconda della posizione che occupano nella directory di progetto, le TM vengono aperte in sola scrittura, in lettura/scrittura oppure in sola lettura (consultazione).
In primo luogo, tre TM sono contenute nella directory radice del progetto e vengono create o, se già presenti, aggiornate a ogni compilazione dei file di arrivo. Si tratta delle TM ‘finali’, che contengono i segmenti di partenza e quelli di arrivo corrispondenti al contenuto delle directory source e target al momento della creazione di quest'ultima, cioè alla compilazione dei documenti d'arrivo.
Per la precisione, queste TM sono: $projname-level1.tmx, contenente le informazioni di tipo puramente testuale, level2.tmx, che presenta le informazioni di formattazione72 e, infine, omegat.tmx contenente i tag di formattazione specifici di OmegaT, che permette di utilizzare il file in altri progetti realizzati con questo programma.
Queste memorie, che vengono soltanto scritte, permettono il riutilizzo delle TU prodotte in fase di traduzione per altri progetti futuri garantendo il massimo della compatibilità: tanto lavorando con OmegaT (omegat.txt), quanto con un generico strumento CAT che supporti il TMX di livello 2 ma, in alternativa, con il testo senza formattazione del livello 1 nel caso in cui il livello 2 non sia supportato dallo strumento prescelto.
Le TMX in sola lettura sono contenute all'interno della directory tmx. L'utente è libero di copiare in questa posizione i file che desidera utilizzare in consultazione per il progetto o, in alternativa, è possibile utilizzare un'unica directory con le TM in uso comune a tutti i progetti. In ogni caso, è possibile utilizzare un numero arbitrario di file TMX all'unica condizione che si tratti di documenti validi.73 Questa caratteristica di OmegaT è molto utile e non comporta sensibili rallentamento nell'utilizzo del programma anche se si utilizzano più TM contemporaneamente e inoltre, invece di file singoli, è possibile inserire nella posizione di consultazione anche un albero di directory con più ramificazioni.
Nelle versioni più recenti del programma, a partire dalla versione 2.0.0, è stata introdotta un'ulteriore caratteristica di ottimizzazione nella gestione delle memorie, la cosiddetta analisi on demand delle TM, che non vengono più caricate in maniera statica all'inizio del progetto (il che generava un rallentamento non indifferente del programma ad ogni apertura del progetto) ma dinamicamente solo quando ne è richiesto l'utilizzo.
I progetti contengono anche una sottodirectory chiamata omegat. A differenza di quanto visto in precedenza, si tratta di una locazione con accesso in lettura e scrittura, in cui vengono salvate le TM nel corso della traduzione. In questa directory è contenuto il file project_save.tmx, in cui sono memorizzate tutte le modifiche alla TM apportate a partire dall'inizio del lavoro, aggiornandole a ogni salvataggio del progetto. In questa cartella compare anche una serie di copie di sicurezza dello stesso, una per ogni volta che il progetto è stato aperto o ricaricato, prima dell'inizio della nuova sessione di lavoro, in modo da minimizzare il rischio di perdita di dati.
Dal momento che il file project_save.tmx contiene tutte le TU modificate, può accadere che, se si modifica ala segmentazione, o se per qualche motivo il testo di partenza dovesse subire dei cambiamenti, le nuove TU saranno salvate accanto a quelle vecchie, che rimarranno comunque salvate. Tutte le TU presenti in questa TM per cui non sia più possibile ritrovare il segmento di partenza nel testo del progetto corrente verranno sottoposte all'utente come corrispondenze parziali, con la denominazione di ‘stringhe orfane’.
Un simile comportamento permette di non perdere il lavoro svolto in precedenza o, in alternativa, di rendersi conto di eventuali errori e ripristinare la condizione anteriore. Come si vedrà più avanti, project_save.tmx è la memoria di traduzione su cui si basa la compilazione dei file di arrivo e la creazione delle TM finali.
La directory contiene inoltre alcuni documenti contenenti informazioni statistiche. Il primo, project_stats.txt, riporta un conteggio del numero di segmenti, parole e caratteri (spazi inclusi ed esclusi) del progetto totali e non tradotti (assoluti) o totali e da tradurre (senza ripetizioni). Questi dati sono poi riproposti per ogni singolo file del progetto sulla base dei soli segmenti. Le informazioni possono essere visualizzate anche all'interno del programma dal menu Strumenti/Statistiche e, in forma più sintetica dalla finestra di riepilogo sui file di progetto Progetto/File del progetto.
Un secondo file, project_stats_match.txt contiene le statistiche basate sulle TM di progetto, con il numero di segmenti, parole e caratteri suddivisi in base alle ripetizioni, alle corrispondenze esatte, alle corrispondenze parziali distinguendo le percentuali e all'assenza di corrispondenza. Queste informazioni, in modo simile alle statistiche generali, sono accessibili dall'interno del programma dal menu Strumenti/Corrispondenza statistiche e permettono di valutare in modo efficiente all'inizio di un nuovo progetto l'entità del lavoro da fare.
Infine, nella directory omegat possono essere salvati anche i file ignored_words.txt e learned_words.txt utilizzati per la correzione ortografica.
Per tutte le TM utilizzate dal programma, sia quelle in sola lettura che quelle in lettura/scrittura, viene adottata una politica molto rigida. Se i file contengono errori, ad esempio, se non rispettano la struttura TMX, non sono documenti XML validi o quant'altro, non sarà possibile processarli. Casi del genere, purtroppo, non sono così infrequenti, dal momento che molti strumenti CAT liberi o non liberi producono TMX non validi (ad es. Lokalize, cfr. 3.3.4).
In una simile eventualità, OmegaT genera dei messaggi di errore e lascia all'utente il compito di provvedere alle correzioni. Fortunatamente, la diagnosi dei problemi può essere realizzata con uno dei tanti validatori disponibili, trattati con maggiori dettagli nella sez. 4.3.
L'approccio di OmegaT alle TM ha numerosi vantaggi: in primo luogo, lo standard TMX è utilizzato nativamente, e questo garantisce la massima portabilità con il minimo sforzo, dal momento che non si richiede né l'importazione né procedure di conversione inclini agli errori.
Un altro aspetto molto positivo è la facilità data dall'avere una cartella per le TM utente nel riutilizzare le risorse create in progetti precedenti o realizzate dai propri colleghi senza bisogno dell'importazione e quindi di ‘sporcare’ la memoria di lavoro (salvata, invece, nella directory radice del progetto al momento della compilazione dei documenti d'arrivo). Infine, l'utilizzo del TMX anche per salvare le modifiche alla TM rende molto semplice il recupero dei dati a seguito di errori (umani e non).
Come si è già avuto modo di osservare, tuttavia, questo porta anche ad inevitabili svantaggi come la creazione di molte TM di dimensioni relativamente ‘piccole’ e contenenti fra loro segmenti duplicati, dato che le corrispondenze esatte vengono infatti comunque inserite nella TM di lavoro indipendentemente dal fatto che la TU fosse già presente in una delle TM utente. Per ovviare a questo inconveniente, gli stessi sviluppatori di OmegaT hanno dato vita a strumenti di pulizia e di manipolazione delle TM citati, i più significativi dei quali saranno considerati nella sez. 4.3.
La cartella glossary presente nella radice del progetto può contenere un numero arbitrario di risorse terminologiche (anche organizzate in una directory). OmegaT utilizza in modo predefinito file TSB con estensione .tab (codifica ASCII), .utf8 (Unicode) o semplicemente .txt.74 I documenti di questo tipo contengono tre colonne separate da caratteri di tabulazione, in cui la prima corrisponde ai termini in lingua di partenza, la seconda ai termini in lingua d'arrivo e la terza ai commenti del redattore. A partire dalla versione 2.1.4 il supporto è stato esteso allo standard TBX, anche se non tutti i campi sono letti e visualizzati.
In particolare, in questo tipo di file, viene ricreata una struttura simile alle tre colonne dei glossari ‘tradizionali’ di OmegaT, in cui le meta-categorie <termNote> e <descrip> (cfr. appendice A.2) sono impiegate per ricreare il campo dei commenti o per la definizione. Il contenuto di questi elementi viene visualizzato in ogni caso come un commento, preceduto da un'etichetta (es. definition:) che specifica la categoria di dati e corrisponde quindi all'attributo contenuto nel TBX.
Se il TBX contiene un termine con sinonimi, il programma non visualizza comunque l'intera scheda terminologica e si comporta in modo leggermente diverso a seconda che questi ultimi appartengano alla lingua di partenza o alla lingua di arrivo. Nel primo caso, infatti, verrà visualizzata all'utente solo la parola presente nel testo di partenza senza gli eventuali altri sinonimi, la cui utilità in fase di traduzione è effettivamente relativa; nel secondo caso invece vengono proposte tutte le alternative presenti nel TB, separate da una virgola. L'effetto è lo stesso che si otterrebbe in un documento TSV tradizionale ripetendo su più righe lo stesso termine in lingua di partenza.
Di recente, a partire dalla versione 2.2.2, è stata inserita nel programma una semplice interfaccia per la creazione di nuove voci terminologiche dall'interno del programma, accessibile con una scorciatoia da tastiera. In tutte le versioni precedenti era necessario modificare ‘a mano’ il glossario con un editor di testo separato. Le aggiunte vengono riportate in un file che ha il nome $projname-glossary.txt (dove $projname corrisponde al nome del progetto corrente), che è considerato il glossario principale.
La modifica con un programma a parte rimane, invece, l'unica soluzione valida se si stanno utilizzando più glossari allo stesso tempo e si vuole intervenire su uno diverso da quello principale. Inoltre, a partire dalla versione 2.0.3 i glossari vengono ricaricati a intervalli di un secondo, in modo che le modifiche apportate al glossario possano essere incorporate nel progetto senza bisogno di ricaricarlo ogni volta.
Se per le TM OmegaT ha il vantaggio di lavorare nativamente sul formato standard, per i glossari non è possibile dire altrettanto. I TBX possono essere letti, seppur in modo parziale, dal programma mentre non è previsto in alcun modo che vengano scritti, né tanto meno esiste la possibilità di convertire facilmente dai formati specifici di OmegaT allo standard TBX.
Relativamente ai glossari, le versioni 2.x sono dotate di un'ulteriore importante caratteristica: attraverso l'uso dell'estensione tokenizer è possibile, infatti, rilevare anche le corrispondenze parziali sulle voci di glossario. Caricando l'estensione adeguata alla lingua di partenza, si avrà un ‘hit’ nel glossario anche se l'espressione presente nel testo è una forma flessa, perché il tokenizer è in grado di riconoscere la radice (stemming) delle parole e considerare solo quella i fini delle corrispondenze.75
Da una parte, quindi, sono stati fatti consistenti passi avanti, con l'introduzione della possibilità di inserimento facilitato delle nuove voci di glossario (basta selezionare l'espressione nel testo di partenza, premere Ctrl-Maiusc-G e digitare il termine in lingua d'arrivo) oppure la lettura delle modifiche senza bisogno di ricaricare il progetto, dall'altra però resta però ancora del lavoro da fare su questo fronte, come ad esempio migliorare il supporto allo standard TBX o consentire modifiche interattive al TB che vadano oltre la sola creazione di schede termine-termine.
OmegaT supporta anche il ricorso a dizionari off-line i cui lemmi, nel caso in cui sia riscontrata una corrispondenza con le espressioni presenti nel segmento in traduzione, saranno presentati all'utente durante il corso del lavoro. Sono supportati i dizionari nel formato tipico della piattaforma StarDict ed è possibile utilizzare dizionari mono- e bilingui.76
Per poter utilizzare i dizionari, questi devono essere inseriti nella cartella dictionary nella radice del progetto. Anche in questo caso, vengono considerati tutti i file compatibili presenti nella sottodirectory (si ricorda che i dizionari StarDict sono composti da almeno tre file, .dic.dz, .idx e .ifo) ed è possibile utilizzarne più di uno al medesimo tempo, a seconda delle proprie esigenze. L'utilizzo dei dizionari è molto semplice, anche se potrebbe rendersi necessario apportare delle piccole modifiche al file .ifo per la consultazione (in ogni caso, la documentazione ufficiale è ricca di informazioni).
Non esiste invece alcun modo per attivare o disattivare facilmente un dizionario, che deve quindi essere spostato o cancellato dalla sottodirectory dictionary. Questo rende di fatto scomodo tentare di utilizzare un'unica posizione per tutti i dizionari, incoraggiando a copiare di volta in volta i file (o le directory) dei dizionari desiderati all'interno di ogni progetto.
In linea di principio, il meccanismo del salvataggio di progetto rende molto facile ripristinare i dati in caso di imprevisti: è sufficiente chiudere il progetto, rinominare il file project_save.tmx che si considera corrotto e attribuire questa precisa denominazione a una delle copie di sicurezza presenti nella directory. Alla riapertura del progetto, se la procedura è andata a buon fine, dovrebbe essersi ripristinata la situazione voluta. Per approfondimenti in merito, si rimanda all'esaustiva documentazione del programma e, in particolare, alla sezione «Come evitare la perdita di dati».
In generale, la struttura dei progetti qui brevemente discussa ha il vantaggio che, se tutti i file di progetto — comprese le TM in consultazione, i glossari e i dizionari — sono in una sottodirectory della radice del progetto, i progetti possono essere scambiati fra collaboratori con grande facilità senza perdita di dati. È possibile, ad esempio, creare un archivio (tarball) avvalendosi se si vuole di uno degli strumenti di compressione tipi dei sistemi GNU/Linux e inviare il progetto a un'altra persona.
Un altro aspetto in cui la struttura dei progetti si rivela molto utile è la revisione, che può essere fatta rinominando spostando nella directory tm la TM del traduttore (project_save.tmx) o una delle TM finali, se sono stati già creati i file d'arrivo, e procedendo segmento per segmento alla rilettura e correzione della traduzione.
L'interfaccia grafica, realizzata tramite il toolkit Swing di Java e completamente localizzata in oltre venti lingue fra cui anche l'italiano, è suddivisa in tre aree principali: l'editor, le corrispondenze parziali estratte dalla TM e il glossario. A queste è possibile aggiungere una sezione per i dizionari e una per la traduzione automatica, e tutte le aree possono essere, minimizzate, ridimensionate a piacere, spostate o addirittura staccate dall'area principale per trasformarsi in finestre ‘fluttuanti’, garantendo così la massima flessibilità in base alle esigenze dell'utente.
La GUI è completata da una barra dei menu che permette di accedere alle funzionalità, alle impostazioni di programma e di progetto nonché da una barra di stato in basso affiancata da un riepilogo delle statistiche in cui, oltre al numero di segmenti tradotti e totali del file in elaborazione, i segmenti tradotti e il numero totale di segmenti senza ripetizioni del progetto e il numero di segmenti totale (assoluto) del progetto, viene visualizzato anche il numero di caratteri del segmento di partenza e il numero di caratteri attualmente utilizzati per la traduzione (utile nel caso in cui si abbia a disposizione uno spazio limitato per il proprio lavoro).
Il primo passo per utilizzare OmegaT consiste nella creazione un nuovo progetto, che comporta l'inserimento di tutte le impostazioni enumerate in precedenza in una finestra di dialogo. Va ricordato, tuttavia, che tutte le scelte operate in fase di creazione, ivi comprese le regole di segmentazione SRX-like, possono essere modificate dal menu Progetto/Proprietà (che comporterà la riapertura del progetto). Poiché nella maggior parte dei casi, la cartella specificata per i file sorgente sarà vuota, essendo la sottodirectory source nella radice del progetto, è necessario caricare i file di partenza.
Questo può essere fatto copiando i file o le cartelle contenenti i file da tradurre nella sottodirectory source del progetto o, in alternativa, dalla finestra di dialogo File del progetto, da cui i file possono essere selezionati da un browser tradizionale. Anche in questo caso, a un progetto possono essere aggiunti in qualsiasi momento nuovi file con una delle due procedure descritte.77 Al termine di questa seconda fase, il testo di partenza verrà ‘segmentato’ e a tutti i segmenti presenti sarà assegnato un numero identificativo.
La traduzione vera e propria è imperniata sull'area dell'editor presente all'interno della finestra principale del programma. L'aspetto di quest'area della finestra può essere personalizzato con le funzionalità presenti nel menu Vista. Ad esempio, possono essere evidenziati con colori diversi testo sorgente dei segmenti non tradotti e/o il testo d'arrivo dei segmenti tradotti. Oppure, è possibile visualizzare, per i segmenti tradotti, sia il testo sorgente che il testo d'arrivo (di norma OmegaT mostra solo il testo d'arrivo, in modo da dare una ‘visione d'insieme’ al traduttore). Infine, è possibile mostrare l'autore, la data e l'ora dell'ultima modifica per tutte le TU, per quella ‘aperta’ in modifica o per nessuna (predefinito).
Durante la fase di traduzione interattiva il segmento sorgente è protetto dalle accidentali modifiche da parte dell'utente, a cui è concesso di intervenire solo inserendo la propria traduzione nel campo di testo successivo, chiamato d'ora in avanti ‘campo di modifica’ (in accordo con la maggior parte della documentazione del programma).
Come impostazione predefinita, il campo di modifica contiene una copia del testo di partenza o, nel caso in cui sia stata riconosciuta una corrispondenza in memoria superiore o uguale alla soglia di match specificata, il contenuto della TM (eventualmente preceduto dal prefisso [fuzzy] nel caso in cui si tratti di una corrispondenza non totale).
Tali impostazioni possono essere modificate dal menu Opzioni/Comportamento di modifica, ad esempio, stabilendo che un segmento appena inizializzato (cioè ‘aperto’ per la modifica) sia vuoto piuttosto che contenere una copia dell'originale.
In questa stessa finestra di dialogo è possibile anche impostare la soglia di match minima perché il contenuto della memoria venga inserito nel segmento inizializzato e la possibilità che il segmento di partenza e di destinazione siano identici.
Nella situazione predefinita tale impostazione è disattivata e OmegaT continuerà a considerare ‘non tradotti’ i segmenti in cui il testo di partenza e quello di destinazione coincidano (non vengono inseriti nel project_save.tmx e di conseguenza non entrano nemmeno nella TM).78
 |
I segmenti possono essere aperti per la modifica uno alla volta, a partire dal primo, ed è possibile spostarsi avanti o indietro con delle semplici combinazioni di tasti (es. in stile Emacs Ctrl-N e Ctrl-P) oppure semplicemente in avanti con Invio> o Tab (a seconda delle impostazioni prescelte). Il ‘salto’ tra due posizioni non contigue del testo è possibile, facendo doppio clic sul segmento destinazione del salto oppure, se di questo è conosciuto il numero identificativo (Ctrl-J).
Ogni volta che si apporta una qualsiasi modifica a un segmento e si ‘esce’ dalla modifica spostandosi avanti o indietro, OmegaT aggiunge la coppia di segmenti alla memoria di traduzione e traduce in modo automatico tutti i segmenti identici a quello presenti negli altri file di progetto (caratteristica nota come ‘match propagation’).79 In seguito, dal momento che l'uscita da un segmento in OmegaT coincide sempre con l'apertura di un altro, il programma interroga le TM e il glossario per cercare corrispondenze relative al nuovo segmento in elaborazione.
Come detto in precedenza, OmegaT è in grado di gestire anche documenti formati sia da contenuti testuali che da informazioni relative alla formattazione che vengono tradotte in una serie di tag presenti nel testo originale. Questi vengono ignorati, salvo in casi particolari, ai fini della ricerca e del calcolo delle corrispondenze in TM.
In OmegaT i tag appaiono in una forma abbreviata (o simbolica), e sono rappresentati da una o più lettere seguite da cifre. Esistono due tipi di tag: quelli singoli (ad es. <s1/>) e quelli doppi formati da una posizione di apertura e una di chiusura (es. la coppia <f0>…</f0>). I numeri servono a garantire l'univocità, quando in uno stesso segmento compaiono diversi tag abbreviati con le stesse lettere, tag dello stesso gruppo (come le coppie) avranno lo stesso numero per evitare ambiguità, con una numerazione progressiva che in rari casi si estende anche oltre i limiti di segmento come nel caso in cui, ad esempio, a causa della segmentazione i due elementi di una coppia di tag vengano suddivisi in segmenti diversi.
Affinché la formattazione possa essere conservata nei documenti finali i tag devono essere riprodotti nei segmenti di arrivo con la stessa dicitura, nello stesso numero e, tranne casi particolari, nello stesso ordine. Nonostante i tag siano presentati dal programma in dimensione ridotta, per non distogliere l'attenzione dal contenuto testuale che deve essere tradotto, non è disponibile alcuna modalità di inserimento facilitato, a meno che non si copi l'intero segmento sorgente nel campo di modifica.
In compenso, il programma è provvisto di una funzionalità di verifica interna (Strumenti/Convalida i tag oppure Ctrl-T), in cui la natura, il numero e l'ordine dei tag viene controllato segmento per segmento e, qualora fossero registrate delle anomalie, vengono visualizzate in una tabella dove le discrepanze sono messe in evidenza con i colori e, facendo clic sul numero del segmento interessato, è possibile spostarsi direttamente in quella posizione del testo nell'editor per correggere l'errore.
L'operazione di validazione dei tag è molto importante perché l'approccio di OmegaT può indurre all'errore con facilità, specialmente in progetti consistenti o ricchi di cambiamenti di formattazione all'interno del testo e, talvolta, un errore relativo ai tag può determinare l'impossibilità di aprire i documenti finali.
Tuttavia esistono dei casi in cui sono consentite delle variazioni sui tag che, anche se rilevate dalla convalida interna al programma come errori, vengono incontro alle esigenze di riformulazione e inversione tipiche della traduzione. Ad esempio, è possibile duplicare o eliminare un tag singolo o una coppia, per replicare o per cancellare una determinata formattazione.
L'ordine dei tag può essere invertito, avendo la cura di rispettare il nome simbolico e la numerazione. È altresì possibile permutare l'ordine annidando i tag gli uni all'interno degli altri, facendo attenzione a rispettare i marcatori di apertura e di chiusura senza sovrapposizioni, che potrebbero invece dar luogo a errori (regola di well-formedness).
Pur essendo uno strumento dalle finalità di utilizzo molto ampie, OmegaT intende sostituirsi, o per lo meno integrarsi, ai programmi per la localizzazione di file di risorse e di PO. In questi casi è molto probabile imbattersi non solo in tag simili all'(X)HTML ma anche e soprattutto negli specificatori di formato o placeholder (cfr. sez. 2.4.2).
OmegaT è in grado di riconoscere e di controllare la validità anche di questo genere di espressioni, a tre livelli di elasticità selezionabili dal menu Opzioni/Convalida dei tag. I placeholder possono essere ignorati (comportamento predefinito), si può scegliere la validazione semplice, in cui vengono utilizzate solo le varianti più semplici (es. %s, %d, ecc.) oppure la validazione completa in cui si considerano espressioni più complesse, ma che in molti casi può generare falsi positivi ([Helary et al., 2010]). Se la traduzione richiede il cambiamento dell'ordine dei placeholder, questo è sempre possibile seguendo le regole presentate nella sezione 2.4.2.
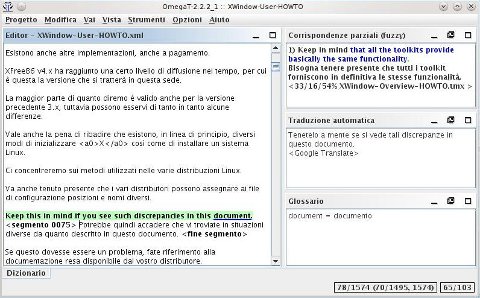
In fase di traduzione interattiva, ogni volta che viene inizializzato un segmento per la modifica, OmegaT interroga le TM di progetto e visualizza nell'area Corrispondenze parziali (fuzzy) i segmenti più simili a quello corrente. Nel caso in cui fossero presenti più corrispondenze parziali, viene selezionata (in grassetto) quella con la percentuale di somiglianza più alta. Se una corrispondenza parziale è selezionata, le parti che non compaiono nel testo di partenza del segmento in traduzione sono evidenziate con il colore blu, mentre le parole adiacenti alle parti mancanti con il verde.
Dal momento che tutte le corrispondenze parziali recuperate dalle TM sono numerate, è possibile selezionare quelle successive alla prima con le combinazioni di tasti Ctrl-2, Ctrl-3, ecc. Per inserire la corrispondenza selezionata nel campo di modifica si può utilizzare una combinazione di tasti (Ctrl-I inserisce la corrispondenza a partire dalla posizione del cursore, Ctrl-R sostituisce tutto il contenuto del campo di modifica con la corrispondenza selezionata).80
La percentuale di corrispondenza viene calcolata in tre modi diversi, che corrispondono ai tre valori visualizzati sotto ogni corrispondenza. I primi due valori sono calcolati sulla base delle parole comuni e dell'ordine in cui compaiono nei due segmenti, con la differenza che il primo considera le parole ridotte alla loro radice (grazie al tokenizer, v. poi) mentre il secondo utilizza le parole inalterate, ma ignorando punteggiatura e tag. Il terzo valore, invece, tiene conto della punteggiatura, nonché di tag e numeri (placeable).
Di ogni corrispondenza parziale viene inoltre visualizzato il nome del file TM da cui è stata recuperata, in modo che l'utente sia in grado di operare le proprie scelte nella maniera più consapevole possibile. Se non è indicata alcuna TM, le corrispondenze provengono dalla memoria predefinita di progetto (project_save.tmx) e cioè si tratta delle cosiddette ‘stringhe orfane’ che vengono infatti etichettate come tali accanto alle percentuali.
La soglia di match predefinita affinché una corrispondenza venga visualizzata nella corrispondente area della finestra è il 30%, vale a dire, almeno uno dei tre valori citati poc'anzi deve essere superiore a tale soglia.
La corrispondenza parziale selezionata in maniera predefinita corrisponde a quella con il valore più alto che viene reperita in una delle TM. Ne consegue che i ‘veri’ 100% match, ovvero le corrispondenze in cui tutti e tre i valori sono al massimo, appaiono sempre in cima alla lista delle corrispondenze.81
La politica di valutazione delle corrispondenze di OmegaT è molto buona e senza dubbio una delle caratteristiche più vantaggiose è che viene visualizzato accanto al valore di corrispondenza anche il nome della TM da cui proviene la TU, in modo che il traduttore sappia quanto sia affidabile la soluzione proposta. Purtroppo, invece, non esiste alcun metodo per assegnare delle ‘penalità’ a determinate memorie, alle TU create o modificate da vari utenti e a molti altri sistemi di gestione avanzata delle TM che sono implementati negli strumenti CAT ‘tradizionali’. A tale piccolo inconveniente è possibile porre rimedio effettuando ricerche avanzate nelle TM e comportandosi, di volta in volta, di conseguenza.
Inoltre, sempre durante la fase di editing interattivo del campo di modifica, verranno visualizzate le corrispondenze dei termini dei dizionari e dei glossari inclusi nel progetto, all'interno delle rispettive aree della finestra principale. Nel caso delle voci di glossario, queste non solo saranno elencate nel riquadro, ma i termini corrispondenti nel segmento di partenza verranno evidenziati con una sottolineatura di colore blu.
All'occorrenza, per inserire il termine in maniera facilitata, invece di ricopiarlo è possibile fare clic col pulsante destro del mouse sulla sottolineatura e selezionare il termine in lingua d'arrivo nel menu contestuale visualizzato. Purtroppo, allo stato attuale delle cose, le corrispondenze riscontrate grazie al tokenizer sono mostrate solo nel visualizzatore del glossario ma non appaiono sottolineate nel testo di partenza né è disponibile alcun metodo di inserimento facilitato (con tutta probabilità questo problema sarà risolto nelle future versioni dell'applicazione).
Al termine della traduzione, in fase di compilazione dei file d'arrivo, che in OmegaT corrisponde al clean-up degli strumenti CAT tradizionali, i documenti di partenza saranno ricreati con la stessa struttura e i nuovi contenuti. Se questi erano inseriti all'interno di un albero di directory più articolato, questo sarà analizzato in modo automatico e, al momento di generare i file d'arrivo, verrà ricreata in maniera identica a quella di partenza, ivi compresi anche tutti i file non riconosciuti o i cui filtri sono stati disabilitati, che saranno copiati.
In realtà, quando si seleziona Progetto/Crea i documenti di arrivo, il programma non fa altro che unire le informazioni memorizzate nel già trattato file project_save.tmx con i documenti di partenza, per produrre il contenuto della directory target. Laddove la traduzione non fosse stata ancora ultimata, OmegaT inserirà i contenuti in lingua di partenza presenti nella directory source. In modo simile, le TU project_save.tmx vengono salvate nelle TM ‘finali’ del progetto.
Se, dopo la compilazione, visualizzando il risultato del processo di traduzione ci si rende conto che sono necessarie delle modifiche, è sempre possibile modificare le TU del progetto dall'interno dell'editor, quindi creare di nuovo i documenti finali: in questo modo gli errori saranno corretti sia nei documenti di arrivo che in tutte le TM in scrittura.
OmegaT può considerarsi un programma CAT/TM completo in quanto integra in maniera ottimale tutte le funzionalità tecnologiche viste nella sezione 1.1.2 relative alla fase interattiva di traduzione, compresa l'interazione con la traduzione automatica (MT).
È prevista infatti l'interazione con tre servizi di MT: Belazar (per la traduzione da russo a bielorusso e viceversa); Apertium, un'interessante piattaforma di traduzione automatica open-source finanziata da molti enti pubblici e università straniere (che al momento non contempla l'italiano fra le lingue disponibili); e la celebre piattaforma Google Translate, che si rivela di giorno in giorno più accurata.
Una seconda funzionalità inclusa in maniera predefinita nel programma e molto utile in fase di traduzione interattiva è la correzione ortografica. OmegaT supporta il correttore open-source Hunspell, utilizzato anche da OpenOffice.org e dalle applicazioni Mozilla. Se si utilizza già una versione localizzata di queste applicazioni è molto probabile che i dizionari siano già installati nel sistema,82 in alternativa, è molto facile procurarseli (come indicato nella documentazione). Per poter funzionare, il controllo ortografico deve essere attivato dal menu Opzioni/Correzione ortografica.
Inoltre è importante che il codice della lingua d'arrivo del progetto coincida interamente con il nome di uno dei dizionari presenti nella finestra di configurazione (e non solo la prima parte). Volendo utilizzare dei dizionari diversi da quelli di OpenOffice.org o delle altre applicazioni che utilizzano Hunspell, è possibile inserire i file del dizionario (es. it_IT.aff e it_IT.dic) in una directory e specificare poi quella come la posizione dei dizionari di sistema.
In OmegaT il controllo ortografico viene eseguito sul testo tradotto mentre questo viene immesso nel campo di modifica. Gli errori sono segnalati mediante una sottolineatura ondulata di colore rosso e le correzioni possono essere apportate facendo clic col pulsante destro del mouse sulla parola sottolineata e scegliendo fra una delle alternative visualizzate nel menu a comparsa. In alternativa è possibile stabilire di ignorare tutte le occorrenze della parola o di aggiungerla al dizionario.
Non è invece possibile eseguire un controllo generale su tutti i documenti caricati spostandosi in modo automatico da un errore all'altro per evitare di cercare una per una le sottolineature in rosso, che potrebbero sfuggire con facilità. L'unica via percorribile, in questo caso, è procedere a un post-editing con un elaboratore di testo avanzato che supporti questa funzionalità. In tale caso, però, le eventuali modifiche non sarebbero incorporate nella TM, dal momento che non sono apportate dall'interno dello strumenti CAT.
Un ultimo aspetto, non per questo meno importante, è rappresentato dalle possibilità di ricerca all'interno del progetto. OmegaT mette a disposizione dell'utente un'interfaccia di ricerca molto valida e avanzata, che permette di specificare come criteri non solo il contenuto dei segmenti sorgente e destinazione (alternativamente o entrambi), ma anche metadati relativi alle TU quali l'autore, la data di creazione e così via.
La finestra di ricerca (figura 27) può essere richiamata dal menu Modifica/Cerca nel progetto oppure con la combinazione da tastiera Ctrl-F. L'espressione da ricercare deve essere inserita nel campo di testo Cerca: o, in alternativa, può essere selezionato sia nel testo di partenza che in quello d'arrivo e, rispetto alle versioni precedenti del programma, le corrispondenze sono evidenziate con un diverso colore affinché risaltino meglio.
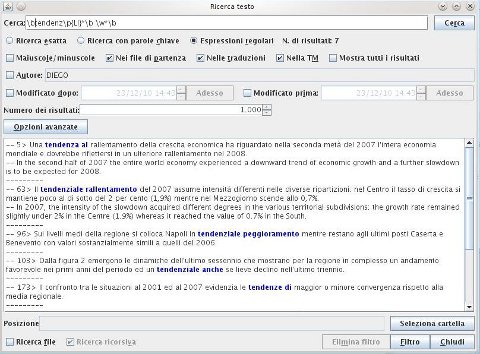 |
Risultano notevolmente interessanti la possibilità di specificare la portata della ricerca (ad es. se solo nel progetto o nelle TM in consultazione), di impostare la sensibilità a maiuscole/minuscole, di selezionare il numero di risultati massimo da visualizzare e, infine, di ‘filtrare’ i segmenti nell'editor facendo sì che compaiano solo quelli che soddisfano alle condizioni di ricerca (il filtro può in seguito essere rimosso con il pulsante Elimina filtro per tornare al lavoro consueto).
Per la ricerca, sono disponibili tre modalità: esatta, con la quale verranno restituite le occorrenze della stringa immessa nel campo di ricerca, per parole chiave, che restituisce tutti i segmenti contenenti i termini di ricerca, indipendentemente dall'ordine in cui compaiono e, da ultimo, tramite espressioni regolari con una sintassi coerente con lo standard Java per le regex e quindi molto potente, almeno nell'opinione di chi scrive, che spesso traducendo ne ha fatto uso con profitto.83
Se queste, da un lato, sono le funzionalità ‘di base’ di OmegaT, già si è visto che queste possono essere ulteriormente espanse con il ricorso a opportune estensioni (plug-in). I tokenizer per le varie lingue, scaricabili dalla pagina delle estensioni su SourceForge, rappresentano un primo esempio di estensione molto utile, dal momento che permettono di riconoscere le corrispondenze parziali anche all'interno dei glossari.84
Per poter usufruire delle nuove funzionalità è necessario non solo copiare il pacchetto .jar nella directory plugins del percorso principale del programma (cioè la directory contenente OmegaT.jar), ma aggiungere allo script di avvio le relative opzioni.85
Un'altra estensione molto utile è il Language-Tool, per l'installazione e la messa in funzione del quale si rimanda alla documentazione, che può essere visto come un'ulteriore tappa nel controllo qualità interno a OmegaT.
Tale estensione, che integra il supporto anche all'italiano, mette in guardia da errori di digitazione non rilevati dal controllo ortografico, come minuscole a inizio frase, spazi doppi, ecc. e problemi di stile come frasi ridondanti (che cioè contengono troppe parole ripetute). Anche se un simile strumento rappresenta un grande aiuto per il miglioramento della qualità, non è in grado di rilevare errori grammaticali, di punteggiatura o di stile per cui la revisione (come con qualsiasi altro strumento CAT) resta un passaggio di importanza fondamentale nel processo traduttivo.
La documentazione ufficiale di OmegaT è chiara, esaustiva e molto ben strutturata, adatta sia agli utenti più esperti che ai meno specializzati. Si tratta di uno dei manuali più completi e curati fra tutti quelli che sono stati presi in considerazione per questo lavoro e a esso si è rimandato più volte (Helary et al. [2010]) per gli aspetti in cui lo spazio qui a disposizione si è rivelato insufficiente.
Così come l'interfaccia grafica del programma, anche la documentazione è tradotta in numerose lingue, a testimonianza del grande coinvolgimento della comunità che ruota attorno al programma e della grande maturità del progetto.86
Sul sito del progetto è presente anche un'esercitazione per i nuovi traduttori, numerose guide di terze parti su argomenti specifici, video introduttivi e molto altro materiale utile anche per i non specialisti con nessuna esperienza specifica nel campo della localizzazione (o degli strumenti CAT) che vogliano cimentarsi nella traduzione in generale o acquisire dimestichezza con le tecnologie di traduzione assistita in particolare.
Per la redazione di questa sottosezione, oltre alla documentazione ufficiale e all'esperienza con l'utilizzo del programma, si sono rivelate di grande importanza anche le pagine del Wiki di OpenOffice.org, redatte dal gruppo di localizzazione italiana.87
3.3.2 Anaphraseus
| Autori: | Oleg Tsygani, Dmitri Gabinski, Sergei Medvedev |
| Licenza: | GNU GPLv3 |
| Pagina web: | http://anaphraseus.sourceforge.net |
| Versione: | 2.01 (gennaio 2010) |
La differenza principale fra i classici software di traduzione assistita e Anaphraseus è costituita dal fatto che quest'ultimo non è dotato di un editor interno ma si appoggia a un elaboratore di testi esterno: la celebre suite di produttività individuale OpenOffice.org, una fra le più diffuse nell'utenza GNU/Linux in ambito desktop.
Il programma è quindi disponibile come estensione di Openoffice.org, sviluppata in StarOffice BASIC. Il gruppo di sviluppatori non fa mistero di aver tratto ispirazione dal prodotto commerciale Wordfast (il nome iniziale dell'applicazione, in un primo momento, era infatti ‘OpenWordfast’) che, nella versione ‘Classic’ adotta questo medesimo principio inserendosi all'interno di MS Office.88 Anche il formato di TM in testo semplice utilizzato da Anaphraseus è ispirato da (e compatibile con) il celebre programma commerciale creato da Yves Champollion.
Per l'installazione dell'applicazione, trattandosi di un set di macro per OpenOffice.org, è possibile procedere come per qualsiasi altra estensione. Dopo l'attivazione, apparirà un nuovo menu recante il nome dell'applicazione e una barra degli strumenti per la gestione della traduzione. Le voci del menu, così come la finestra di dialogo delle impostazioni, sono localizzate in italiano.
Per iniziare il lavoro è necessario aprire il file di partenza nel programma di videoscrittura e caricare una TM attraverso la finestra di dialogo delle impostazioni di Anaphraseus.
È possibile caricare solo un file alla volta, dal momento che non è consentita la creazione di progetti costituiti da più file di partenza.89
La TM può essere creata da zero, possono essere utilizzati un file di testo semplice o un TMX preesistenti e può essere salvata in formato di testo (Unicode a 16 bit) o, ancora, TMX. Al momento della creazione di una nuova TM è richiesto di impostare le lingue di lavoro e la direzione linguistica, dalla stessa schermata è inoltre possibile riorganizzare la memoria o invertire la direzione linguistica.
Una volta configurate le impostazioni iniziali, si può procedere con il lavoro di traduzione. Come nella totalità dei programmi con tecnologia TM, all'avvio di una nuova sessione di traduzione interattiva, il testo di partenza viene automaticamente diviso in una serie unità costitutive (segmenti) per essere confrontato con il contenuto della TM. I delimitatori di segmento sono inseriti come caratteri non stampabili all'interno del documento stesso, accompagnati da numeri che segnalano il livello di corrispondenza con le TU della memoria (indicando quindi match completi e fuzzy).
Nel caso in cui il testo del segmento di partenza fosse diverso da quello della prima parte di una TU conservata nella TM, oltre alla percentuale di corrispondenza, nel campo del segmento in lingua d'arrivo verrà inserito il testo contenuto in memoria mentre nella barra di stato di OpenOffice.org, cioè in basso sinistra nella finestra principale, sarà visualizzato il testo sorgente presente in memoria (senza però alcuna evidenziazione delle differenze).
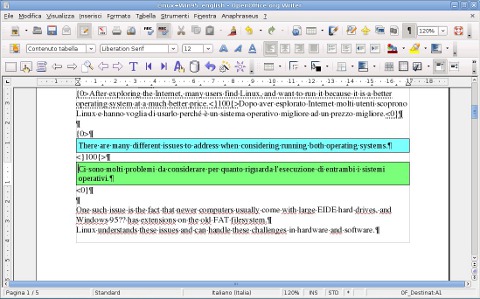 |
L'assunzione alla base del comportamento del programma durante la fase di traduzione è che l'utente proceda in maniera sequenziale dall'inizio alla fine del testo. I segmenti devono essere via via ‘aperti’ per la modifica, ed è possibile passare agevolmente solo dal segmento corrente a quello successivo. Tradurre in ordine diverso è comunque possibile, mentre non è presente alcuna possibilità per marcare le unità di traduzione come fuzzy o in attesa di revisione.
Al termine della sessione di traduzione, si ottiene come risultato un testo bilingue ‘unclean’ sotto forma di documento di testo, molto simile a quanto avviene con i programmi di traduzione assistita commerciali che si integrano in MSOffice. Il testo di partenza e i metadati inseriti automaticamente dal programma possono essere rimossi con la procedura di clean-up, ancora una volta in modo simile a quanto avviene con programmi come Wordfast o SDL-Trados.
L'utilizzo delle TM è in parte configurabile: è infatti possibile impostare una soglia di fuzzy match, al di sotto della quale i segmenti non saranno più considerati ‘simili’ a quello corrente e non saranno presentati all'utente per il confronto immediatamente al di sotto di quello aperto per la traduzione.
Anche la segmentazione è personalizzabile: nella schermata delle impostazioni compare infatti un campo di testo in cui è possibile inserire di delimitatori di frase. Sfortunatamente il programma non supporta lo standard SRX per le regole di segmentazione, tuttavia le scelte operate in automatico possono essere modificate durante la sessione di traduzione espandendo o ridimensionando i segmenti predefiniti. Sempre fra le impostazioni, è possibile specificare gli elementi placeable, cioè non traducibili. Un potenziale limite, accanto a quello poc'anzi segnalato riguardo i delimitatori, è l'impossibilità di inserire espressioni più complesse (es. regex) per le parti non traducibili, cosa che renderebbe il loro riconoscimento molto più efficiente.
Come già detto, Anaphraseus utilizza nativamente il formato di testo semplice per le TM, in piena compatibilità con le memorie delle prime versioni di Wordfast. Ciononostante, restano sempre possibili le importazioni e le esportazioni da e verso lo standard TMX, per assicurare la piena compatibilità con gli altri strumenti CAT/TM. È tuttavia possibile caricare una sola TM alla volta per cui, volendo utilizzare dati contemporaneamente da più file, l'unica via percorribile sembra essere quella dell'importazione.
La TM in uso, inoltre, può essere consultata solo dal programma in modo automatico durante l'esecuzione, ma all'utente non è consentito avere accesso alla banca dati delle TU in fase di traduzione. Uno svantaggio di questo è che per effettuare ricerche nella TM si rende necessario aprire il documento (o, meglio, una sua copia) con un editor di testo durante la traduzione, mentre il vantaggio è che le TM, se anche in formato testuale, contengono sufficienti metadati una consultazione anche avanzata (sulla base della data, del creatore, ecc.), con tutte le funzionalità di ricerca dell'editor di testo di elezione.
Sempre dalla schermata delle impostazioni, è possibile caricare dei glossari definiti dall'utente, contenenti le voci terminologiche utili alla traduzione. I termini presenti nel testo di partenza per cui è riscontrata una corrispondenza nel glossario, sono segnalati con un riquadro di colore blu. La selezione fra le varie voci terminologiche presenti in un segmento e l'inserimento degli equivalenti in lingua d'arrivo sono quindi facilitati da opportune scorciatoie da tastiera.
Come nel caso delle TM, anche i glossari sono in formato di testo semplice. Se, da una parte, questo ne rende molto facile la creazione e la leggibilità (è possibile creare e modificare glossari senza l'utilizzo di programmi specifici e senza timore di alterare la sintassi del file), dall'altro si tratta pur sempre di un formato non standard difficilmente riutilizzabile con altri programmi.
Anaphraseus permette di caricare due glossari allo stesso tempo: un glossario principale e un glossario utente. Sul glossario principale non è possibile intervenire in alcun modo — modificare, aggiungere nuove voci o eliminare quelle esistenti — dall'interno del programma. L'unico sistema per avere accesso in scrittura al glossario è aprirlo in un editor di testo esterno, tenendo presente che le modifiche non avranno alcun effetto sulla traduzione corrente fino al riavvio del programma e, cioè, di OpenOffice.org.
Diverso è il caso per il glossario utente, che può invece essere modificato aggiungendo termini man mano che si prosegue con il lavoro. L'inserimento è facilitato da scorciatoie da tastiera e sono supportati tre campi per ciascuna voce terminologica: l'espressione in lingua di partenza, il traducente e uno spazio riservato ai commenti (per le definizioni, fonti, annotazioni, ecc.).
Per ottimizzare il riconoscimento della terminologia, abbastanza avanzato in Anaphraseus, è possibile ricorrere all'asterisco come wildcard (d'ora in avanti ‘caratteri jolly’) in modo da ignorare le variazioni morfologiche creando una sorta di word stemming rudimentale.90 In modo analogo a quanto detto per la TM, anche nel caso in cui vi sia una corrispondenza nel glossario la voce terminologica viene mostrata nella barra di stato con tutte le informazioni inserite in fase di creazione.
Fra le funzionalità aggiuntive, è il caso di segnalare che Anaphraseus offre anche delle statistiche di base, che permettono di visualizzare il numero di caratteri con spazi inclusi ed esclusi. Non è presente, invece, la possibilità di realizzare statistiche ‘ponderate’ sul contenuto della TM, che permettano di valutare in maniera effettiva la reale entità del lavoro da fare.
Oltre alle risorse terminologiche descritte in precedenza e alla TM, invece, non è previsto l'utilizzo di aggiunte provenienti da terze parti. A differenza di quanto visto per OmegaT manca, ad esempio, il supporto a dizionari off-line (quali, ad esempio, il molto promettente StarDict), così come non è prevista l'integrazione con alcun software di traduzione automatica.
Come già visto, Anaphraseus non utilizza alcun editor interno, ma si appoggia a un software di elaborazione testi esterno. Il principale punto di forza di un simile approccio è che per il traduttore non è necessario imparare ad usare alcun nuovo programma e che, traducendo in modalità interattiva, è possibile l'ambiente di lavoro sarà intuitivo e familiare per l'utilizzatore finale.
Inoltre, lavorare all'interno di un elaboratore di testi come ambiente di traduzione permette di avere una visione più vicina alla realtà del testo di partenza, senza il livello di astrazione che comporta invece utilizzare un programma di traduzione specifico (in cui la formattazione non è visibile al traduttore se non attraverso tag simbolici).
Dal punto di vista degli sviluppatori, invece, questo significa poter contare su un editor di testi stabile e potente come OOoWriter, senza tentare di emulare di emulare tutte le funzionalità in un editor proprio creato ad hoc.
Lo svantaggio implicito in tale prospettiva è la relativa poca flessibilità di dover integrare nuove funzionalità in un ambiente che non è stato pensato in origine per contenerle, senza contare i problemi di compatibilità (all'indietro, ma soprattutto in avanti) che l'evoluzione upstream di un programma può comportare per le estensioni sviluppate da terze parti.91
Un altro limite alla flessibilità è rappresentato dal ristretto repertorio di formati su cui il programma è in grado di operare. Infatti questo è limitato dai file che possono essere letti da OOoWriter, ma senza alcun supporto ai documenti contenenti tag come, HTML e tutti i formati basati su XML. Gli eventuali tag vengono considerati come parte del testo, il loro inserimento non è facilitato, non è possibile ridurli in dimensione ‘compatta’ e contribuiscono ad abbassare sensibilmente il valore di match. È tuttavia possibile che questi problemi verranno risolti nei successivi rilasci del programma.
Sarebbe scorretto, inoltre, non segnalare che il software è ancora in versione beta, e non sono infrequenti casi di comportamenti imprevisti e malfunzionamenti. Inoltre, Anaphraseus può dare luogo a un calo di prestazioni con memorie e glossari di dimensioni medio-grandi, in fase di importazione e di ‘apertura’ dei segmenti per la modifica, rivelandosi più lento dei suoi programmi equivalenti.
La documentazione ufficiale del programma, in inglese, è estremamente sintetica ma, pur riferendosi a una versione precedente, è sufficiente per l'utilizzo di base del programma. Esiste anche una buona ‘Guida per Principianti’ in italiano, redatta da N. Vessella, l'autore della localizzazione italiana, che a dispetto del nome contiene numerose informazioni utili a chi volesse iniziare a lavorare con il programma.92
3.3.3 GNU Emacs (PO Mode)
| Autori: | S. Monnier, E. Zaretskii, R. M. Stallman et al. |
| Licenza: | GNU GPLv3 |
| Pagina web: | http://www.gnu.org/software/emacs |
| Versione: | 23.2 (maggio 2010) |
GNU Emacs è uno degli editor ‘storici’ e il più amato (o, a seconda dei punti di vista, odiato) dagli utenti di SL e per questo può essere installato virtualmente su qualsiasi sistema GNU/Linux. Ai fini di questa sottosezione è necessario disporre di un sistema in cui siano installati sia GNU Emacs (d'ora in avanti, per comodità, Emacs) che l'infrastruttura GNU gettext.
Per procurarsi i sorgenti e per la compilazione di questi strumenti si consiglia di fare riferimento alla relativa documentazione. Se invece la propria distribuzione GNU/Linux prevede un sistema di gestione dei pacchetti, è possibile semplificare di molto la procedura. In una Debian (o nelle sue derivate) la soluzione più semplice consiste nell'installare i metapacchetti gettext — per gli strumenti GNU gettext di cui si è già parlato nella sezione 2.4 — e emacs, per il celebre editor di testo.
Inoltre, è necessario installare il pacchetto gettext-el, non compreso nell'installazione base di gettext in Debian, per aggiungere il file po-mode.el alla propria ‘libreria’ Emacs LISP in modo da avere accesso alla modalità PO (PO-mode).
Emacs, nella versione specificata, può essere avviato sia in modalità puramente testuale che con un'interfaccia utente basata sul toolkit grafico GTK+. Non esistono differenze in quanto a funzionalità fra le due alternative, la seconda risulta tuttavia più intuitiva per la presenza di menu grafici e l'interazione con i dispositivi di puntamento ma può essere eseguita solo in sistemi dotati di interfaccia grafica mentre per la prima è sufficiente una shell testuale.
Nella trattazione che segue, si considererà tuttavia l'esecuzione testuale di Emacs, dal momento che il PO-mode è pensato per essere utilizzato da tastiera e il menu PO aggiunto da quest'ultimo all'interfaccia grafica non solo non è di utilizzo molto agevole ma non dà nemmeno accesso a tutte le funzionalità del caso. Data la complessità del programma, che in realtà è molto di più rispetto a un editor di testo, la trattazione che segue sarà limitata ai soli aspetti interessanti per il localizzatore.Sono inoltre dati per scontati i rudimenti sull'utilizzo e le nozioni alla base di Emacs.93
 |
Il PO-mode è una modalità primaria di Emacs che permette di intervenire sui file PO con una serie di funzionalità molto più avanzate del semplice editing di testo che, da un lato, avvicinano l'esperienza dell'utente agli strumenti CAT più elaborati e, dall'altro, integrano tutte le caratteristiche (e anche un po' oltre) che si vedranno per gli editor di PO successivi in quanto a completezza e ottimizzazione del lavoro.
Per iniziare a lavorare su PO con Emacs è sufficiente aprire (‘visitare’) il file dal programma. Possono anche essere aperti più file PO contemporaneamente in buffer diversi e sarà possibile salvare e ripristinare la sessione secondo le modalità proprie di Emacs (cioè M-x desktop-save, eccetera). Se il sistema è configurato correttamente,94 il po-mode dovrebbe attivarsi in modo automatico all'apertura di un file PO. È comunque possibile uscire in qualsiasi momento da questa modalità con M-x po-edit-out-full.95
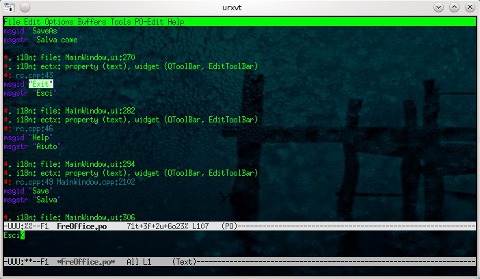
Nel contesto di Emacs il caricamento di una nuova modalità implica la modifica del comportamento e dell'aspetto del programma. In questo caso, l'interfaccia cambierà leggermente, le varie parti del testo del PO appariranno con colori diversi per evidenziarne la sintassi, alcuni comandi non saranno più disponibili o avranno un significato diverso mentre ne verranno aggiunti di nuovi comandi per le operazioni sul testo, per spostarsi all'interno dello stesso e per interagire con le utilità di GNU gettext.
In particolare, tutte le parti di testo al di fuori del campo msgstr saranno in sola lettura, in modo da impedirne l'eventuale modifica da parte dell'utente, salvaguardando così il file da errori di sintassi che renderebbero impossibile la compilazione del PO. L'unico modo per modificare il contenuto di un messaggio è ‘aprirlo’ per la modifica e in seguito salvare la traduzione.
Se il po-mode è attivo, è possibile spostarsi da un messaggio all'altro secondo le seguenti modalità: primo (<), ultimo (>), successivo (n), precedente (p), successivo tradotto (t), precedente tradotto (M-t), successivo non tradotto (u), precedente non tradotto (M-u), successivo fuzzy (f), precedente fuzzy (M-f), successivo obsoleto (o) e precedente obsoleto (M-o).96
Risulta particolarmente utile la possibilità di salvare le locazioni in una pila (stack) con politica LIFO e le tipiche operazioni di push (m) e pop (r) o di scambiare la posizione corrente con l'ultima salvata nella pila (x), permettendo di ritornare in seguito su determinati punti di interesse della traduzione.
Con questi comandi lo spostamento avviene da messaggio a messaggio (cioè il punto di inserimento si posiziona all'inizio del msgid). Le consuete modalità di navigazione di Emacs hanno effetto ma portano il cursore in righe o in punti della riga dove l'inserimento del testo non è possibile. Per posizionarsi nuovamente all'inizio di un messaggio è utile il comando . che riporta alla visualizzazione normale del messaggio corrente.
È da notare che questi comandi provocano lo spostamento del punto di inserimento senza scrivere nessun carattere nel testo come sarebbe invece accaduto nella stessa modalità fondamentale o nella maggior parte degli editor: l'inserimento di testo è consentito solo in determinate condizioni e questo consente che uno stesso comando abbia effetti diversi (l'inserimento del carattere ‘n’ o lo spostamento al messaggio successivo) a seconda del contesto.97
La possibilità di digitare la traduzione si attiva con il comando RET, che causa la creazione di un buffer temporaneo (visualizzato in modalità split window orizzontale) in cui ritornano a essere attivi tutti i consueti comandi per l'inserimento e la manipolazione del testo tipici di Emacs. Al termine della traduzione di un messaggio, il buffer e la finestra che lo ospitano possono essere chiusi salvando l'intervento del traduttore (C-c C-c) oppure ripristinando la condizione di partenza (C-c C-k). Entrambe le azioni riportano il programma in modalità ‘navigazione’.
La traduzione eventualmente immessa o preesistente situata nel campo msgmerge può essere cancellata con il comando k, in realtà il testo viene eliminato dal documento e spostato nel ‘kill ring’, da cui può essere recuperato più avanti (anche in buffer diversi) con il comando y (il comando w, invece, copia nel ‘kill ring’ senza cancellare la traduzione). Il testo sorgente può essere copiato nel campo di modifica con il comando C-j e impostando a t la variabile po-auto-edit-with-msgid è possibile emulare il comportamento di molti strumenti CAT in cui all'apertura di un segmento il campo di modifica viene inizializzato con il testo sorgente.
A parte la traduzione, sono consentiti altri due tipi di interventi sul PO a livello di messaggio. Il primo è la rimozione o l'aggiunta dell'etichetta fuzzy, utili per segnare come tradotta una stringa recuperata da msgmerge oppure per marcare il messaggio come in attesa di revisione. Le due azioni sono ottenute rispettivamente con i comandi TAB e DEL.98 Impostando a t la variabile po-auto-fuzzy-on-edit è inoltre possibile marcare in modo automatico ogni messaggio modificato dal traduttore come fuzzy in vista di una successiva revisione.
Il secondo è la modifica dell'unico tipo di commenti a disposizione dei responsabili della localizzazione: i cosiddetti commenti del traduttore (#_). Questi possono essere modificati interattivamente con il comando #, cancellati e messi nel ‘kill ring’ (K), copiati (W) e recuperati (Y) da quest'ultimo. Le azioni sono molto simili a quelle che si applicano alle traduzioni e il comando #, al pari di RET per il contenuto del campo msgstr, apre un buffer in una finestra temporanea dove il traduttore può immettere o modificare i commenti.
Diversamente dalla maggior parte degli editor negli strumenti CAT in Emacs è possibile avere più messaggi, o anche più messaggi e commenti, aperti allo stesso tempo per le modifiche. Per fare ciò è sufficiente aprire un messaggio per la modifica all'interno di un buffer, tornare al buffer principale, navigare fra i messaggi e aprirne un altro (o un commento) per la modifica. Queste ‘sottomodifiche’ possono essere portate a compimento nell'ordine che si preferisce, spostandosi da un buffer all'altro o disponendo le finestre (window) di Emacs a proprio piacimento, e possono essere ‘chiuse’ in ordine indipendente dal momento di apertura.
Emacs integra al suo interno altre funzionalità molto interessanti. In primo luogo, la visualizzazione di statistiche relative al file aperto nel buffer corrente. Nella mode line, infatti, sono sempre presenti i conteggi in forma ridotta dei messaggi classificati in base al tipo (tradotti, fuzzy, non tradotti e obsoleti), in modo da rendere facile calcolare l'effettivo lavoro rimanente. Nel caso in cui una di tali categorie non dovesse contenere messaggi, questa non sarà visualizzata nella modalità ridotta: ad es. |71t+2f+3u| mostra che 71 messaggi sono tradotti, 2 sono fuzzy, 3 non tradotti ma nessuno obsoleto. Le statistiche in forma estesa sono invece visualizzate con il comando = in modalità navigazione, cui si aggiunge anche la posizione corrente all'interno del file, numerando i messaggi a partire da 1.
In secondo luogo, qualora fosse necessaria la consultazione dei sorgenti del programma per risolvere eventuali dubbi, è possibile seguire il riferimento al sorgente dall'interno di Emacs. Il comando s provocherà l'apertura del sorgente in un buffer visualizzato in una nuova finestra, alla posizione indicata nel primo riferimento al sorgente del messaggio. Dal momento che possono essere presenti più riferimenti al sorgente per uno stesso messaggio (e che, anzi, devono esserci più riferimenti al sorgente se il messaggio si ripete, vista l'univocità delle stringhe), è possibile spostarsi fra un'occorrenza e l'altra ripetendo il comando s. In alternativa, M-s permette di scegliere la posizione desiderata da un menu temporaneo.
I file sorgenti da visualizzare sono quelli il cui nome è specificato nel riferimento e che si dovrebbero trovare o nella directory che contiene il PO (/.) oppure nella directory immediatamente superiore (/..). Qualora così non fosse, è possibile aggiungere (S) o rimuovere (M-S) delle directory al cosiddetto ‘percorso di ricerca’ dei sorgenti.
Considerazioni molto simili si applicano ai cosiddetti ‘file ausiliari’, cioè ai PO dello stesso programma tradotto in altre lingue che possono essere d'aiuto al traduttore nel caso di lingue conosciute. Questi, per poter essere consultati, devono essere aperti in Emacs, specificati nella lista degli ausiliari (A), dalla quale possono essere rimossi con M-A. In seguito, una volta tornati sul buffer in cui era in corso la traduzione, possono essere consultati con il comando a (che passa da un file ausiliario all'altro in ciclo) oppure può essere specificato il file ausiliario da consultare con C-c C-a. In ogni caso, grazie all'univocità del msgid, il cursore si posizionerà sul messaggio corrispondente.
In terzo luogo, il po-mode mette a disposizione dell'utente anche un'utilissima funzionalità di convalida del valoro svolto, con il comando V. Così facendo,l'utilità msgfmt verrà lanciata in modalità ‘prolissa’ in parallelo a Emacs, restituendo il controllo del PO al traduttore e visualizzando l'output del comando di compilazione in un nuovo buffer chiamato, appunto, *compilation validation* in una nuova finestra.
Qualora dovessero essere rilevate, sia a livello di file che di singolo messaggio, delle situazioni di errore, verrà visualizzato il numero, la natura e la riga dove tali errori sono localizzati. È possibile ‘navigare’ da una posizione di errore all'altro con il comando C-x `, correggerli con le azioni consentite dal po-mode, salvare il documento e ripetere la convalida.
Si ricorda che l'ultima modifica al PO può essere annullata in qualsiasi momento con il comando _. Al termine della traduzione è possibile lasciare l'ambiente di lavoro con i comandi Q o q che, prima di causare la chiusura del programma, salvano definitivamente i cambiamenti apportati al PO (il secondo comando chiede conferma prima di uscire). A differenza della semplice chiusura del buffer contenente il PO, questi comandi controllano anche l'eventuale presenza di messaggi non tradotti o fuzzy (non considerata un errore da msgmerge) e chiedono ulteriore conferma se sono state fatte delle modifiche dopo l'ultima convalida.
Rispetto agli editor di PO che si analizzeranno nel seguito di questa sezione, Emacs può considerarsi sul gradino più basso in quanto manca di una vera e propria ‘interfaccia di astrazione’ e dà accesso diretto (quantomeno visivamente) al testo sorgente PO. Questo comporta senz'ombra di dubbio molti vantaggi, ad esempio la visualizzazione di tutte le informazioni presenti nel file di partenza (tutti i tipi di commenti, flag di stato, riferimenti) senza però correre il rischio di alterare accidentalmente la sintassi PO grazie alla distinzione fra le aree modificabili e quelle di sola lettura nel documento.
Le funzionalità del programma non sono per nulla sminuite dalla sua posizione ‘inferiore’ in un'ideale scala di astrazione; al contrario Emacs dispone di un meccanismo molto rapido ed efficiente per avere accesso ai sorgenti e ai file ausiliari. Inoltre, integra al proprio interno funzionalità di QA molto utili che sono invece assenti in tutti gli editor off-line con i quali msgfmt deve essere invocato a parte e ‘a mano’.99
L'assenza di integrazione con TM rende l'inserimento di questa soluzione fra gli strumenti CAT/TM in senso stretto alquanto forzata. Tuttavia, si tratta di una ‘incompletezza’ solo apparente: come il lettore attento ricorderà gli strumenti dell'infrastruttura GNU Gettext risolvono egregiamente questo problema mediante l'uso dei compendia (su cui si è insistito nelle sez. 2.4.1 e 2.4.2). E non si tratta di un caso, dal momento che GNU Emacs con il po-mode è stato concepito nell'ambito dello stesso progetto, il progetto GNU, cui si deve la creazione di GNU Gettext.100
Concludendo, quel che si è detto è un riassunto molto stringato che non scalfisce nemmeno la superficie delle infinite potenzialità di un editor come Emacs. Parimenti, sulle estensioni del po-mode ci si è limitati a fornire la prospettiva ‘del traduttore’ e a mettere in risalto le funzionalità simili agli altri strumenti CAT. Per tutti i (dovuti) approfondimenti si rimanda al manuale di GNU Gettext (in inglese), qui riferito come [GNU Project, 2010a]. Parte di questa sintesi è basata inoltre su [Ferretti, 2004].
3.3.4 Lokalize
motto di Lokalize
| Autore: | Nick Shaforostoff |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://userbase.kde.org/Lokalize |
| Versione: | 1.1 (maggio 2010) |
Lokalize è lo strumento per la traduzione assistita e la localizzazione integrato all'interno del desktop KDE4. Assieme al suo predecessore per le versioni 3.x dell'ambiente grafico, KBabel, è anche lo strumento principale utilizzato dalla comunità per la localizzazione di questo desktop environment molto diffuso.
Come la quasi totalità delle applicazioni del parco software di KDE, Lokalize è scritto in C++ e utilizza le librerie grafiche Qt. La sua vocazione principale è la manipolazione dei file PO e POT utilizzati per la localizzazione del SL, ma il formato di elaborazione interno è lo standard bilingue XLIFF, supportato anche in ingresso per la traduzione. Questo, unito al fatto che integra dei filtri interni, lo rende compatibile anche con i file in formato ODF.101
L'installazione del programma non è diversa dall'installazione di una qualsiasi applicazione per KDE. In un sistema Debian GNU/Linux, o derivato, è sufficiente installare il pacchetto lokalize o il metapacchetto kdesdk per avere in modo automatico i file del programma e tutte le dipendenze. In alternativa, è sempre possibile procurarsi i sorgenti e compilare il programma, se si è in possesso delle competenze del caso.
L'interfaccia grafica di Lokalize, integrata alla perfezione in KDE4 e interamente localizzata in italiano,102 è organizzata in una serie di schede diverse a seconda del tipo di operazione. Le schede hanno barre degli strumenti e menu diversi, e anche quando un menu fosse presente in più schede, non sempre le voci al suo interno sono le stesse. Essenzialmente i tipi di schede sono tre: una ‘Vista globale del progetto’ (F4), una ‘Memoria di traduzione’ (F7) e la scheda di traduzione (una per ogni file aperto in modifica). Le schede, inoltre, possono essere chiuse in qualsiasi momento con Ctrl-W.
La distinzione delle schede in tre categorie comporta l'indubbio vantaggio di non visualizzare tutti gli elementi ‘sempre e comunque’ anche quando non ce n'è alcuna necessità e contribuisce quindi alla ‘pulizia’ e all'ordine del programma (che nelle applicazioni Qt/KDE specie di ‘vecchio stampo’ ha tradizionalmente rappresentato un problema, cfr. sez. 3.3.7).
A differenza della maggior parte degli strumenti CAT finora considerati (a eccezione di OmegaT), l'unità di lavoro di Lokalize non è rappresentata dal singolo file bensì da progetti. I file possono essere aperti per la traduzione o per la revisione anche individualmente ma è utilizzando i progetti che si sfruttano appieno le funzionalità del programma.
La creazione di un nuovo progetto (Progetto/Crea nuovo progetto) è un'operazione molto potente e assistita da una comoda procedura guidata. Se si traducono documenti ODF, è possibile caricarne uno oppure una cartella contenente più file. Questi vengono convertiti in XLIFF dal filtro interno di Lokalize e, al termine della traduzione, è possibile riconvertirli nel formato originale da Strumenti/Converti in ODF.
Se invece si traducono file dell'interfaccia di KDE, il programma chiederà la posizione della ‘cartella della lingua’, cioè della directory che contiene i messaggi di interfaccia e di documentazione della lingua verso cui si traduce (se si gestisce in maniera autonoma la sincronizzazione con il deposito Subversion di KDE). In alternativa, Lokalize è in grado di sincronizzarsi in modo automatico dal sistema di controllo versione di KDE scaricando i file necessari alla localizzazione.
Una volta creato il progetto, nella relativa directory radice sarà creato anche un file index.lokalize (contenente alcuni metadati) che, se selezionato per l'apertura dall'interno del programma, permette di riaprire il progetto in un secondo momento. Qualora fosse necessario, invece, le impostazioni possono essere modificate in un secondo momento dal menu Progetto/Configura progetto.
Fra queste impostazioni si ricorda la posizione del file di terminologia, le directory contenenti i modelli (‘PO template’), i file tradotti in lingua d'arrivo e le traduzioni alternative (traduzioni in altre lingue per la consultazione). Il progetto alla base del lavoro con Lokalize è talmente importante che se si apre un file senza progetto, il programma cerca il relativo index.lokalize per quattro livelli superiori di directory superiori; se e solo se nessun file di questo tipo viene trovato, il programma si aprirà come editor di PO sul singolo documento, applicando le impostazioni predefinite.
I file di progetto che devono essere tradotti sono visualizzati nella scheda Vista globale del progetto in cui, dopo ogni salvataggio, vengono mostrate le statistiche sul lavoro da fare. Sono visualizzati quindi i file di progetto, ciascuno corredato dal numero di segmenti tradotti, non pronti (fuzzy) e tradotti (approvati), la data dell'ultima revisione del modello, la data dell'ultima modifica e il nome dell'ultimo traduttore. Nel caso in cui si lavorasse con tutto l'albero di SVN per l'italiano copiato nel disco rigido questa vista si rivela estremamente efficiente.
In questo tipo di scheda, la finestra principale presenta solo le funzionalità consentite a livello di progetto. Ad esempio, nel menu Strumenti non sono più presenti le azioni Ortografia e Conteggio parole tipici della tipo di scheda di traduzione, dal momento che (purtroppo) è possibile svolgere tali operazioni solo a livello di singolo file. Il menu Vai, invece, non mostra le opzioni per la navigazione a livello di segmento, bensì a livello di file (es. successivo non vuoto ma non pronto, precedente solo traduzione, successivo solo modello).
I file della lista globale di progetto possono essere aperti per la modifica e la traduzione facendo clic sulla riga corrispondente. Questo causa l'apertura di una nuova scheda di traduzione, divisa in un numero variabile di aree che può arrivare al massimo fino a dieci. Fra queste, le principali sono: campo sorgente, campo destinazione, unità di traduzione (cioè la lista delle stringhe), area commenti, TM e glossario. Le rimanenti sono utilizzate per scopi particolari, come la sincronizzazione o per visualizzare le traduzioni alternative presenti nel documento di partenza, e verranno trattate con maggiori dettagli in seguito.
In una scheda di traduzione possibile navigare da un messaggio al successivo o al precedente, all'inizio o alla fine del documento, fra quelli non pronti o non pronti ma non vuoti, e così via. Dal momento che a ogni messaggio è assegnato un identificativo, è possibile spostarsi anche in maniera non sequenziale per numero o per segnalibro, dato che è possibile assegnare anche dei segnalibri ai messaggi (validi, però, solo all'interno dello stesso documento).
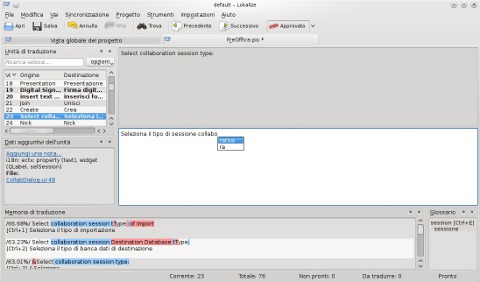 |
La lista delle stringhe, inoltre, può essere utilizzata per ‘filtrare’ i messaggi all'interno di un documento inserendo un'espressione di ricerca e mostrando, in base alle opzioni selezionate, solo i messaggi aventi un determinato status (pronto, non pronto, modificato) che contengono l'espressione in uno dei loro campi (origine, destinazione, note, numero di voce, ecc.).
In Lokalize i messaggi possono essere classificati come tradotti o non tradotte (e, in quest'ultimo caso, vuoti o fuzzy). In quest'ultima categoria di messaggi, il testo del segmento tradotto viene mostrato in corsivo. Nel caso dei file XLIFF è possibile accedere a degli stati aggiuntivi (es. ‘richiede adattamento’, ‘richiede localizzazione completa’, ‘richiede revisione della traduzione’) dal pulsante Approvato presente nella barra degli strumenti. Il cambiamento di stato dopo la modifica dipende dal ruolo dell'utente nel progetto di traduzione (traduttore, revisore o certificatore in base alle impostazioni di progetto). Se ad esempio si è traduttori è possibile impostare che tutti i messaggi modificati siano automaticamente ‘approvati’ o no dal menu Impostazioni/Configura Lokalize.
Durante la fase di traduzione, il testo di partenza viene visualizzato nel campo relativo al segmento di partenza, con evidenziazione dei tag e delle entità XML (trattati come placeable). I termini presenti nel glossario, invece, anche se riconosciuti non sono evidenziati e il loro inserimento nel campo di modifica prevede una tecnica diversa.
L'inserimento dei tag è facilitato e in particolare, sono disponibili due possibilità: Inserisci tag, che apre un menu contestuale alla posizione del cursore nel campo di modifica e permette di scegliere dall'elenco di tutti i tag presenti nel segmento di partenza qual è quello che si desidera inserire (anche se il tag è solo uno), e Inserisci tag successivo, che invece dà per scontato che l'ordine dei tag non sia stato alterato per cui in modo automatico recupera il tag successivo a quello appena utilizzato o del primo (se all'inizio del segmento). In ogni caso l'inserimento del tag provoca lo spostamento automatico del cursore nel punto dove deve continuare l'inserimento del testo, cioè dopo il tag.
Da questo punto di vista, inoltre, è notevole osservare che Lokalize è ‘consapevole’ di quali siano i tag utilizzati nel campo di modifica fino al punto di inserimento, per cui tende a presentare sempre la scelta ‘giusta’ (come tag successivo o posizionando la selezione nel menu contestuale) anche in caso di lievi alterazioni dell'ordine il che, se si usa il menu a comparsa, rende molto difficile l'omissione dei tag.103
Un altra piccola ma utile ottimizzazione è l'evidenziazione di tutti gli spazi presenti all'inizio (leading spaces) e alla fine (trailing spaces) delle stringhe che compongono un messaggio in modo che il rischio di errore sia minimo, dal momento che in un file PO le stringhe racchiude fra apici doppi afferenti allo stesso messaggio, come si è visto, saranno concatenate.
Altre due funzionalità utili al momento dell'immissione della traduzione sono l'autocompletamento delle parole durante la digitazione, che tiene traccia dei termini che sono stati utilizzati nel progetto attuale o in quelli precedenti e la correzione automatica durante la digitazione. Se il dizionario degli autocompletamenti non è personalizzabile, la lista del correttore ortografico può essere invece estesa con l'opportuna opzione del menu a comparsa.
Il comportamento predefinito di Lokalize,Le TM locali di progetto nelle ultime versioni, prevede la creazione di una nuova TM ogni volta che viene aperto un nuovo progetto, con lo stesso nome di quest'ultimo per permetterne una più facile identificazione. I file di TM sono database in formato SQLite e sono memorizzate nella directory contenente i dati locali del programma.104 Anche se le TM del programma possono essere un numero arbitrario, di fatto durante l'elaborazione di un progetto viene usata solo la TM di progetto (omonima), è solo da questa che vengono recuperate le corrispondenze ed è l'unica che può essere consultata dall'utente: per questo motivo, d'ora in avanti si parlerà di ‘memoria’, o ‘TM’, al singolare.
Le impostazioni della TM sono visibili dal menu Strumenti/Gestisci le memorie di traduzione. A partire dalla finestra di dialogo associata a questa funzione è possibile creare nuove TM se necessario, mentre per l'eliminazione al momento l'unica soluzione sembra essere la cancellazione ‘brutale’ dei due file associati alla TM (il database e le impostazioni dello stesso).
Sebbene questo formato per le memorie sia non standard e difficilmente accessibile, è prevista la possibilità di importazione ed esportazione da/verso il TMX per facilitare l'interoperabilità fra strumenti e prendere parte a progetti di localizzazione di cui siano già disponibili file TMX con il lavoro pregresso.
Oltre che da file TMX, è consentito importare dati anche da intere directory contenenti file PO o, in alternativa, è possibile trascinare i suddetti file nell'area della finestra del programma contenente le corrispondenze della memoria per avviare in automatico la procedura di importazione. Anche questo è un ottimo sistema per recuperare le traduzioni esistenti in un progetto, ad esempio KDE stesso, se si importano i PO creati dagli altri traduttori nello stesso ramo in cui ci si inserisce.
I fattori utilizzati ai fini del calcolo delle corrispondenze in TM sono il rapporto fra la lunghezza comune (massima sottosequenza comune) e totale, la lunghezza delle parti presenti o assenti e il numero di aggiunte o eliminazioni che vi sono nei due messaggi. La soglia di corrispondenza minima è fissata al 35%, che non è configurabile ma rappresenta (al pari del 30% in OmegaT) un valore abbastanza basso per non escludere risultati potenzialmente significativi. Inoltre il numero di risultati massimo visibile può essere configurato e questo riduce in modo sensibile i fattori di ‘disturbo’.
La politica di Lokalize nell'utilizzo della memoria può essere comunque configurato, in maniera parziale, dalla finestra di dialogo delle impostazioni. Ad esempio, è possibile abilitare o disabilitare la consultazione automatica della TM, il numero massimo (da 0 a 99) di suggerimenti che possono essere visualizzati, se aggiungere alla TM i messaggi modificati e se aggiungere automaticamente alla TM tutti i file aperti nel programma, anche se non sono stati modificati.
Le corrispondenze recuperate dalla TM appaiono durante la fase di traduzione nella relativa area della finestra principale, disposte in ordine decrescente di somiglianza e con le differenze rispetto al segmento di partenza evidenziate (rosso per le parti mancanti, blu per le parti in esubero, entrambi i colori se diverse). L'inserimento nel campo di modifica è possibile con Ctrl-1, Ctrl-2, ecc.
Se all'interno del segmento sorgente del messaggio sono presenti dei numeri e la corrispondenza in memoria differisce solo per quei valori, viene comunque applicata una penalità minima, tuttavia in fase di inserimento nel campo di modifica il programma riconosce che la differenza è costituita solo dalla sequenza di cifre e opera in automatico la sostituzione (o l'eliminazione). In genere questo riduce al minimo, se non elimina proprio, la necessità di intervento manuale del traduttore.105
La TM in uso può anche essere interrogata dalla scheda di consultazione della memoria (F7). Questo consente di effettuare delle ricerche sul contenuto, sulla base della presenza nel segmento di partenza o d'arrivo delle stringhe di ricerca specificate come sottostringhe, in ‘stile Google’ (cioè come parole chiave) oppure con l'utilizzo di uno o più caratteri jolly (asterischi) al posto di sequenze arbitrarie di caratteri (non è supportata la notazione delle espressioni regolari).
Dal momento che le TU di tutte le memorie contengono informazioni anche sul file da cui è stato preso il segmento (con relativo percorso assoluto), le ricerche possono essere ulteriormente raffinate inserendo un modello di nome file (contenente asterischi per le parti non soggette a vincoli) oppure invertendo l'esito positivo/negativo. Facendo clic su una delle voci nella lista dei risultati della ricerca, sarà aperto il file contenente il messaggio selezionato in una nuova scheda di traduzione.
Una ricerca nella TM può essere effettuata (sulla base di stringhe) anche selezionando una qualsiasi porzione di testo nel campo sorgente o nel campo di modifica di una scheda di traduzione e facendo clic sulla voce Cerca testo selezionato nella memoria di traduzione del relativo menu a comparsa.
L'approccio di Lokalize alle memorie è molto vantaggioso: in primo luogo perché permette di separare le memorie di progetti diversi, evitando di creare inutili commistioni (in questo si oppone diametralmente a Virtaal e a Gtranslator). Se e soltanto se l'utente lo desidera, è possibile trasferire dati da una TM all'altra, esportando i dati in formato TMX e reimportandoli in quella di progetto.
Dato che non è possibile utilizzare TM in sola consultazione, sarebbe però utile poter esportare in maniera selettiva solo alcune TU, caratteristica che non è stata (ancora) implementata. A questo problema può essere tuttavia posto rimedio importando i messaggi dai documenti tradotti, dal momento che Lokalize supporta l'importazione diretta da PO.
Diverso è invece il discorso per quanto riguarda l'importazione da TMX. Nonostante, infatti, quest'ultimo sia un formato standard, al momento Lokalize importa ed esporta correttamente solo una sottovariante non standard del TMX, cosa evidente già dall'elemento radice del documento, <tmx version="2.0"> (non esiste allo stato attuale un TMX 2.0 poiché l'ultima versione disponibile è la 1.4b, v. appendice A.1). Ne consegue che Lokalize importa correttamente solo TMX generate da se stesso.
Per l'esportazione vale il viceversa: importando i TMX di Lokalize in altri programmi compatibili con lo standard (es. OmegaT) queste vengono ignorate o si ottengono messaggi di errore. L'unica soluzione sembra, al momento, convertire le TM in formato PO come già visto e utilizzare quest'ultimo file se il programma consente l'importazione da PO per le memorie. In alternativa, è possibile utilizzare un front-end all'infrastruttura Okapi (Rainbow o tikal) per trasformare da TMX… a TMX (sic!) ottenendo però un file standard che può essere importato.106
Lokalize offre anche il supporto alle risorse di terminologia in formato TBX. È possibile salvare tutta la terminologia di progetto in un file presente in una delle directory di progetto (in genere terms.tbx nella radice stessa del progetto). Un database terminologico può anche essere condiviso fra più progetti o, cosa spesso più comoda, è possibile copiarlo nelle directory di più progetti.
Le voci riconosciute nel database (solo corrispondenza esatta, senza riconoscimento di unità morfologiche) sono mostrate nell'apposita area della finestra principale, e il loro inserimento è facilitato da combinazioni da tastiera (es. Ctrl-E per il primo termine, Ctrl-H per il secondo, e così via).
I glossari di Lokalize riconoscono correttamente campi come il dominio e la definizione, a livello di voce terminologica (TE), non di termine o di lingua. È possibile anche l'inserimento di sinonimi sia in lingua di partenza che in lingua d'arrivo: nel primo caso, a riconoscimento avvenuto durante la traduzione, l'area di glossario mostra solo il termine originale presente nel segmento, nel secondo caso invece tutti i sinonimi in lingua d'arrivo sono mostrati nella finestra e alla pressione della scorciatoia per l'inserimento si aprirà un menu a comparsa simile a quello dei tag per la selezione del termine desiderato.
Una delle funzionalità che rende Lokalize molto valido per quanto riguarda la gestione della terminologia è l'interfaccia di consultazione e modifica del glossario, accessibile da Strumenti/Glossario (Ctrl-Alt-G). Attraverso questa interfaccia è possibile non solo creare nuove voci, ma anche visualizzare quelle esistenti, apportarvi delle modifiche e cancellarne alcune. Inoltre, è possibile una funzionalità di ricerca di base (per sottosequenza di caratteri) in tutto il glossario sulla base al termine in lingua di partenza.
 |
L'aggiunta di termini al glossario, oltre che dalla finestra di dialogo per la consultazione, può anche essere effettuata in modo facilitato selezionando un termine nel campo sorgente o nel campo destinazione (o in entrambi) e attraverso il menu Modfica/Glossario/Inserisci nuovo termine. Le espressioni selezionate sono copiate nei campi dei termini già nella posizione corretta in base al segmento in cui sono state selezionate.
Volendo esprimere alcune considerazioni sul supporto ai glossari, per certi versi Lokalize dimostra di essere un passo avanti agli altri programmi CAT considerati in questa sezione. In primo luogo, permette di inserire informazioni orientate al concetto, con campi che si applicano a livello di voce terminologica (dominio e definizione), anche se forse si tratta di un approccio un po' radicale, per chi proviene da altri modelli di gestione della terminologia, cui può sembrare una mancanza l'impossibilità di inserire commenti relativi al solo termine in lingua d'arrivo.
In secondo luogo, anche il supporto ai sinonimi in entrambe le lingue è un grande punto a favore del programma, così come la possibilità di copiare i termini nel campo di modifica interamente da tastiera e, viceversa, di inserire con facilità nuovi termini nel glossario selezionando le espressioni interessate.
Notevole è anche l'interfaccia di consultazione e di modifica al glossario interna al programma, unica nel suo genere e dotata di funzionalità abbastanza complete (ricerca, creazione, modifica, eliminazione) che evita, per progetti di piccole dimensioni, di ricorrere a strumenti esterni ancora disponibili in maniera troppo limitata nel SL.107
Non si può mancare, tuttavia, di evidenziare alcune lacune, di lieve entità ma anche più serie. In primo luogo, la possibilità di utilizzare un solo glossario per progetto è per certi versi limitante, soprattutto in virtù del fatto che non esiste la possibilità di importare nuovi glossari in quello predefinito (né TBX né in alcun altro formato).
Da questo punto di vista, Lokalize rispecchia lo ‘scarso’ supporto allo standard TBX presente in tutto il panorama del SL: con gli strumenti del TTK ad esempio è possibile ottenere file TBX solo da CSV, se si dispone di un PO di terminologia è possibile utilizzare prima po2csv quindi csv2tbx (cfr. 4.2.2) per ottenere il glossario.
Dato che la fusione di più glossari in TBX non è possibile in maniera automatizzata, si potrebbe pensare di utilizzare msgcat su PO di terminologia. Questo però si scontra con la difficoltà di conversione da TBX a PO: non esistono strumenti ‘diretti’ nel TTK e Okapi non dispone (ancora) di un filtro per il TBX per cui non rimane altra opzione che interpretare il file come XML generico ai fini della conversione, ottenendo un PO di terminologia con il comando tikal -fc okc_xml -2po terms.tbx. Ciò comporta, però, non solo la perdita di tutti i metadati (creatore, data di creazione, ecc.) ma, peggio ancora, il documento viene letto come se fosse monolingue per cui definizioni e domini compaiono in veste di nuovi termini, così come gli equivalenti in lingua d'arrivo. In sostanza, l'unico sistema è intervenire ‘a mano’ sui file cercando di non alterarne la sintassi (ad esempio con un editor dedicato, cfr. 4.2) e ricorrendo a strumenti di validazione (cfr. 4.3).
Un ulteriore, e ultimo, aspetto problematico del supporto alle risorse terminologiche in Lokalize è la mancanza di strumenti di analisi morfologica che permettano di riconoscere i termini anche se questi non appaiono nella loro forma di citazione. Questo limita in modo abbastanza significativo l'utilità di avere una gestione dei glossari per altri aspetti così avanzata e non resta che auspicare che le future versioni del programma implementino la nuova caratteristica.
Lokalize integra invece funzioni molto avanzate di ricerca e sostituzione all'interno del file aperto per la traduzione, anche con supporto alle espressioni regolari e con un comodo assistente per la creazione delle stesse. In questo tipo di ricerche è inoltre possibile ignorare o includere i tag (chiamati in questo contesto ‘marcatori’) e gli acceleratori.
Ricerche, ma non sostituzioni, più veloci e meno accurate possono essere svolte anche semplicemente dall'area della finestra principale contenente la lista delle stringhe. Non è possibile (al momento) eseguire sostituzioni sul contenuto di tutti i file di un progetto, mentre per le ricerche (con un'interfaccia meno avanzata ma comunque molto valida) è sempre disponibile la scheda di consultazione della TM, qualora le TU dei file di progetto siano state già aggiunte al database dei segmenti.
Un'altra utile funzione, disponibile solo a livello di singolo file ma non di progetto è la correzione ortografica interattiva, distinta da quella in fase di digitazione, grazie alla quale è possibile passare in rassegna tutti gli errori ortografici alla fine della traduzione.
Al pari del controllo ortografico, anche le statistiche e il conteggio parole sono disponibili solo a livello di file. Per i file di ciascun progetto è possibile vedere il numero di segmenti totali, tradotti, fuzzy (non pronti) o da tradurre nella vista globale del progetto. Nelle schede di traduzione dei singoli file questi dati sono replicati in basso nella barra di stato e, per i messaggi da tradurre e non pronti, è visualizzata la percentuale sul totale dei messaggi. Da Strumenti/Conteggio parole è possibile invece vedere quante sono le parole dell'originale e quelle utilizzate per la traduzione del documento.
Purtroppo, non è possibile avere dall'interno del programma informazioni di questo tipo relative all'intero progetto: sarebbe necessario unire i file PO a parte e utilizzare pocount. Parimenti, non è possibile avere in anticipo delle statistiche ponderate sulla presenza di corrispondenze per i messaggi in TM. Anche in questo caso non resta che affidarsi a strumenti esterni (pot2po) con l'inconveniente, però, che il calcolo delle corrispondenze dal database SQLite in Lokalize funziona in modo diverso rispetto alle corrispondenze ottenute dal TTK.
Al momento, Lokalize non supporta l'integrazione con motori di traduzione automatica, una funzionalità che può essere ottenuta utilizzando opportuni script. È sempre possibile però utilizzare gli strumenti ‘multiuso’ a disposizione di ogni traduttore di SL. La pretraduzione può essere svolta con facilità con un front-end a Okapi connesso all'API di Google Translate o di uno qualsiasi dei servizi di MT disponibili, ad es. tikal -t google <file.po>. Collocando questo file nella cartella delle traduzioni alternative (v. Progetto/Configura progetto) durante la traduzione nell'area delle ‘traduzioni alternative’ nella finestra principale verrà visualizzato messaggio per messaggio l'output della MT.
Ciò non toglie la grande importanza e possibilità di personalizzazione che l'uso di script conferiscono a Lokalize. Sono supportati script in diversi linguaggi interpretati, tra cui Python, JavaScript e Ruby che possono anche essere condivisi a livello di progetto con gli altri traduttori. Tramite opportuni script è possibile sopperire alle funzioni di QA e, sempre utilizzando uno script, è possibile visualizzare i sorgenti delle applicazioni da localizzare con un semplice clic.
Lokalize è compatibile, come si diceva con il formato bilingue XLIFF per la traduzione. Se è aperto per la traduzione un file di questo formato, sono disponibili alcune funzionalità aggiuntive. Ad esempio è possibile avere accesso a tutti gli ‘stati estesi’ dei messaggi, che vanno ben al di là del ‘tradotto’, ‘non pronto’ e ‘non tradotto’ dei PO.
Tramite un filtro interno XLIFF è possibile convertire automaticamente documenti ODF in XLIFF e viceversa al termine del lavoro, e questo, nelle intenzioni dello sviluppatore, è sufficiente a proiettare Lokalize all'interno del gruppo di strumenti CAT generici.
Sotto certi punti di vista, il supporto allo XLIFF è sufficiente per estendere l'ambito di applicazione del programma in maniera considerevole: esistono convertitori in XLIFF disponibili come SL molto potenti e intuitivi (tikal o i pacchetti di traduzione creati con Rainbow, cfr. sez. 4.4.1) che permettono l'estrazione e la riconversione nel formato originale di molti documenti, garantendo così la massima portabilità.
Tuttavia Lokalize mostra qualche problema nell'operare con file prodotti da strumenti esterni, in particolare, in certi casi è necessario rinunciare alle comode funzionalità offerte dai progetti. Anche il convertitore interno non sempre funziona come dovrebbe, e può portare crash improvvisi dell'applicazione o a nessuna conversione. Se si usa quest'ultimo sistema, inoltre, non è possibile avere attualmente accesso a regole di segmentazione in SRX personalizzate (aspetto che può essere vitale in ambito professionale), cosa che invece è molto facile da ottenere con Okapi.
Una funzionalità di Lokalize unica nel suo genere è la sincronizzazione/fusione, volta a facilitare il compito dei revisori e dei project manager, da qui in avanti inteso in senso lato come i coordinatori dei progetti di localizzazione, piuttosto che quello dei localizzatori.
Semplificando, tramite questa funzione è possibile aprire un documento, la fonte di sincronizzazione o di fusione, che rappresenta la versione precedente del file di risorse in traduzione (nel caso della sincronizzazione) o una traduzione nella stessa lingua operata da un altro traduttore del file attuale (nel caso della fusione) in modo da riunire le differenze e produrre un documento unico. A questo scopo, Lokalize mette a disposizione due aree della finestra, chiamate ‘Sincronizzazione primaria’ e ‘Sincronizzazione secondaria’ il cui funzionamento non mostra però sostanziali differenze.
In pratica, la modalità di sincronizzazione permette di risparmiare tempo quando è necessario mantenere lo stesso file di localizzazione in due rami diversi, es. branches/stable/l10n-kde4 e trunk/l10n-kde4 nel caso del deposito SVN di KDE, e un file PO di quest'ultimo subisce un aggiornamento o una modifica.
Lokalize permette di visualizzare immediatamente le differenze parola per parola fra i due documenti (in questo caso nel campo msgid) e di navigare solo fra i messaggi che hanno subito modifiche. Le nuove traduzioni inserite sono memorizzate nel file più recente, ma vengono anche replicate (sincronizzazione) nel file precedente. In questo modo è possibile operare le modifiche in una sola volta su più rami del progetto di traduzione.
Il sistema di per sé ha delle enormi potenzialità ma aggiorna i file, ovviamente, solo nella propria copia locale del deposito SVN. Se non si ha accesso in scrittura allo stesso, com'è il caso della maggior parte dei traduttori, i documenti tradotti devono comunque essere inviati ai responsabili con i privilegi di accesso in scrittura a SVN, vanificando in parte l'utilità della sincronizzazione.
La modalità di fusione, invece, è utile quando più traduttori lavorano sullo stesso file, per confrontare il lavoro in modo veloce ed efficiente, producendo un file unico finale. La fusione, in questo senso, è utile anche per i certificatori, cioè i responsabili della QA, quando la traduzione è stata svolta da un nuovo arrivato in modo da assicurare la qualità del lavoro.
Oltre alla sincronizzazione, Lokalize offre numerosi altri vantaggi per i localizzatori che sfruttano il formato PO. Ad esempio, è possibile consultare in modo automatico le traduzioni che sono già state effettuate in un'altra lingua (traduzioni alternative), se la somiglianza con quella di destinazione è d'aiuto (e non di intralcio) per l'utente.
Un altra ottimizzazione consiste nell'aggiornamento dell'intestazione PO con i dati del traduttore, effettuato in automatico quando il documento tradotto viene salvato. Anche le forme plurali vengono gestite correttamente, con lo sdoppiamento delle aree campo sorgente e campo di modifica.
Per quanto riguarda la visualizzazione dei commenti, nell'area dedicata sono visualizzati i commenti estratti automaticamente e i commenti del traduttore. Anche i riferimenti al codice sorgente sono visualizzati, sotto forma di ‘link’ che, se è installato nel progetto lo script opportuno, permettono di accedere alla posizione del sorgente in un clic.108
I contesti di disambiguazione sono visualizzati nell'area dei commenti, sotto l'etichetta ‘Contesto’ e, nel caso di messaggi fuzzy creati da msgmerge, il testo del campo di modifica è visualizzato in corsivo come in tutti i messaggi non pronti, mentre i campi identificativi precedenti sono visibili nell'area della finestra riservata alle ‘traduzioni alternative’ (non molto intuitivo). I flag sul formato delle variabili, invece, non sono visualizzati affatto, ma vista la loro utilità relativa per il traduttore umano (vengono letti principalmente da msgfmt), questa non può essere considerata una carenza.
Il più evidente difetto di Lokalize, tuttavia, è la totale assenza di verifiche di QA, una funzionalità che invece era presente (e molto apprezzata) in KBabel: non è possibile infatti avere nemmeno i più ‘elementari’ controlli di sintassi e di validità ottenibili da msgfmt. Per il momento, questo può essere eseguito solo con script ad hoc che richiamano la nota utilità di GNU Gettext ma si tratta di soluzioni ancora temporanee.
Manca ancora il supporto a tutti i controlli ottimizzati per il formato PO di pofilter e, come riconosce l'autore stesso, allo stato attuale non è implementata nemmeno la possibilità di un controllo di coerenza terminologica sul rispetto del glossario o sull'uso di termini ‘non permessi’.
In conclusione, Lokalize si rivela essere uno strumento dalle enormi potenzialità e uno dei migliori, se non in assoluto il migliore editor di PO disponibile come SL. Si tratta, sotto la maggior parte degli aspetti di uno strumento CAT abbastanza completo da essere impiegato anche al di fuori della localizzazione del solo ambiente desktop KDE ma anche per altri progetti di SL e, perché no, anche per scopi generici.
Lokalize si distingue non solo per la presenza di macro-funzionalità più evidenti e uniche nel suo genere, ad esempio la modalità di fusione, l'interfaccia per la creazione di glossari, la possibilità di sincronizzarsi con l'albero SVN dei modelli di traduzione o la personalizzazione totale anche tramite script dell'utente: sono anche tanti piccoli dettagli a fare la differenza.
La razionalizzazione dell'interfaccia, che si adatta in base al contesto e non sovraccarica mai l'utente senza per questo rinunciare alle funzionalità e alla configurabilità che da sempre contraddistingue tutte le applicazioni Qt/KDE; le ricerche avanzate in memoria, che permettono anche di risalire al file da cui sono state generate le TU; il calcolo delle corrispondenze in TM con un algoritmo in grado di ottimizzarne lo sfruttamento; la sostituzione automatica dei numeri in fase di recupero delle corrispondenze; l'evidenziazione degli spazi all'inizio e alla fine delle stringhe; l'inserimento dei tag con menu intelligenti e i glossari orientati al concetto con supporto ai sinonimi sono solo alcuni dei numerosi vantaggi che si hanno utilizzando il programma.
Perfino le numerose scorciatoie da tastiera, con cui è possibile svolgere quasi tutte le operazioni senza staccare le mani dalla tastiera, sono totalmente configurabili dall'utente.109
Esiste anche il rovescio della medaglia: la mancanza di supporto alla QA anche più semplice, oppure il riconoscimento solo su ‘corrispondenza esatta’ delle voci di glossario rappresentano ancora potenziali limiti all'utilizzo del programma. Purtroppo fra gli svantaggi va annoverata anche la qualità della documentazione. Il programma è corredato infatti da un manuale disponibile sia in inglese che in italiano [Shaforostoff, 2010], tuttavia è innegabile che questa fonte di documentazione richieda ancora del lavoro per raggiungere un livello ottimale.
Il testo in alcuni punti dà l'impressione di voler guidare passo a passo il lettore, assumendo che questi non abbia alcuna esperienza di traduzione assistita o di traduzione in generale, mentre in altri insiste con pedanteria su tecnicismi riguardanti gli aspetti della gestione di complessi progetti di localizzazione di software (come KDE), di interesse più per il project manager che per il normale traduttore.
Molti fra gli aspetti più rilevanti per chi ha anche un minimo di confidenza con la traduzione assistita o proviene da strumenti CAT proprietari sono dati interamente per scontati (gestione e manutenzione di TM e database terminologici, ottimizzazione nel riutilizzo delle TU e delle voci di glossario, dettagli sulla UI), ed è solo grazie all'uso che alcune delle (ottime!) funzionalità di Lokalize qui messe in evidenza vengono alla luce, quasi per ‘casualità’ perché nella documentazione non se ne fa menzione.
La precedente considerazione contrasta con gli standard molto elevati per la documentazione che contraddistinguono l'intero parco software KDE110 ed è molto probabile che la situazione migliorerà nel prossimo futuro. Infatti fermo rimane che Lokalize è un programma ancora relativamente giovane, essendo nato ‘solo’ nel 2007 con lo scopo di rimpiazzare KBabel che invece è stato il programma di localizzazione utilizzato per KDE (e non solo) a partire dal 1999.
3.3.5 Virtaal
| Autori: | F. Wolff, W. Winterbach, D. Bailey, W. Leibbrandt et al. |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://translate.sourceforge.net/wiki/virtaal/index |
| Versione: | 0.6.1 (giugno 2010) |
Virtaal è uno strumento di localizzazione stand-alone realizzato dagli sviluppatori di Translate.org.za, la stessa organizzazione che sta alla base del TTK ed è proprio sulla base dell'API del TTK che questo programma si fonda. Si tratta di uno strumento CAT dotato di interfaccia grafica realizzata con il toolkit GTK+ e interamente localizzato in italiano.111
Il nome del programma in Afrikaans è un gioco di parole che intende richiamare per assonanza sia il verbo vertaal ‘tradurre’ ma al tempo stesso l'espressione vir taal ‘per [la] lingua’.
Virtaal è inoltre scritto in Python, il che permette l'indipendenza dalla piattaforma e facilità di installazione ed esecuzione. In contesto GNU/Linux, la procedura è in genere ancora più semplice dal momento che la maggior parte delle distribuzioni che adottano la pacchettizzazione di binari precompilati ne permette l'installazione tramite il proprio gestore di pacchetti, con risoluzione automatica delle relative dipendenze.
Sebbene agli inizi del progetto, nel 2007, fosse rivolto in particolar modo ai localizzatori di SL e il suo campo principale di applicazione fossero i cataloghi in formato PO, il progetto si è andato via via allargando e il supporto è stato esteso non solo a molti formati tipici della localizzazione di SL, ma anche a scopi più generali. I formati di file supportati da Virtaal sono: PO e MO di GNU gettext, XLIFF (.xlf) e file di risorse per le interfacce in Qt (.ts, .qph) per la traduzione; TM in formato TMX e Wordfast (.txt); glossari sotto forma di TBX e nei formati tipici di OmegaT (.tab e .utf8).
Un aspetto molto positivo ai fini dell'ottimizzazione del lavoro che non può mancare di essere segnalato è l'attenta progettazione dell'interfaccia, che è molto semplice e permette di mantenere concentrata l'attenzione dell'utente su ciò che conta realmente, vale a dire il contenuto da tradurre. Tutte le funzioni principali possono essere realizzate per via grafica, ma il programma si contraddistingue soprattutto per le sue scorciatoie da tastiera, che una volta imparate, permettono all'utente di non distogliere lo sguardo dal segmento aperto per la modifica e non obbligano a spostare le mani dalla tastiera, incrementando così la produttività.
Virtaal, nella versione presa in considerazione ai fini di questo lavoro, non consente la creazione di progetti articolati ma adotta un approccio orientato al file singolo. L'apertura di un nuovo documento per la traduzione può essere effettuata dalla schermata di benvenuto visualizzata all'avvio del programma (o con Ctrl-O), dal proprio gestore di file (in quanto Virtaal viene automaticamente associato ai tipi MIME di competenza). In alternativa, è sempre possibile lanciare l'applicazione da riga di comando.
All'apertura del file, viene inizializzato il primo messaggio o la prima TU. Il programma mostra in alto le eventuali informazioni sul messaggio (es. se si tratta di un PO, i commenti relativi al messaggio), viene visualizzato il testo sorgente in un campo di testo protetto da scrittura ed è possibile digitare la traduzione nel campo di testo sottostante.
Diversamente da molti altri CAT esaminati, Virtaal non adotta la visualizzazione ‘in linea’ delle TU, alternando testo sorgente e testo di destinazione o mostrando solo quest'ultimo una volta che le stringhe sono state tradotte. La vista predefinita della finestra principale è invece a colonne: sulla sinistra si vedono i segmenti del testo di partenza e sulla destra il testo di arrivo.
In particolare, esistono tre modalità di navigazione:
- completa, in cui sono visualizzati tutti i messaggi, tradotti e non tradotti;
- incompleta, che restringe l'accesso solo alle unità non tradotte o marcate come fuzzy in modo da trovare con facilità i punti che necessitano dell'intervento del traduttore o del revisore;
- ricerca (F3), che visualizza soltanto i segmenti che corrispondono all'espressione di ricerca digitata sotto forma di testo semplice (distinguendo, se si seleziona la relativa casella di spunta, fra maiuscole e minuscole) o di espressione regolare.
Le TU, in ogni caso, possono essere aperte per la modifica una alla volta ed è possibile spostarsi da una TU alla successiva premendo Invio o con Ctrl-Giù. Alla pressione di uno di questi tasti la traduzione verrà memorizzata nella TM locale e si passerà alla modifica del segmento successivo.
Per aprire la TU precedente è possibile usare Ctrl-Su e gli spostamenti non sequenziali sono possibili cliccando una volta sul messaggio destinazione oppure con Ctrl-PagGiù e Ctrl-PagSu che causano spostamenti di più messaggi alla volta. Non è possibile, invece, ‘saltare’ a una determinata posizione specificando il numero della TU ma questo è ampiamente compensato dalla possibilità di navigazione in modalità ricerca.
 |
Per quanto riguarda l'inserimento della traduzione, Virtaal prevede due modalità di inserimento del testo sorgente nel campo di modifica. È possibile copiare l'intero testo di partenza con la combinazione Alt-Giù, eventualmente sovrascrivendo la traduzione già presente. Questo risulta utile in particolar modo se il messaggio contiene molti tag, numeri o se deve restare invariato. Non esiste invece un modo per impostare che il campo di modifica sia sempre inizializzato con il testo sorgente, come accade invece in molti altri ambienti di traduzione.
L'inserimento del testo sorgente nel campo di modifica avviene in modo intelligente: Virtaal è infatti in grado di rilevare se alcune convenzioni ortografiche, ad es. il tipo di virgolette utilizzate per le citazioni, debba essere modificato, e opererà le dovute sostituzioni in maniera automatica (modifiche annullabili in ogni caso con Ctrl-Z)
La seconda modalità di inserimento del testo sorgente nel campo di modifica non riguarda il segmento nella sua totalità ma solo parti di esso: gli elementi placeable. Nel contesto di Virtaal, questi ultimi sono porzioni di testo che vengono rilevate come non modificabili, non sono conteggiate ai fini del calcolo della somiglianza fra segmenti e possono essere inseriti in modo facilitato nella traduzione per evitare errori, incoerenze o errori critici (come nel caso di tag) nonché per risparmiare tempo in modo considerevole.
Il programma è in grado di riconoscere come placeable espressioni come: numeri, acronimi, tag ed entità XML, indirizzi email, URL, placeholder in diversi formati (Java, Python, Qt, printf), percorsi di file, opzioni della riga di comando ed espressioni camel-case.112 Anche i segni di punteggiatura meno comuni, alcuni simboli (es. ©) e sequenze di escape (utili in particolare nei file PO) vengono riconosciuti come elementi placeable. È possibile, a seconda delle proprie esigenze o del documento cui si sta lavorando, abilitare o disabilitare il riconoscimento di una o più di queste categorie dalla finestra di dialogo delle preferenze del programma.
I placeable rilevati sono evidenziati con un colore diverso, possono essere selezionati con Alt-Dx e Alt-Sx e, una volta raggiunto quello desiderato, si può passare all'inserimento premendo Alt-Giù. Dopo l'inserimento di un placeable, sarà immediatamente evidenziato quello successivo, in modo da evitare di doversi spostare ogni volta in avanti di un'unità. Raggiunto l'ultimo placeable, si ritorna alla situazione di partenza in cui tutti sono evidenziati ma nessuno è selezionato per l'inserimento.
Virtaal considera come placeable anche i termini che sono stati riconosciuti all'interno del file di terminologia. In pieno stile TTK, il programma memorizza le voci terminologiche in un PO di terminologia, della stessa natura di quelli creati con poterminology e utilizzati in Pootle.
Quando un segmento viene visualizzato, Virtaal confronta le espressioni con i termini presenti nelle risorse terminologiche. Le corrispondenze vengono rilevate indipendentemente dalla presenza di maiuscole/minuscole e con un minimo supporto morfologico (es. le -s finali in sostantivi e verbi inglesi sono ignorate ai fini della corrispondenza).
I termini riconosciuti vengono evidenziati con un colore diverso nel segmento di partenza ed è possibile spostarsi da un termine all'altro con le stesse combinazioni utilizzate per i placeable. A differenza di questi ultimi, però, la pressione di Alt-Giù non provoca l'inserimento del testo sorgente ma del termine equivalente in lingua d'arrivo.
Qualora fossero presenti più suggerimenti per uno stesso termine, questi verranno presentati in un menu a comparsa in modo da permettere di scegliere quello desiderato con Invio o continuare la traduzione con Esc. L'unico difetto di questa soluzione, volendo a tutti i costi evidenziarne uno, è che nel caso di una corrispondenza termine-termine senza sinonimi non è possibile visualizzare il contenuto del glossario prima di inserire l'equivalenza in lingua d'arrivo nel campo di modifica.
Le risorse terminologiche utilizzabili possono essere suddivise in due categorie: locali o remote. In primo luogo, Virtaal permette l'integrazione con il progetto Open-Tran (www.open-tran.eu), anch'esso basato sull'API del TTK. Inoltre, con la funzione autoterm, è possibile scaricare automaticamente file di terminologia di progetto direttamente dal web.
Le risorse locali, invece, sono i cosiddetti ‘file di terminologia’ salvati sulla postazione di lavoro in uso. È possibile utilizzare più file alla volta per ogni sessione di traduzione, che possono essere aggiunti a quello predefinito dal menu Modifica/File di terminologia. Quando sono presenti più file è necessario specificare quello principale, che andrà a integrarsi con le voci aggiunte in fase di traduzione, salvo scelte diverse operate in fase di creazione.
Dall'interno del programma è infatti disponibile un'interfaccia di creazione semplificata per nuove voci terminologiche comprendente i due campi per i termini più uno per i commenti. L'aggiunta di una voce di glossario può essere effettuata con Ctrl-T ed è possibile accelerare ulteriormente il processo selezionando nel segmento di partenza o di arrivo il contenuto del termine che si desidera aggiungere prima di ricorrere alla scorciatoia. Questo farà sì che il campo sorgente o il campo meta siano già completati.
Qualora fossero in uso più risorse terminologiche, è possibile specificare in quale deve essere aggiunta la nuova voce. Tuttavia non è possibile l'eliminazione o la modifica di quelle esistenti senza intervenire ‘a mano’ sulle risorse.113 Una nota positiva, da questo punto di vista, è invece il messaggio di avvertimento che si riceve cercando di aggiungere a un glossario nuove traduzioni per termini che già presentano degli equivalenti: l'operazione è sempre consentita ma si evita la possibile reiterazione di lavoro già svolto.
A questo rispetto, è necessario sottolineare che il PO di terminologia è un formato non standard, utilizzabile solo in determinati contesti e scarsamente portabile da un'applicazione all'altra. Il file consiste infatti di una serie di messaggi in cui il campo msgid contiene il termine in lingua di partenza, msgstr l'equivalente in lingua d'arrivo e gli eventuali commenti sono memorizzati come commenti del traduttore.
Lo standard TBX è invece supportato nativamente, sia in lettura che in scrittura, anche se purtroppo si tratta di un supporto parziale: vengono inseriti correttamente i termini in lingua di partenza e di arrivo, ma gli eventuali commenti sono ignorati. Analoghe considerazioni valgono per i glossari TSV di OmegaT con i quali, però, si ha pieno supporto ai commenti anche in scrittura.
In fase di traduzione interattiva Virtaal fornisce anche una serie di suggerimenti relativi al segmento aperto per la modifica, che sono visualizzati in una finestra temporanea e che, qualora fossero più di uno, è possibile selezionare e inserire con Ctrl-1, Ctrl-2, ecc. oppure con un doppio clic sulla proposta desiderata. I suggerimenti sono ottenuti da uno dei motori di MT che è possibile integrare nel programma (Google Translate, Apertium, Microsoft Translator e Mose) oppure da traduzioni ‘umane’.
Queste ultime possono ancora una volta provenire dall'esterno (da Open-Tran, da server tinyTM o da un server TM condiviso). In alternativa, possono essere corrispondenze interne al documento in fase di traduzione oppure possono provenire dalle TU create dallo stesso utente in sessioni di lavoro precedenti (nel suggerimento viene specificato se la corrispondenza proviene dal file in traduzione o dalla TM).
Queste ultime sono depositate in una TM locale memorizzata nel file tm.db sotto forma di database SQLite nella cartella dei dati e delle impostazioni locali del programma, in genere ∼/.virtaal. La TM contiene tutti i segmenti tradotti con il programma a partire dal momento della sua creazione: è quindi comune a tutti le sessioni di lavoro e non è possibile selezionarne più di una o gestire facilmente più TM di progetto.
La TM può essere rinominata o spostata in quanto il file tm.db verrà ricreato automaticamente e utilizzato, senza alternative, come predefinito. Per scambiare le TM è sufficiente quindi rinominare o spostare quella non desiderata e portare in ∼/.virtaal/tm.db la TM da utilizzare.
Il vantaggio di un simile approccio è che tutte le traduzioni effettuate in precedenza possono essere riutilizzate nei lavori successivi. Gli svantaggi sono invece, oltre alla difficoltà di gestione di memorie multiple, dati dal fatto che è difficile esportare i dati da una TM in un simile formato114 e mantenere separati database diversi per ragioni di ‘ordine’ senza essere costretti a continui backup e cancellazioni.
L'importazione di un TMX in Virtaal può essere effettuata aprendo il file come un documento bilingue per la traduzione, apportando una modifica qualsiasi e salvando il ‘lavoro’: in questo modo tutte le TU della memoria saranno aggiunte al database locale. La procedura funziona ma nel caso di file di grandi dimensioni può portare a un sensibile rallentamento o addirittura a uno stallo dell'applicazione. In questo caso, per portare a termine con successo l'importazione può rivelarsi necessario convertire la memoria in PO con tikal (cfr. 4.4.2) utilizzando il comando tikal -2po <file.tmx> -sl en -tl it e importare in Virtaal il PO generato aprendolo come per la traduzione, apportando una modifica e salvarlo.
Analogamente, non esiste una procedura per realizzare l'esportazione delle TU dal database locale di Virtaal in TMX, tuttavia se si dispone dei documenti di arrivo in formato PO o XLIFF è facile creare una memoria con lo strumento po2tmx del TTK con po2tmx -i <file po> -o <file tmx> --language it_IT oppure con l'opportuno convertitore (xliff2po) da XLIFF a PO e poi da PO a TMX.115
Le memorie così generate possono essere unite con applicazioni come TMXMerger (cfr. sez. 4.3.1) oppure l'unione, se i file bilingui sono in formato PO, può essere effettuata anche con pomerge o msgcat. La procedura rimane in ogni caso complicata e rischiosa, soprattutto quando esistono altri editor di PO che invece consentono nativamente l'esportazione e l'importazione da TMX (ad es. Lokalize).
Se sono installati i programmi corretti (GtkSpell l'evidenziazione nel campo di testo, libenchant e i dizionari Hunspell) verrà effettuato il controllo ortografico durante la digitazione.
Gli errori appaiono solo una volta che il segmento è stato inizializzato ed è molto facile apportare le correzioni o aggiungere la parola sospetta al dizionario facendo clic con il pulsante destro (tuttavia, non esiste la possibilità di effettuare il controllo ortografico sull'intero documento o su un gruppo di più messaggi). In compenso, il programma integra una funzionalità di correzione automatica simile a quella degli editor di testo più avanzati, in grado non solo di rilevare ma anche di correggere gli errori ortografici.
Un'altra caratteristica molto utile, è l'autocompletamento delle parole più lunghe che sono già state utilizzate in precedenza nel corso della traduzione. Il completamento viene visualizzato come suggerimento in un'area di testo temporanea sotto la posizione del cursore e può essere accettato con il tasto Tab tipico nelle shell testuali Unix.
Accanto alle TM remote, al completamento e alla correzione automatici e alle ricerche terminologiche remote esistono numerosi altri plug-in molto utili, ed è probabile che nelle versioni future del programma sarà possibile aggiungerne anche di nuovi. È addirittura presente un assistente per la migrazione delle impostazioni da altre applicazioni CAT per la localizzazione.
Un'altra estensione interessante è la cosiddetta ‘web look-up’ che permette di effettuare ricerche sul web sul testo di partenza in un solo clic. È sufficiente, infatti, selezionare uno o più termini nel campo del testo di partenza o d'arrivo, fare clic con il pulsante destro sulla selezione e, dal menu contestuale che apparirà, scegliere di cercare il termine selezionato in uno dei portali proposti: Google, Wikipedia o, ancora una volta, Open-Tran.
È anche molto semplice aggiungere nuove fonti di informazioni intervenendo sul file ∼/.virtaal/weblookup.it e tenendo presente che la variabile %(query) verrà espansa con il contenuto della stringa di ricerca mentre %(querylang) verrà sostituita con la sigla della lingua dell'espressione da cercare.
Il comportamento del programma e di tutte le estensioni consente margini più o meno ampi di personalizzazione. Sfortunatamente, allo stato attuale, non esiste ancora la possibilità di intervenire su tutte le impostazioni tramite la GUI del programma. È quindi necessario intervenire direttamente sui file *.ini (caratterizzati dalla tipica struttura chiave = valore) presenti nella già citata cartella contenente i dati e le impostazioni locali dell'applicazione.
Ad esempio, se si desidera abbassare la soglia di corrispondenza minima necessaria per vedere visualizzato un suggerimento proveniente da una TM è sufficiente inserire un valore più basso per la chiave min_quality presente nella sezione [tm] del file plugins.ini, e così via.116
Non va dimenticato che Virtaal, nonostante l'estesa gamma di formati supportati, è nato e trova ancora il suo campo di applicazione principale nella localizzazione dei file PO. A questo proposito, vanno evidenziate alcune importanti caratteristiche del programma. In primo luogo, l'intestazione PO (cfr. 2.4.2) viene aggiornata automaticamente inserendo i dati del traduttore memorizzati nella scheda Generale delle preferenze del programma.
È inoltre possibile marcare i messaggi come in attesa di revisione inserendo o eliminando il flag fuzzy con una casella di spunta che appare a fianco di ogni messaggio. Se il sorgente è un documento XLIFF, questo corrisponde a impostare l'attributo approved="yes" oppure approved="no" nella relativa unità di traduzione. Tuttavia, non è possibile marcare automaticamente tutti i segmenti modificati come in attesa di convalida.
Vengono visualizzati in modo corretto i commenti del programmatore (commenti estratti automaticamente per i localizzatori) e i contesti di disambiguazione, ma non il formato delle variabili. I commenti del traduttore possono essere visualizzati ma non è facile aggiungerne di nuovi senza aprire il PO in un editor di testo e modificarlo ‘a mano’. Nel caso dei messaggi fuzzy ottenuti con msgmerge, lo stato viene interpretato in modo corretto e viene mostrata la traduzione esistente, ma i campi identificativi precedenti (introdotti da #| nel PO) non vengono mostrati.
I riferimenti al codice sorgente sono visualizzati (solo quando non siano presenti commenti estratti automaticamente), ma non esiste un modo rapido per consultare i sorgenti dall'interno del programma. Parimenti con Virtaal non è possibile sincronizzare in modo automatico i propri sorgenti scaricati in locale con il sistema di controllo versione (es. Subversion) adottato dal progetto cui si partecipa come traduttori.
Infine, per quanto concerne la localizzazione, con Virtaal è molto semplice correggere errori anche in applicazioni già compilate, dato il supporto anche per formati binari come il MO, senza bisogno di ricorrere a msgunfmt prima dell'importazione per la modifica.
Virtaal è fornito di un manuale completo online, in larga parte tradotta in italiano, cui è facile accedere anche dalla schermata iniziale all'apertura del programma. Qui è anche disponibile un'esercitazione interattiva curata da Friedel Wolff, in cui l'utente è guidato nella realizzazione di una ‘traduzione’ dai commenti inseriti dall'autore, che illustrano le funzionalità del programma e gli errori più comuni commessi dagli aspiranti localizzatori.
Sulle pagine web dedicate al programma è possibile trovare informazioni anche su aspetti interessanti per chi intenda utilizzare Virtaal per scopi commerciali (nel pieno rispetto dalla licenza GNU GPL), come la divulgazione di dati personali o confidenziali, la riservatezza del materiale tradotto, la tracciabilità delle informazioni trasmesse attraverso i plug-in di ricerca terminologica automatica, TM remota o MT in modo che sia possibile disabilitare o configurare al meglio ciò che potrebbe essere fonte di problemi in tal senso.
Grazie all'estesa documentazione (comprensiva della guida alla localizzazione ospitata sul wiki del TTK & Pootle), alle esercitazioni disponibili in rete, alla chiara evidenziazione con colori della sintassi Virtaal è un programma molto adatto anche ai principianti della localizzazione e, in genere, a chi decida di cimentarsi nel mondo della traduzione come professionista o volontario anche senza nessuna esperienza pregressa.
Inoltre, non è possibile non sottolineare con piacere la possibilità di effettuare ricerche su internet direttamente dal testo grazie alla funzione ‘web look-up’. Un'altra eccellente caratteristica su cui vale la pena di porre enfasi sono le scorciatoie da tastiera, grazie alle quali è possibile selezionare e inserire i placeable e le voci di glossario, crearne di nuove, copiare l'intero segmento di origine, selezionare e inserire le corrispondenze trovate in memoria, annullare eventuali errori e salvare la traduzione interamente da tastiera senza mai usare il mouse.
È possibile segnalare, d'altra parte, una serie di aspetti in cui sarebbero auspicabili miglioramenti per le future versioni del programma. In primo luogo, va ricordato il supporto parziale agli standard TBX e, soprattutto TMX, che comporta qualche problema di interoperabilità. Inoltre, sebbene il programma presenti funzionalità molto avanzate sia in quanto a integrazione con la traduzione automatica che con TM remote, l'utilizzo di una TM locale unica e monolitica pone un certo limite, anche se superabile, all'applicazione del programma per scopi generici (come invece auspicato dagli sviluppatori).
In secondo luogo, in Virtaal è assente qualsiasi strumento di controllo qualità, nonostante il TTK comprenda uno strumento molto efficace come pofilter (v. 3.4.2) e gli stessi filtri siano utilizzati nella piattaforma web Pootle. L'implementazione di questa caratteristica è tuttavia pianificata per la versione 0.7 di Virtaal.
Un ultimo problema è rappresentato dall'assenza di statistiche di progetto, ad esempio in forma elementare nella barra di stato. Anche in questo caso la soluzione c'è ed è offerta dal TTK, con lo strumento pocount, che permette di visualizzare il numero di stringhe, di parole nel testo sorgente e di parole nella traduzione (nonché la percentuale sul totale) che siano tradotte, non tradotte o fuzzy.
Per avere invece statistiche ‘ponderate’ in base alle corrispondenze con una memoria in formato TMX è possibile ricorrere a pot2po (l'equivalente TTK di msginit) attraverso l'opzione -tm per specificare la memoria di traduzione e -similarity per la soglia minima di corrispondenza per la pretraduzione, prima di ricorrere a pocount come nel caso precedente.117
3.3.6 Qt Linguist
| Autore: | Alessandro Portale |
| Licenza: | GNU GPL |
| Pagina web: | http://qt.nokia.com/products |
| Versione: | 4.7.1 (novembre 2010) |
Qt Linguist è lo strumento di localizzazione consigliato per le applicazioni che adottano il toolkit grafico Qt: il ciclo di sviluppo predefinito bastato su queste librerie prevede infatti l'utilizzo del formato di risorse intermedio .ts. Pur essendo quest'ultimo utilizzato solo in questo contesto e quindi non del tutto standard,118 si tratta di un formato basato su XML e quindi completamente accessibile e leggibile.
Il programma, realizzato ovviamente in C++ e Qt, ovviamente, è facilmente installabile tramite il gestore software della propria distribuzione: in Debian e derivate il pacchetto da installare è qt4-dev-tools. In alternativa, è possibile scaricare tutto il necessario dalla pagina del progetto.
I formati supportati sono .ts, PO, e XLIFF per i documenti da tradurre, mentre le risorse di traduzione sono in formato .qph. Un ulteriore formato gestito (solo in uscita) dal programma è anche il .qm, corrispondente al MO di Gettext, che contiene i messaggi tradotti in un formato utilizzabile dall'applicazione localizzata.
L'interfaccia del programma è divisa in una serie di sezioni che, a parte l'area di traduzione, possono essere riposizionate o addirittura ‘staccate’ dalla finestra principale. Queste sezioni sono la lista dei contesti, la lista delle stringhe e l'area di traduzione, corredate da una sezione per i suggerimenti provenienti dalle risorse di traduzione e una per l'esito dei controlli di QA. Nel linguaggio di Qt Linguist un ‘contesto’ equivale in prima approssimazione al catalogo dei messaggi da localizzare.119 Dopo aver selezionato un contesto, tutti i messaggi che lo compongono saranno caricati nella lista delle stringhe, ognuno corredato da un'icona che ne rende immediatamente riconoscibile lo stato (approvato/corretto approvato/contenente errori, non approvato, non tradotto, osboleto, ecc….).
 |
Selezionando una stringa, questa verrà copiata nell'area di traduzione, contenente un testo sorgente per ogni lingua (dal momento che il programma permette di considerare i messaggi dei file ausiliari come ‘lingue di partenza’ supplementari), i commenti dello sviluppatore e il campo di modifica per l'immissione della traduzione. A questo proposito, non è prevista alcuna ottimizzazione per l'inserimento di elementi placeable o placeholder, che devono essere inseriti manualmente oppure ricopiando l'intera stringa sorgente nel campo di modifica.
L'unico supporto al traduttore durante la traduzione è il recupero delle corrispondenze dalle risorse di traduzione. In Qt Linguist non è prevista la distinzione fra TM e glossario, in quanto sia la terminologia che i segmenti vengono memorizzati in database dello stesso tipo, chiamati phrase book. Quel che può sembrare a prima vista un grossolano difetto di progettazione, trova in realtà la sua spiegazione nel fatto che localizzando file di risorse dove la lunghezza dei messaggi è spesso di poche parole, spesso termini e segmenti vengono a coincidere o, meglio, è più difficile operare una distinzione chiara.120
Durante lo svolgimento della traduzione, è possibile caricare un numero arbitrario di phrase book e, all'occorrenza, disattivarne alcuni. Qt Linguist mostra i suggerimenti in un'apposita area della finestra principale, permettendo di inserire in modo facilitato le corrispondenze esatte.
Nel caso di corrispondenze parziali, invece, non viene mostrata né la percentuale di somiglianza né vengono evidenziate le differenze in modo chiaro, ciononostante l'espressione in lingua di partenza recuperata dal phrase book viene visualizzata in modo da permettere il confronto. È possibile, inoltre, effettuare la pretraduzione del documento sulla base di un phrase book come se si trattasse di una TM (anche ignorando le eventuali stringhe già approvate o che contengono già una traduzione).
I phrase book di Qt Linguist sono documenti XML che è possibile consultare, convalidare e condividere con altri utenti. Tuttavia, rappresentano un formato non standard per la localizzazione, inusuale e non direttamente utilizzabile da nessuno degli altri strumenti considerati in questa sezione.
Volendo integrare le risorse prodotte con Qt Linguist in altre applicazioni l'unica opzione disponibile è convertire il documento .ts in PO e procedere come esposto in 3.3.5 per produrre un TMX standard. L'operazione inversa, invece, cioè l'importazione di segmenti da TMX è più complicata e prevede la conversione in PO (es. con tikal, cfr. 4.4.2) e l'aggiunta manuale delle stringhe.
Un aspetto, invece, indubbiamente positivo è rappresentato dalla possibilità di intervenire dall'interno del programma sul phrase book non solo aggiungendo nuovi elementi, ma anche eliminando o modificando quelli esistenti e, nel caso delle voci terminologiche, integrando la definizione. Per quanto rudimentale, questa soluzione rappresenta un abbozzo di gestione terminologica simile a quella di Lokalize e, data la mancata distinzione fra record terminologici e TU, anche un'interfaccia per la gestione delle memorie di traduzione unica nel suo genere fra tutti gli strumenti qui presentati.
La navigazione all'interno del documento può avvenire in maniera sequenziale in base allo stato, spostandosi solo fra i messaggi non pronti, oppure assoluta. Alla chiusura di un messaggio questo viene marcato come modificato ma non approvato in maniera predefinita e solo su esplicito intervento dell'utente (Ctrl-Invio) è possibile spostarsi al messaggio successivo marcando come approvato quello corrente.
Il programma comprende inoltre una funzionalità di ricerca, con cui è possibile specificare in che campi dev'essere presente il testo, e di ‘ricerca e traduzione’, che invece permette di cercare una stringa nel campo sorgente e di sostituire con il testo specificato il contenuto del campo di traduzione.
Qt Linguist offre diverse ottimizzazioni per i localizzatori. In primo luogo la possibilità di consultare file ausiliari in lingue diverse dall'inglese, il cui testo viene visualizzato nell'area di traduzione come un'ulteriore stringa sorgente. In secondo luogo, vengono visualizzate alcune categorie di commenti, come i riferimenti al sorgente, i commenti estratti automaticamente e i commenti del traduttore (modificabili). Anche i plurali sono gestiti correttamente, sia nel caso di documenti PO che .ts: il testo sorgente appare replicato così come il campo di modifica.
Dal momento che il programma non nasce come editor di PO, tuttavia, non tutte le caratteristiche di questi ultimi file sono supportate (ad esempio, non è possibile visualizzare i campi identificativi precedenti o modificare automaticamente l'intestazione). È possibile invece gestire correttamente le apparenti duplicazioni dei messaggi sia con il sistema di Gettext (che prevede i contesti di disambiguazione) che nella maniera predefinita delle Qt, mediante la presenza di particolari commenti nel file .ts, in modo da tollerare la presenza più traduzioni per una stessa stringa sorgente qualora necessario.
Se il codice sorgente è disponibile, durante la traduzione questo è automaticamente visualizzato nella rispettiva area della finestra principale nel punto esatto in cui compare la stringa da localizzare. Questa utilissima funzionalità è disponibile sia per il formato .ts nativo del programma che per il PO a condizione che, ovviamente, il documento contenga i riferimenti al codice sorgente (contenuti all'interno di un elemento <location filename=‘sorgente.cpp’ line="275"/> situato nel rispettivo elemento <message>).
Un altro aspetto che rende interessante Qt Linguist sono i controlli di QA che è possibile effettuare dall'interno del programma senza bisogno di ricorrere a strumenti di convalida esterni. Le quattro verifiche che è possibile abilitare sono: il controllo della punteggiatura al termine delle stringhe, la conformità della traduzione ai suggerimenti contenuti nel phrase book, l'inserimento o l'eliminazione degli acceleratori e il corretto utilizzo dei placeholder. Trattandosi di un editor specifico per le applicazioni Qt, gli unici formati per questi due elementi sono quelli tipici Qt/KDE.
Dal momento che il controllo di qualità può essere abilitato già in fase di traduzione, è possibile rilevare la presenza di errori nei messaggi sia per il diverso stato (approvato/contenente errori oppure non approvato/contenente errori) nella lista delle stringhe. Selezionando il messaggio in questione, nell'area Warnings della finestra principale comparirà un messaggio diagnostico per ogni errore rilevato dal programma, qualora uno dei quattro test di validazione dovesse aver dato un esito positivo. Non è possibile, invece, avere accesso ad alcun controllo ortografico per verificare la correttezza del proprio lavoro.
Un'altra funzionalità degna di nota che colloca Qt Linguist su un livello simile ai programmi proprietari per la localizzazione (ad es. il diffuso Alchemy Catalist) è la possibilità di visualizzare le anteprime delle finestre di dialogo sia in versione originale che localizzata, in modo da rendersi immediatamente conto di eventuali problemi di localizzazione.
Tale caratteristica, unica fra tutti gli strumenti considerati in questa sezione, è possibile grazie alla stretta integrazione fra Qt Linguist e gli altri strumenti di sviluppo Qt (come KUIViewer) in grado di leggere direttamente i file di interfaccia grafica .ui. Tali file, al pari dei sorgenti, devono essere presenti in una posizione accessibile dal programma per consentire la visualizzazione dell'anteprima.
Concludendo, Qt Linguist è un programma semplice da utilizzare ma funzionale e soprattutto molto completo, che può vantare integrazione e pieno controllo sulle risorse terminologiche, controlli di qualità, visualizzazione dei sorgenti, compilazione dei file di traduzione in formato binario e addirittura anteprima delle applicazioni localizzate.
Il maggior difetto è dato dalla limitata applicabilità al solo ciclo di sviluppo di applicazioni Qt, perché la maggior parte di queste caratteristiche vincenti si basano sulla stretta integrazione fra lo strumento e questo framework (es. acceleratori e placeholder per la QA sono solo in formato Qt/KDE, le anteprime richiedono file .ui, la compilazione è solo in .qm).
Ugualmente, il formato.qph per le risorse rappresenta un ostacolo alla compatibilità con altri applicativi e alla condivisione del lavoro. Essendo numerose applicazioni Qt rilasciate sotto licenze non libere, d'altronde, è comprensibile che le priorità di un simile progetto siano diverse da quelle degli altri strumenti presi in esame in questo lavoro.
Tuttavia, anche per questo motivo, lo strumento merita di essere tenuto in considerazione tanto da chi desidera contribuire alla traduzione nelle varie lingue nazionali del SL quanto dai professionisti (o aspiranti tali) della localizzazione.
3.3.7 WordForge
motto di WordForge
| Autori: | H. Kakada, K. Sophon, S. Titvirak, S. Chanratha et al. |
| Licenza: | GNU GPLv3 |
| Pagina web: | http://sourceforge.net/projects/wordforge2 |
| Versione: | 0.8 beta1 (dicembre 2010) |
In modo simile a Virtaal anche WordForge affonda le proprie radici nell'API del TTK e ad esso deve gran parte delle sue funzionalità. Così come il TTK e con esso Virtaal sono nato e si sono sviluppati attorno a una fondazione per la localizzazione di software nelle lingue del Sudafrica, WordForge deve la sua esistenza a KhmerOS, un'organizzazione no-profit dedicata alla localizzazione in lingua Khmer (Cambogia).
In modo analogo all'applicazione precedente, anche WordForge è scritto in Python e questo consente l'intrinseco vantaggio della portabilità e della facilità di installazione ed esecuzione. Nella pagina web dedicata al programma è possibile anche reperire una serie di pacchetti software per le principali distribuzioni GNU/Linux, in modo da facilitarne la procedura di installazione e rimozione.
Una delle differenze più evidenti a un primo sguardo fra i due programmi è però che nel caso di WordForge l'interfaccia grafica è realizzata con il toolkit Qt.121 Se la finestra principale del primo è ridotta all'essenziale, WordForge presenta invece una barra dei menu, diverse barre degli strumenti per le funzioni principali, una barra di stato e 6 regioni interessate dal processo di traduzione: la lista delle stringhe (in cui per ciascun messaggio è mostrato il numero identificativo, l'originale, la traduzione, lo status e lo stato relativo alla rilevazione degli errori), una regione per i commenti (riferimenti al sorgente e commenti del traduttore), un'area dedicata ai glossari, una alle corrispondenze in TM, una all'editing della traduzione e che visualizza i commenti estratti automaticamente e, da ultimo, una regione destinata alla rilevazione degli errori in cui sono visualizzati l'identificativo, il tipo e il messaggio di errore di ogni messaggio risultato positivo.
WordForge elabora internamente le informazioni nel formato standard bilingue XLIFF, ma supporta in entrata e in uscita anche PO,122 TBX e, naturalmente, il TMX per le memorie. Se a prima vista questa lista può sembrar e ridotta, non va dimenticato che esistono numerosi strumenti di conversione forniti dal TTK, ad esempio odf2xliff, con cui è possibile convertire file in formato OpenDocument in XLIFF. WordForge stesso fornisce una comoda e potente interfaccia grafica alla suite di convertitori del TTK, dal menu Tools/Converters. Ulteriori conversioni nel formato XLIFF possono essere realizzate con gli strumenti dell'infrastruttura Okapi (cfr. 4.4.1 e 4.4.2).
Diversamente da Virtaal, il programma consente la creazione di progetti formati da più file, che possono essere salvati o modificati in un secondo momento. La gestione dei progetti non è orientata tanto al singolo task di traduzione quanto piuttosto ai gruppi di localizzazione cui si partecipa. Non è infatti possibile ‘aprire’ un progetto per avere accesso in modifica ai file che lo compongono: i file da tradurre vanno comunque aperti singolarmente in un secondo momento (Ctrl-O).
I progetti di WordForge intendono riflettere i ‘progetti di localizzazione’ (GNOME, KDE, OpenOffice, ecc.) in cui il traduttore è attivo, permettendo di salvare le impostazioni tipiche di ciascuno in modo da evitare di dover continuamente riconfigurare il programma.
Sui progetti è possibile eseguire operazioni ‘globali’, come la rilevazione di errori, l'aggiunta e la rimozione di file (ad esempio di quelli già consegnati), la visualizzazione di informazioni sulla revisione e sull'ultimo traduttore nonché statistiche sui singoli file alla maniera di pocount.
Dalla finestra di gestione dei progetti può anche essere creata una TM di progetto, che incorporerà al suo interno tutte le traduzioni salvate nei file di progetto senza bisogno di digitare nuovamente il percorso di ogni singolo file in un secondo momento. Un'altra funzionalità interessante a livello di progetto è la possibilità di cercare una determinata stringa (sorgente o destinazione) in tutti i file di progetto senza necessità di aprirli uno alla volta per la ricerca.
Una volta aperto un file per la traduzione, la navigazione da un messaggio all'altro nella lista delle stringhe può avvenire fra segmenti adiacenti (PagGiù e PagSu), all'inizio o alla fine della lista (Ctrl-PagSu e Ctrl-PagGiù) oppure ad un determinato segmento di cui si conosca il numero identificativo (Ctrl-G). La lista delle stringhe può essere modificata inserendo degli opportuni ‘filtri’, ad esempio, visualizzando solo i messaggi tradotti, quelli non tradotti e quelli fuzzy. Inoltre, la navigazione è resa più agevole anche dalla possibilità di creare segnalibri e di spostarsi da un segnalibro all'altro come in GNU Emacs con l'utilizzo della pila.
In fase di traduzione, alcune parti di testo sono evidenziate con colori diversi per renderne facile l'individuazione da parte del traduttore: in primo luogo i termini riconosciuti nei glossari di progetto. In secondo luogo, con colori diversi, vengono messi in risalto i tag stile XML e le espressioni ‘CamelCase’.
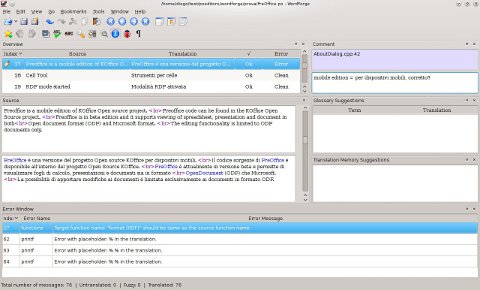 |
Queste ultime due categorie sono gli elementi placeable riconosciuti dal programma e, sebbene siano di importanza fondamentale e siano anche tenuti in considerazione per il controllo degli errori (assieme a molti altri fattori), non esiste un modo facile per personalizzarne il riconoscimento né per facilitarne l'inserimento in fase di traduzione.
È possibile visualizzare o non visualizzare i caratteri non stampabili (ad es. caratteri di spaziatura, che nei PO corrispondono a sequenze di escape). Altre utili funzionalità sono la possibilità di copiare il testo sorgente (F2) o di inserire nel campo di modifica la traduzione più simile all'originale recuperata dalla TM.
Oltre che a livello di progetto, come si è detto, è possibile realizzare ricerche nel file aperto per la traduzione, specificando se cercare solo nelle stringhe sorgenti, in quelle di destinazione o in entrambe e se distinguere fra maiuscole/minuscole.
L'espressione cercata viene evidenziata con un colore in modo da renderne più facile l'individuazione. La funzionalità di sostituzione è molto simile a quella di ricerca, con l'unica differenza che, ovviamente, non è possibile operare sostituzioni nel campo sorgente. In entrambi i casi è da segnalare il mancato supporto alle espressioni regolari.
Per creare una TM all'inizio della traduzione, è consentita l'importazione di file precedentemente tradotti in tutti i formati supportati e anche da directory contenenti più file in maniera ricorsiva, dalla finestra Tools/Import and Manage Translation Memory.
WordForge supporta l'utilizzo di più file come fonti di suggerimenti allo stesso tempo, che possono essere abilitati o disabilitati, aggiunti o tolti alla sessione di traduzione. Una volta configurate le fonti, è possibile costruire la TM, che verrà poi utilizzata durante la traduzione corrente. La TM può anche essere esportata direttamente in TMX per utilizzi futuri senza dover cercare di nuovo i file utilizzati la prima volta.
Una volta costruita la memoria, questa viene salvata in un file TMX locale, ad esempio ∼/.config/WordForgeTM.tmx. La TM può essere ‘azzerata’ (pulsante Clear): in questo modo la lista di file presenti sarà ripulita e la memoria locale conterrà solo le TU estratte dai nuovi file specificati. Questo sistema può apparire un po' macchinoso, perché comporta la creazione di TM ‘di progetto’ all'inizio di ogni nuova sessione sulla base delle esigenze del traduttore e dei file tradotti da riutilizzare, ma ripropone di fatto quanto illustrato in Virtaal per gestire le TM mantenendo l'ordine e non ‘sporcando’ inutilmente la TM locale.123
In WordForge la procedura può essere realizzata interamente all'interno del programma (piuttosto che con gli strumenti del TTK da riga di comando), ma il concetto è lo stesso. Un altro vantaggio intrinseco, oltre alla comodità di esecuzione grazie al front-end grafico, è la grande flessibilità che questo approccio comporta, solo in apparenza al prezzo di una maggiore complessità. Infatti, come si ripeterà più avanti, è possibile riprodurre in WordForge il comportamento degli strumenti CAT più comuni esportando la memoria locale direttamente come TMX (Tools/Export Translation Memory), che non fa altro che copiare la TM in una posizione scelta dall'utente e, se in futuro la TM locale è stata cambiata, reimportare il TMX inserendolo nella lista dei file per costruire la nuova TM.
Le TM possono essere utilizzate in WordForge secondo due diverse modalità: TM basata su file (scelta predefinita) e TM istantanea. La differenza fra le due opzioni non riguarda il metodo di costruzione della TM appena descritto, che è comune a entrambe, quanto piuttosto la modalità di consultazione.
Se si sceglie di lavorare con una TM basata su file, una volta selezionati i documenti da utilizzare come riferimento è possibile applicare la TM al documento di partenza. In questo modo è molto facile realizzare una sorta di pretraduzione del nuovo documento. I messaggi marcati come fuzzy vengono normalmente ignorati ai fini della ricerca di corrispondenze, ma è possibile cercare suggerimenti anche per questi ultimi selezionando la relativa opzione.
Il comportamento del programma se vengono rilevate delle corrispondenze in TM può infatti essere configurato in maniera molto flessibile. I suggerimenti possono essere copiati direttamente nel campo di modifica quando sono al di sopra di una determinata soglia oppure copiati ma marcando come fuzzy il messaggio.
In alternativa i suggerimenti, di cui può essere specificato in numero massimo, possono essere aggiunti sotto forma di elemento <alt-trans> nello XLIFF o come commento temporaneo nel PO quando sono al di sopra di una determinata soglia di somiglianza. Se si tratta di messaggi della dimensione di una voce di glossario, è addirittura possibile specificare se la traduzione possa essere recuperata dal glossario (ed eventualmente marcata come fuzzy).
Al termine del processo sarà visualizzata una finestra contenente le statistiche ponderate sulla TM utilizzata come riferimento, in modo molto simile a quanto visto in precedenza con pocount. A questo punto può dirsi ultimata la pretraduzione del documento e può avere inizio il lavoro vero e proprio del localizzatore.
Ricorrendo alla TM istantanea, invece, i suggerimenti per il messaggio corrente vengono cercati ‘in tempo reale’ cioè in fase di inizializzazione dello stesso. Come si può vedere, le due modalità di utilizzo della TM che in genere coesistono negli strumenti CAT ‘tradizionali’ — statica, nel caso della pretraduzione e dinamica, nel caso del leveraging — sono in questo caso separate e presentate come complementari. La seconda soluzione appare forse più semplice dal punto di vista dell'utente ma può rallentare il programma nel caso in cui si abbia a che fare con file di grandi dimensioni.
Il problema è stato riscontrato in questo stesso contesto anche con Virtaal, che può diventare considerevolmente lento in determinate occasioni: ancora una volta la strategia di WordForge, che preferisce l'utilizzo di una TM flessibile basata su file, rappresenta quindi un'elegante soluzione a un potenziale collo di bottiglia che si presenta utilizzando il TTK come ‘base’.
L'approccio predefinito alle TM di WordForge, che può sembrare strano a un utente proveniente da strumenti CAT proprietari in cui il calcolo delle corrispondenze e la consultazione della memoria avviene ‘in tempo reale’ ha inoltre in realtà numerosi vantaggi.
In primo luogo un consumo più moderato delle risorse di sistema, dal momento che la consultazione della TM, confronto tra segmenti e il calcolo della somiglianza viene svolto una sola volta all'inizio del lavoro oppure, in alternativa, può essere deciso di applicare la TM solo a determinati segmenti o al segmento corrente.
Il secondo grande indubbio vantaggio è l'elevata portabilità dei file di progetto. WordForge lavora infatti in via esclusiva con XLIFF e PO e nel primo caso permette di memorizzare anche le TU recuperate dalla memoria ‘staticamente’ nel file bilingue sotto forma di traduzioni alternative (salvano percentuale di somiglianza, fonte e numerose informazioni aggiuntive), mentre nel secondo caso ne consente comunque il salvataggio come commento. In entrambe le situazioni il file bilingue diventa ‘autonomo’ e può essere elaborato da chiunque e su qualunque postazione senza avere più bisogno di accesso a TM di dimensioni che potrebbero essere anche molto grandi.
Quale che sia la scelta per l'utilizzo della TM, i suggerimenti vengono mostrati nella relativa area della finestra principale, accompagnati dalla percentuale di somiglianza. Le differenze, nel caso dei fuzzy sono evidenziate con colori diversi e, per renderne più facile l'individuazione, la stringa sorgente del messaggio corrente viene riproposta sopra la stringa sorgente della TU recuperata dalla memoria.
In WordForge è possibile configurare la soglia di corrispondenza minima affinché le TU della memoria siano visualizzate come suggerimenti di traduzione. Tuttavia, sia da interfaccia grafica che modificando il valore TM_min nel file di configurazione WordForge.ini nella directory delle impostazioni locali del programma, non è possibile scendere al di sotto del 70%.124 Questo può essere un vantaggio, perché evita suggerimenti inutili o addirittura potenzialmente controproducenti, ma al tempo stesso rappresenta anche una limitazione non poco significativa in un'applicazione che consente margini così ampi di personalizzazione.
Per quanto riguarda i glossari, l'implementazione di WordForge ricalca quanto illustrato a proposito delle TM. I glossari vengono creati a livello di sessione a partire da file TBX e PO di terminologia e, una volta specificati i file e costituito il glossario, la propria selezione può essere esportata in TBX per utilizzi futuri, indipendentemente dalla posizione (o dall'esistenza) dei file usati per la costruzione dello stesso.
In fase di costruzione del glossario, è possibile importare non solo tutti i formati supportati, ma anche directory contenenti più file o sottocartelle in maniera ricorsiva. I file, o le posizioni, specificate possono essere abilitate o disabilitate ai fini della traduzione oppure aggiunte o rimosse dalla lista, in modo analogo a quanto detto per le TM. Le risorse terminologiche di WordForge sono compatibili solo con i due campi relativi al termine sorgente e al termine destinazione. Per apportare eventuali modifiche al glossario dall'interno del programma è necessario aprire, come in Virtaal, il TBX come se si intendesse modificarlo e, anche in questo caso, gli unici campi accessibili sono il termine sorgente e il termine di destinazione.
A differenza delle TM, i glossari vengono applicati automaticamente ai segmenti in fase di inizializzazione degli stessi: i termini riconosciuti vengono evidenziati con un colore diverso e il suggerimento proveniente dal glossario sarà visualizzato nella corrispondente area della finestra principale. Una volta che il termine è stato riconosciuto, è possibile inserire l'equivalente in lingua d'arrivo alla posizione del cursore nel campo di modifica o copiarlo negli appunti per riutilizzarlo.
L'approccio ai glossari di WordForge mostra senza dubbio alcuni vantaggi. In primo luogo, la flessibilità e la facilità con cui è possibile costruire risorse terminologiche all'inizio di una sessione di traduzione. In secondo luogo, anche la sovrapposizione glossari/memoria quando si applica la TM al documento è un aspetto positivo, soprattutto nella localizzazione di software, dove la dimensione delle stringhe può essere sovente ridotta alle dimensioni di un'unità terminologica.
Tuttavia, non è possibile nascondere delle pesanti limitazioni all'utilizzo efficiente delle risorse. In primo luogo, sebbene il rispetto dei glossari sia un aspetto contemplato (e personalizzabile) nella fase di controllo degli errori, non è possibile abilitare il fuzzy matching nei glossari tramite l'analisi morfologica delle parole nel testo sorgente.
In secondo luogo, va segnalata l'impossibilità di gestire correttamente i sinonimi (a livello di lingua di partenza e di lingua d'arrivo) e il fatto che non sia possibile leggere commenti o campi diversi da quelli dei termini nelle voci di glossario. Queste ultime non possono, inoltre, essere create dall'interno del programma, nemmeno in forma elementare.
In terzo luogo, nonostante sia possibile copiare la traduzione di un termine nel punto del campo di modifica dove si trova il cursore, l'inserimento con il clic del pulsante destro del mouse risulta poco comodo. In quarto e ultimo luogo, la creazione di glossari di progetto può risultare lunga o addirittura mandare in stallo il programma se si tenta di importare o di lavorare con un file TBX di dimensioni medie e grandi.
I messaggi che compongono il file di partenza e che sono stati modificati dal traduttore possono essere impostati come fuzzy o in attesa di revisione (Ctrl-U) o viceversa. È inoltre possibile impostare automaticamente come tradotti tutti i messaggi fuzzy (Ctrl-T).
In realtà la gamma di operazioni che è possibile eseguire su gruppi di messaggi è molto più ampia e vi si può avere accesso dal menu Edit/Batch Change. Grazie a questa funzionalità, lo status di tutti i messaggi aventi una determinata caratteristica (es. tradotti o fuzzy) può essere modificato in blocco.125
Infine sempre a livello superiore al singolo messaggio, possono essere cancellate tutte le traduzioni o può essere modificata la lingua di arrivo del documento, funzioni utili nel caso in cui si voglia creare un progetto per una nuova lingua partendo da una traduzione esistente piuttosto che dal modello o dall'originale.
Essendo uno dei suoi specifici ambiti di applicazione, anche WordForge presenta delle ottimizzazioni per il formato PO. In primo luogo, modifica in modo automatico l'intestazione PO con i dati relativi al traduttore e al gruppo specificati nella scheda Personalize della finestra di dialogo delle impostazioni. L'intestazione può essere personalizzata ulteriormente da Edit/Header (Ctrl-H).
È anche presente il supporto alle forme plurali: quando si incontra un messaggio che presenta una forma plurale, il campo testo sorgente e il campo di modifica visualizzano più ‘schede’ in modo da consentire l'inserimento delle traduzioni plurali, a seconda dell'espressione per il calcolo del plurale della propria lingua d'arrivo (anch'essa specificata nelle impostazioni del programma).
Il supporto ai PO prevede la visualizzazione della maggior parte dei commenti a livello dei messaggi: i commenti del traduttore vengono mostrati nella specifica area della finestra principale del programma, da cui è anche possibile modificarli. Anche i riferimenti al sorgente sono visualizzati nell'area dei commenti, ma non è previsto alcun metodo rapido per avere accesso ai sorgenti.
I flag e i formati delle variabili non sono visualizzati, mentre nel caso dei messaggi marcati come fuzzy processati da msgmerge viene correttamente importato lo status e visualizzata la traduzione preesistente ma non sono mostrati i campi identificativi (msgid o msgctxt) precedenti.126
Diverso è il caso dei commenti estratti automaticamente e dei contesti di disambiguazione del messaggio corrente, che compaiono durante la traduzione fra il campo sorgente e il campo di modifica, evidenziati con il colore rosso in modo da essere al centro dell'attenzione del traduttore.
Per lo XLIFF, che è l'altro formato principale di lavoro di WordForge, sono presenti numerose funzionalità aggiuntive: in primo luogo, il compito del traduttore può essere facilitato con la consultazione di traduzioni di riferimento in una terza lingua con cui abbia familiarità, in modo simile a quanto visto per GNU Emacs con i file ausiliari.
In secondo luogo, possono essere associate al documento le corrispondenze riscontrate con un glossario di riferimento. Specificando uno o più file di partenza e un glossario di partenza, verranno estratti da quest'ultimo solo le voci terminologiche presenti nei file di partenza e verrà creato un glossario ‘di progetto’ contenente solo i termini rilevanti ai fini della traduzione. Questo glossario verrà inserito direttamente all'interno dello XLIFF in modo da poter essere utilizzato dal traduttore che riceverà il file.
Tale caratteristica unita al fatto che, come si è visto, applicando la TM a un documento XLIFF saranno importate nel documento le TU della memoria che sono sufficientemente simili alle TU del documento di partenza permette di trasferire i file del progetto da un traduttore all'altro, o dal project manager ai traduttori, senza perdita di informazioni e senza bisogno di includere voluminosi glossari e TM, il tutto attraverso un formato standard come lo XLIFF che garantisce il massimo dell'interoperabilità.
WordForge presenta due modalità per la verifica degli errori battitura, a condizione che nel sistema sia installato il correttore ortografico e analizzatore morfologico Hunspell. Una prima modalità è il controllo ortografico durante la digitazione, che può essere attivato o disattivato con un pulsante. In alternativa, è possibile eseguire la verifica separatamente, analizzando gli errori uno a uno (su tutto il documento o su un certo numero di segmenti specificabili dall'utente), con la visualizzazione delle espressioni non trovate nel dizionario e dei suggerimenti, in maniera molto simile alle utilità di correzione ortografica dei normali elaboratori di testo.
Un ulteriore supporto di natura ‘linguistica’ alla traduzione è l'integrazione con i thesauri per la lingua di partenza e per quella di arrivo, nello stesso formato di OpenOffice.org. Per utilizzare questa funzionalità è sufficiente indicare il percorso dei relativi file nella sezione Thesaurus nella finestra di dialogo delle impostazioni del programma.
Una funzione molto interessante è rappresentata dal front-end allo strumento di rilevazione degli errori del TTK (pofilter). Dall'interno di WordForge è possibile eseguire un gran numero di controlli, inclusi la verifica degli acceleratori (in base alle impostazioni del gruppo con cui si lavora), dei placeholder, presenza e annidamento delle parentesi, punteggiatura, spaziatura, sequenze di escape, indirizzi email, …
 |
Se tutte queste sono, da un punto di vista concettuale, verifiche strettamente legate alla localizzazione e al PO in particolare,127 è da segnalare anche la presenza di un tipo di controllo di QA più ‘generale’, vale a dire il rispetto del glossario o dei glossari di progetto che rileva errori qualora non siano stati utilizzati i termini presenti nel glossario, specificando un limite di tolleranza basato sul numero di caratteri finali da non considerare (che permette un primitivo riconoscimento morfologico).
Com'è possibile osservare in figura 35, l'interfaccia del programma è molto ricca di opzioni e possibilità di personalizzazione e può apparire un po' ostica. Tuttavia, questo rappresenta una grande comodità dal punto di vista del traduttore, dal momento che è possibile avere un riscontro immediato della qualità del proprio lavoro senza avvalersi di strumenti esterni.
La verifica degli errori può essere effettuata sui singoli file o su interi progetti, in ogni caso le stringhe contenenti errori verranno visualizzate nella corrispondente area della finestra per rendere più facile e immediata la correzione dell'errore e la navigazione da un errore all'altro, facendo doppio clic sull'elemento della lista degli errori. Gli errori possono essere ignorati dall'utente ma viene comunque tenuta traccia di essi nel file XLIFF (sotto forma di elemento <note from="error"…>).128
Elaborare i documenti con pofilter avendo la cura di scegliere le opzioni adatte al proprio caso nell'invocazione del programma, estrarre le stringhe problematiche e le informazioni di diagnostica, apportare le correzioni del caso e reintegrare le modifiche nel documento originale possono essere operazioni all'ordine del giorno per i coordinatori di progetti di localizzazione ma non è detto che il singolo traduttore abbia le competenze e la familiarità necessaria con questi strumenti.
Concludendo, WordForge integra al suo interno molte funzionalità, come la gestione di progetti, le statistiche sui messaggi (eventualmente ponderate sulle corrispondenze in TM), la creazione di TM/glossari e i filtri per il controllo qualità implementabili con gli strumenti del TTK ma assenti in Virtaal. Anche alcune delle caratteristiche che le due applicazioni condividono, come l'importazione e l'applicazione delle TM ai documenti, sono implementate in WordForge in modo da evitare o rendere meno percepibili i potenziali problemi.
Non mancano, d'altro canto, le eccezioni, come il riconoscimento e la gestione della terminologia, che risulta nel complesso molto superiore in Virtaal. Inoltre, tutte le funzionalità ‘orientate al web’ (TM remota, terminologia online, ‘web look-up’) che contraddistinguono quest'ultimo sono assenti in WordForge, che si configura come un'applicazione per uso off-line e tale rimane.129
Infine, volendo evidenziare altri aspetti critici di WordForge, va messa in evidenza la grande difficoltà riscontrata nel reperire documentazione, ai limiti della totale inesistenza, cui sono da ascrivere le imprecisioni eventualmente presenti in questa sezione. Come già detto, inoltre, l'interfaccia grafica del programma (non tradotta in italiano) tende a essere sovraccarica e a ‘bombardare’ l'utente con una molteplicità di schede, linguette, finestre, pulsanti e opzioni di personalizzazione un po' oltre i limiti del necessario.
3.3.8 Gtranslator
| Autori: | P. Sanxiao, J. J. Sánchez Penas et al. |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://projects.gnome.org/gtranslator |
| Versione: | 1.9.13 (novembre 2010) |
Gtranslator è il programma di localizzazione per GNOME, nato e sviluppatosi come editor di file PO/POT, presenta un gran numero di ottimizzazioni per questo formato di file di risorse ma non supporta altri formati in ingresso.
«Do one thing, and do it well!» si potrebbe affermare, parafrasando una delle più celebri espressioni della filosofia UNIX, la quale però ben si adatta anche allo spirito che anima tutto il parco software di questo diffusissimo ambiente desktop ed è forse la ragione principale del suo successo.
Come la maggior parte delle applicazioni GNOME meno recenti, il programma è scritto in C, si appoggia inoltre al celebre toolkit grafico GTK+. Il metodo più semplice per installarlo è affidarsi al gestore di pacchetti predefinito della propria distribuzione: in un sistema Debian (o simili) è sufficiente installare il pacchetto omonimo. In alternativa, sul sito del progetto sono disponibili i sorgenti e le istruzioni per la compilazione.
La modalità di lavoro predefinita di Gtranslator è sui singoli file. Pur non essendo supportata la possibilità di creare e salvare interi progetti, è possibile, aprire più file allo stesso tempo per la modifica, che saranno visualizzati in altrettante schede al di sotto della barra dei menu e della barra degli strumenti principale.
L'area di lavoro principale è suddivisa in cinque aree: la lista delle stringhe, il campo contenente il testo originale, il campo di modifica con il testo tradotto, una sezione per le corrispondenze nel database dei messaggi tradotti e, infine, un'area riservata ai commenti PO e ai file ausiliari. L'interfaccia grafica è completamente localizzata in italiano.130
È consentito un minimo di personalizzazione dell'interfaccia, ad esempio, aggiungendo alcuni pulsanti per la navigazione o la modifica dell'intestazione del PO.
La navigazione fra i messaggi è consentita secondo le consuete modalità: sequenziale, per numero identificativo o in base allo stato (fuzzy, non tradotto o una delle due possibilità senza distinzione) sia da tastiera che dall'interfaccia grafica. È possibile spostarsi anche selezionando un messaggio dalla lista delle stringhe che, a sua volta, può essere disposta in base allo stato (tradotto, non tradotto o fuzzy) in ordine crescente o decrescente di interventi necessari, al numero identificativo (crescente o decrescente) oppure in base al contenuto del segmento da tradurre o tradotto in ordine alfabetico (o alfabetico inverso).
Il campo di testo contenente il testo sorgente è protetto dalle modifiche accidentali da parte dell'utente, che può immettere la traduzione nel campo di modifica sottostante. Se sono abilitati gli appositi plug-in interni, il programma integra funzionalità di evidenziazione della sintassi nei sorgenti e rende visibili i caratteri di spaziatura.
Nel caso in cui fossero presenti tag (ma non entità XML, che non sono riconosciute ma solo evidenziate perché contengono il carattere di ‘e commerciale’) è possibile inserirli sia in maniera sequenziale (Ctrl-Maiusc-I) sia dal menu Modifica/Inserisci tag che permette di scegliere il tag appropriato da un menu qualora nel segmento sorgente ne fossero presenti più di uno. È anche possibile copiare interamente il testo sorgente di un messaggio nel campo di modifica.
Il programma mostra un riconoscimento parziale ai placeholder, chiamati in questo contesto ‘parametri’, ma soltanto se sono nel formato tipicamente adottato da GNOME, cioè come le variabili utilizzate con la funzione printf del C (%s, %d, eccetera).131 È possibile inserire i placeholder secondo le stesse modalità dei tag, ossia in ordine sequenziale da tastiera (Maiusc-Ctrl-K) oppure, se sono più di uno e non si rispetta l'ordine, attraverso il menu.
Lo stato un un messaggio può essere impostato a fuzzy dall'utente o un messaggio fuzzy può essere impostato come tradotto (Ctrl-U). Come politica predefinita tutti i messaggi fuzzy che subiscono una modifica da parte dell'utente vengono impostati come tradotti ma il comportamento può essere modificato dalla finestra delle impostazioni del programma (non è invece possibile impostare a fuzzy tutti i messaggi modificati in vista di una futura validazione).
Un'ultima caratteristica da sottolineare per quanto concerne la modifica dei messaggi è la funzionalità di correzione ortografica, che si appoggia a GtkSpell, libenchant e ai dizionari Hunspell presenti nella maggior parte dei sistemi. Il controllo ortografico in modalità interattiva su più messaggi, invece, non è disponibile, così come non viene offerta alcuna funzionalità di completamento automatico per l'inserimento facilitato del testo.
Gtranslator dispone di una semplice funzionalità di ricerca, con eventuale sostituzione, su tutti i messaggi di un file di risorse. È consentito distinguere fra maiuscole e minuscole, includere o escludere i messaggi fuzzy dalla ricerca o cercare solo ‘parole intere’ (cioè \b…\b), ma senza alcun supporto alle espressioni regolari.
 |
La TM, che nelle precedenti versioni del programma era chiamata ‘learn buffer’, consiste come nel caso di Lokalize in un database in formato SQLite memorizzato nella cartella delle impostazioni locali del programma.132 Dalla scheda ‘Memoria di traduzione’ delle impostazioni del programma è consentita l'importazione di una directory contenente una raccolta di file PO, di cui è possibile specificare un ‘modello’ di nome file in modo da selezionare la lingua corretta nel caso in cui questa directory fosse multilingue. La TM viene progressivamente incrementata con l'utilizzo del programma ogni volta che si traduce un messaggio.
I messaggi della TM, come negli altri programmi CAT, sono riproposti durante la fase di traduzione: in Gtranslator, tuttavia, è possibile disabilitare il recupero di corrispondenze dalla memoria per i messaggi marcati come tradotti al fine di evitare una possibile fonte di distrazione. La soglia di corrispondenza al di sotto della quale le TU non sono visualizzate è personalizzabile, ma non in base alla percentuale, come avviene nella maggior parte degli strumenti, bensì in base al numero di parole che possono essere presenti in più nel messaggio originale rispetto al contenuto della TM e al limite massimo di tolleranza sulla lunghezza delle TU.
Se confrontato con gli altri programmi visti in precedenza, si tratta di un sistema abbastanza semplicistico e non sempre attendibile: ad esempio, il programma assegna un valore più alto di somiglianza a messaggi in cui manca un'intera parola, rispetto a messaggi in cui cambia solo una lettera (che potrebbe semplicemente essere la correzione di un errore ortografico nell'originale). Infatti anche solo il cambiamento di una lettera viene interpretato come la modifica di un'intera parola.
Quando i messaggi sono recuperati dalla TM, compaiono nella relativa area della finestra principale in accompagnati da una barra che mostra la percentuale e il livello di somiglianza e la scorciatoia (Ctrl-0, Ctrl-1, ecc.) per l'inserimento facilitato (lo zero corrisponde alla corrispondenza più alta).
A partire dalla versione 1.9.11, invece, è possibile rimuovere anche voci dalla memoria di traduzione quando è aperto per la modifica il messaggio corrispondente. Per eliminare la TU è sufficiente fare clic col destro sulla corrispondenza esatta che viene riportata dalla TM dopo che il messaggio è stato tradotto e scegliere l'opzione Rimuovi dal menu contestuale,133 resta tuttavia da capire l'utilità di rimuovere manualmente una TU dalla memoria.
L'approccio di Gtranslator alle TM, se osservato con un po' di attenzione, lascia aperte non poche perplessità. La modalità di recupero dei messaggi dalla TM è, come si è visto, un po' troppo semplice per dare risultati attendibili.
Inoltre, i messaggi tradotti vengono aggiunti immediatamente alla TM una volta che sono stati approvati, dopodiché vengono sempre mostrati come corrispondenze esatte anche ritornando nello stesso punto del file da cui sono stati aggiunti.
Questo dà continuamente l'impressione che ci siano match interni anche se in realtà si tratta dello stesso messaggio e con tutta probabilità è per questo che il programma fornisce l'opzione (unica nel suo genere) per disabilitare il recupero delle corrispondenze nel caso dei messaggi tradotti.
Un altro problema non indifferente nel recupero dei segmenti dalla TM è nelle corrispondenze fuzzy: non solo non sono evidenziate le differenze del sorgente con il testo sorgente del messaggio corrente, ma non viene mostrato affatto il segmento sorgente della TU presente in memoria, e questo rende molto difficoltosa l'individuazione delle parti che non corrispondono nel messaggio corrente, soprattutto se la dimensione del messaggio va oltre le poche parole.
Per quanto riguarda la gestione delle TM, ancora una volta il programma mostra alcune limitazioni abbastanza rilevanti. In primo luogo è possibile utilizzare una sola memoria comune a tutte le sessioni e questo alla lunga, se si lavora in progetti diversi, porta alla creazione di TM di grandi dimensioni in cui la commistione di TU di ambiti diversi rischia di generare più confusione che aiuto al traduttore. L'unica soluzione a questo inconveniente sembra essere la rimozione ‘brutale’ del file della TM, che sarà rigenerato automaticamente all'apertura di una nuova sessione.
Inoltre, lo scambio di dati con la TU lascia a desiderare sotto molti aspetti. L'importazione è consentita solo dal formato PO, ma non è possibile esportare i segmenti senza ricorrere a strumenti esterni, ad es. unire i PO dei file tradotti in un unico catalogo e utilizzare quest'ultimo come TM (o convertirlo in TMX per importarlo in un altro programma). Altrettanto poco immediata è l'importazione di dati da TMX, che devono essere previamente convertiti in PO per poter essere letti dal programma.
Gtranslator comprende una serie di ottimizzazioni per il formato PO: in primo luogo il supporto alle forme plurali, che vengono gestite con lo sdoppiamento su due ‘linguette’ del campo di modifica.
Inoltre nell'area relativa ai commenti, sono visualizzabili i più importanti metadati associati ai messaggi dall'infrastruttura GNU Gettext. In particolare, sono visibili i commenti estratti automaticamente e i commenti del traduttore, che possono anche essere modificati o integrati direttamente dall'interno del programma. Anche i contesti di disambiguazione sono riconosciuti correttamente.
Non sono invece visualizzati i campi identificativi precedenti nel caso dei messaggi marcati automaticamente come fuzzy da msgmerge (coerentemente con l'idea per cui non è necessario mostrare l'originale di una corrispondenza parziale in TM). Nemmeno i flag sul formato delle variabili sono visualizzati, d'altronde si è già visto come il programma sia in grado di riconoscere solo il formato printf.
Sono invece presenti i riferimenti al codice sorgente e, se è abilitato il corrispondente plug-in, questi si presentano sotto foma di ‘link’ su cui è possibile fare clic per visualizzare in un apposito visualizzatore esterno il codice sorgente alla riga specificata nel commento. Perché questo accada è però richiesto che il file sorgente sia presente nella stessa directory dov'è memorizzato il file PO su cui si sta lavorando.
Un'ultima utile caratteristiche riguardo l'elaborazione del formato PO è la modifica dell'intestazione, sia manuale (Modifica/Intestazione) che in modalità automatica inserendo nell'intestazione i dati personali del traduttore salvati in fase di configurazione.
Il programma integra infatti una comoda procedura guidata che permette di inserire i dati dell'utente, della lingua e del progetto, nonché di generare automaticamente una TM ‘preliminare’ quando viene avviato per la prima volta.
Le informazioni di questo tipo sono salvate in appositi ‘profili’, accessibili dalla finestra delle impostazioni del programma, permettendo così a una stessa persona di intervenire a diversi livelli nel processo traduttivo, in modo simile a quanto visto per Lokalize, o addirittura per diverse lingue.
Gtranslator può essere esteso grazie a una serie di plug-in, anch'essi scritti in C. Le già citate funzionalità di inserimento facilitato di tag e parametri o di accesso rapido al codice sorgente, ad esempio, sono ottenute attraverso plug-in. Ad esempio, esistono plug-in che permettono al programma di interagire con risorse remote, connettendosi (correttamente a partire dalla versione 1.9.13) al database di Open-Tran per accedere alle risorse terminologiche dei più importanti progetti di SL o di funzionare come client SVN per sincronizzare i file di traduzione o depositare il proprio lavoro.
Anche il confronto con una ‘lingua alternativa’, cioè alle traduzioni in un'altra lingua diversa da quella d'arrivo, è possibile attraverso un opportuno plug-in, una volta inserito il percorso dove questi file (e i relativi messaggi) devono essere cercati.
Altri plug-in utili permettono di avere accesso a una tabella dei caratteri, per inserire i caratteri non presenti nella propria mappatura della tastiera, di consultare dizionari off-line installati nel proprio sistema e di visualizzare il programma a schermo intero.
Per quanto riguarda la QA, invece, è disponibile un plug-in esterno (‘punctuation’)134 in grado di riconoscere differenze nella punteggiatura e nel numero/contenuto dei tag fra segmento di partenza e segmento d'arrivo. Un altro plug-in esterno dello stesso autore permette, invece, di effettuare il controllo ortografico finale su tutto il documento piuttosto che sui singoli messaggi in fase di digitazione, quando è molto probabile che qualche refuso sfugga all'attenzione del traduttore.
La fonte principale di documentazione è il manuale installato assieme al programma in formato DocBook135 tradotto in numerose lingue ma attualmente non in italiano. Pur nella sua estrema semplicità, si tratta di un buon punto di partenza, soprattutto per chi si affaccia per la prima volta al mondo della localizzazione.
D'altronde, altro non ci si può aspettare da un programma che fa dell'efficienza, ma soprattutto della semplicità, uno dei suoi principali punti di forza. Quel che a prima vista può sembrare ‘scarno’ in realtà è frutto di un attento lavoro di selezione e di quel che i latini avrebbero chiamato labor limæ, in pieno accordo con la filosofia GNOME (tenendo conto dei dieci anni di storia di Gtranslatorche risale al 2000 e quindi è di poco successivo alla nascita di KBabel).
3.3.9 Poedit
| Autore: | Vaclav Slavik |
| Licenza: | Licenza MIT |
| Pagina web: | http://www.poedit.net |
| Versione: | 1.4.6 (marzo 2010) |
Poedit, citando la definizione che ne fornisce lo stesso autore, intende essere front-end grafico agli strumenti di GNU Gettext e al tempo stesso un editor di cataloghi di messaggi in formato PO. Essendo multipiattaforma, si propone come un'ottima soluzione anche per contribuire alla localizzazione in ambiente Windows, con il vantaggio di includere nella sua distribuzione in formato binario anche l'infrastruttura GNU Gettext.
Il programma è scritto in C++ e si appoggia al toolkit wxWidgets per l'interfaccia grafica.136 L'installazione può essere effettuata scaricando i sorgenti dalla pagina indicata oppure, dal momento che il programma è incluso negli archivi delle principali distribuzioni GNU/Linux che adottano la pacchettizzazione di binari precompilati, ricorrendo proprio gestore di pacchetti che è in grado di risolvere in automatico le dipendenze (fra cui Berkeley DB per le TM e GtkSpell per la correzione ortografica).
La finestra principale del programma è ridotta all'essenziale e può ospitare fino a un massimo di cinque aree: la lista delle stringhe, il campo sorgente, il campo di modifica e due aree per i commenti tipici dei PO. È possibile aprire per la traduzione solo un file alla volta e non è possibile uscire dal file corrente senza aprirne un altro o chiudere l'intero programma.
 |
L'aspetto che più distingue Poedit dagli altri strumenti visti in precedenza è che aprendo un file PO per la traduzione si lavora come su GNU Emacs: il campo del testo sorgente è protetto da scrittura e nel campo di modifica può essere immesso il testo senza alcun ausilio nel caso di tag, placeholder o altri elementi invariabili. Il programma, dà inoltre per scontato che la pretraduzione, e cioè il confronto con un compendium o con le versioni precedenti del catalogo sia già stato effettuato.
Se invece di aprire un file PO si ‘costruisce’ invece il PO da Poedit, fornendo la posizione del proprio file system in cui sono presenti i sorgenti e lasciando che sia il programma a invocare il parser esterno appropriato (xgettext), per cui fornisce una buona interfaccia di configurazione da cui è possibile selezionare le opzioni (es. le parole chiave per i commenti da estrarre automaticamente), allora il programma effettua automaticamente l'aggiornamento con msgmerge e, di conseguenza la pretraduzione. È in questo senso che la definizione di ‘front-end grafico agli strumenti di GNU gettext ed editor di PO’ si rivela adatta a descrivere il programma.
La navigazione nella lista delle stringhe può avvenire in maniera sequenziale (Ctrl-Su, Ctrl-Giù) oppure a blocchi di dieci unità (Ctrl-PagSu, Ctrl-PagGiù). In realtà gli spostamenti rispecchiano l'ordine della lista delle stringhe che è diverso da quello del catalogo originale: i messaggi non tradotti vengono posizionati sempre in cima alla lista, quelli fuzzy vengono presentati in seconda istanza seguiti poi da tutti i messaggi tradotti in ordine.
L'idea alla base è senz'altro buona, dal momento che vengono anticipati i messaggi che più hanno bisogno dell'intervento dell'utente, tuttavia per spostarsi a uno specifico messaggio o al successivo ignorandone lo stato è richiesto l'utilizzo del mouse o, peggio, di ricorrere alla funzione di ricerca nel documento.
Poedit è dotato infatti di una funzionalità di ricerca interna al documento, eventualmente circoscritta ai limiti di parola e configurabile solo nella distinzione fra maiuscole e minuscole (nessun supporto alle espressioni regolari). È invece singolare la possibilità di cercare una sottostringa nel testo sorgente, nel testo tradotto e/o nei commenti.
I messaggi non sono numerati, anche se è possibile visualizzare nella lista accanto al testo sorgente e alla traduzione il numero di riga del file PO dove compare la stringa sorgente (di utilità alquanto relativa). È prevista invece la possibilità di assegnare fino a dieci segnalibri e di spostarsi rapidamente a uno di questi tramite tastiera.
Lo stato dei messaggi può essere distinto grazie al colore: i messaggi non tradotti appaiono in azzurro e quelli fuzzy in colore ocra. Una voce può essere marcata come fuzzy (Ctrl-U), in alternativa viene considerata tradotta se è stata modificata durante la sessione corrente e marcata con un simbolo sulla sinistra. Altri simboli sono utilizzati nel caso in cui un messaggio sia stato tradotto automaticamente con il contenuto della TM oppure se contiene dei commenti del traduttore.
A parte la poca utilità di segnalare quali sono stati i segmenti tradotti in precedenza e quali invece durante la sessione di lavoro aperta, le lacune più gravi emergono considerando l'utilizzo della TM. Come già detto, questa non viene consultata dinamicamente durante la traduzione, ma solo quando viene aggiornato il catalogo dei messaggi.
Nel caso in cui i messaggi siano recuperati dalla TM, non solo non sono visualizzate le differenze fra il messaggio corrente e il testo sorgente presente in memoria, ma quest'ultimo non è presentato all'utente che si trova nella posizione di dover ‘inferire’ di volta in volta le differenze. In realtà Poedit marca solo i messaggi con il simbolo di un piccolo computer sulla sinistra, ma non segnala nemmeno il livello di somiglianza o di differenza e questo è, relativamente, un difetto. Considerando che la soglia di corrispondenza è impostata secondo le stesse modalità di Gtranslator (massimo numero di parole mancanti e massima differenza tollerata), è quasi positivo che non si visualizzi la percentuale di somiglianza, che potrebbe essere alquanto fuorviante.
 |
La gestione delle TM in Poedit mostra alcuni aspetti positivi e aspetti decisamente migliorabili. Una caratteristica ottima è la possibilità di importare automaticamente tutti i messaggi dai cataloghi compilati presenti sul sistema in uso che, come si ricorderà, in genere si trovano in /usr/share/locale/… o /usr/local/share/locale/…. Questo consente di utilizzare con profitto il gran quantitativo di messaggi già installati nel proprio sistema e rappresenta un buon punto di partenza per iniziare a lavorare come localizzatori. La procedura è invece priva di significato quando, nel caso di un programma cross-platform come il presente, si tenta di eseguire la procedura in un sistema non Unix-like.
Il lato negativo di quest'approccio è però che anche se la TM viene aggiornata a ogni salvataggio con i messaggi tradotti non è possibile riutilizzare il proprio lavoro a meno che non si effettui l'aggiornamento del catalogo.137
Un altro aspetto sicuramente migliorabile è la gestione della TM, presente come Berkeley BD nella cartella delle impostazioni locali del programma. In primo luogo, è possibile utilizzarne soltanto una, che raccoglie tutti i messaggi cui si è lavorato più, eventualmente, tutti quelli importati dai file .mo installati nel sistema in uso senza distinzione alcuna.
In secondo luogo, non è facile, così come si è visto per Gtranslator, importare ed esportare messaggi da un simile tipo di memoria, rendendo preferibile l'appoggio a strumenti esterni se è necessario lo scambio di dati con altri strumenti.
Altri problemi emergono per quanto riguarda gli aspetti più tipici del formato PO, elemento non trascurabile dal momento che questo è l'unico formato gestibile dal programma. L'intestazione del PO è aggiornata al primo salvataggio con i dati immessi nella finestra delle impostazioni personali (‘Modifica/Preferenze’).
Nonostante, però, tra queste impostazioni sia necessario inserire la stringa necessaria a gettext per il calcolo del plurale, il programma non riconosce correttamente i messaggi con una forma plurale. Non solo questa non viene visualizzata, ma al primo salvataggio i campi msgstr vengono cancellati e i msgid e msgid_plural inglesi si trovano sprovvisti di traduzione. Se è abilitata la compilazione automatica, l'utilità msgfmt riporta un messaggio di errore ma, a differenza di GNU Emacs in cui in casi estremi è possibile uscire dal po-mode e apportare le correzioni necessarie, in questo caso non resta altra soluzione che chiudere il programma e procedere ‘a mano’ con la correzione.
Se, da una parte i commenti estratti automaticamente e i commenti del traduttore sono visibili (e modificabili, questi ultimi) non altrettanto si può dire dei flag sul formato delle variabili, dei campi identificativi precedenti e dei contesti di disambiguazione. I riferimenti al codice sorgente invece possono essere visualizzati solo facendo clic col pulsante destro sul messaggio nella lista delle stringhe (non molto visibili, in questa posizione): selezionando il riferimento dal menu contestuale, viene aperto un visualizzatore direttamente alla posizione interessata.
Il fatto di generare il catalogo dei messaggi a partire dai sorgenti dall'interno di Poedit comporta l'ovvio vantaggio che il percorso dei sorgenti specificato in ‘Catalogo/Impostazioni’ per invocare xgettext è anche quello valido per la visualizzazione dei riferimenti. Questa però è forse l'unica comodità cui si va in contro con la gestione diretta dei cataloghi. In primo luogo, infatti, molti progetti di localizzazione, attualmente, distribuiscono direttamente ai traduttori i file di risorse gestendo ‘in proprio’ l'estrazione e l'aggiornamento (es. ‘scripty’ in KDE) e questo svuota in gran parte di significato l'approccio di Poedit.
In secondo luogo, un altro ostacolo è rappresentato dalla costante necessità di mantenere sincronizzato con il sistema di controllo versione non solo il ramo o i rami di localizzazione (come visto in Lokalize) bensì tutto l'albero dei sorgenti per i progetti cui si sta lavorando. Solo una volta aggiornati i sorgenti ‘in locale’ è possibile aggiornare il catalogo di Poedit. Anche ammettendo che sia svolta quest'operazione (non problematica vista la disponibilità e il costo relativamente basso della banda) rimane tuttavia un problema a carico totale del traduttore l'invio del proprio lavoro ai coordinatori del progetto.
Concludendo, Poedit regge molto a fatica il confronto con le altre applicazioni che svolgono concettualmente o stesso ruolo. Il supporto alla terminologia manca totalmente, le TM sono in un formato non standard e non solo la loro gestione è poco flessibile, ma si pongono seri limiti al loro utilizzo anche nei lavori più semplici. Non esiste ancora alcun modo di integrare la traduzione automatica dei messaggi (problema risolvibile come già illustrato per Gtranslator), né la possibilità di visualizzare file ausiliari in una terza lingua. L'inserimento della traduzione non è facilitato per tag o placeholder né tanto meno dall'autocompletamento e l'unico supporto disponibile è la correzione automatica durante la digitazione (che però non funziona in ambienti diversi da GNU/Linux).
La gestione diretta dei cataloghi, valida per progetti di piccole dimensioni o in cui traduttore e sviluppatore siano virtualmente la stessa persona, tende a rappresentare un ostacolo e ad aumentare lo sforzo del collaboratore invece che ad alleggerirlo. Unici due punti a favore di Poedit nella gestione dei PO sono la presenza di uno strumento seppur semplice di QA, cioè l'output di msgfmt, e le statistiche, seppur nella forma più elementare (numero totale messaggi, percentuale di lavoro completato, numero di fuzzy, di non tradotti o ‘non validi’).
La documentazione che accompagna il programma (accessibile come guida in linea) è invece molto completa, presenta tutte le funzionalità in dettaglio e comprende anche una panoramica rapida sugli strumenti di GNU Gettext che permette agli aspiranti traduttori di familiarizzare con i concetti di base della localizzazione del SL (cfr. sez. 2.4.1). Per chi fosse interessato ad approfondire, sempre dalla guida in linea di Poedit è possibile accedere via interfaccia grafica e in formato piacevolmente consultabile all'intera documentazione di GNU Gettext, più volte citata in questo lavoro.
3.3.10 Considerazioni finali
Le applicazioni che sono state discusse all'interno di questa sezione corrispondono alle implementazioni della tecnologia che intervengono in maniera interattiva durante il processo di traduzione, in corrispondenza degli stadi 204 e 207 della classificazione di Melby (cfr. par. sec:melbytech).
In sostanza si tratta degli strumenti che costituiscono l'ambiente di lavoro vero e proprio del traduttore, da cui il nome di Translation Environment Tools (TEnT), in cui l'immissione ‘fisica’ della traduzione (con i relativi problemi come la gestione dei contenuti formattati, ecc…) si combina con aspetti come l'interazione con le risorse a livello di termine (TB) e di segmento (TM).
Questi due tratti distintivi, come si è visto, possono coesistere in misure diverse, con agli estremi soluzioni in cui prevale l'editor di testo (es. GNU Emacs o Poedit) o le funzionalità di leverage delle risorse mentre la modifica del documento è interamente demandata all'esterno (es. Anaphraseus).
Dal punto di vista dell'utente finale le differenze non sono però così evidenti dal momento che in entrambi i casi la situazione di lavoro viene ad essere identica: utilizzando un editor ‘puro’ le funzionalità TM sono svolte a monte da strumenti ausiliari (msginit, msgmerge oppure pot2po), mentre utilizzando un solo strumento TM le funzionalità di editing interattivo sono comunque assicurate da altri programmi.
Un criterio di classificazione ben più significativo è — almeno nell'opinione di chi scrive — la finalità per cui queste applicazioni sono state sviluppate. In questo senso è possibile distinguere due categorie di programmi: gli strumenti CAT general purpose, cioè non specifici per determinati ambiti di applicazione e gli editor di localizzazione (basati su PO) nati invece per uno scopo ben preciso e cui le funzionalità che assicurano sono ancora strettamente connesse.
È vero infatti che nel corso dello sviluppo le differenze fra le due categorie sono andate via via riducendosi, al punto che programmi come OmegaT, nati per scopi generici, permettono di essere impiegati per la localizzazione di software in quanto compatibili con il PO e con altri formati di risorse, mentre dall'altro strumenti quali Virtaal, Lokalize e in misura minore Wordforge si propongono come programmi generici per la traduzione assistita integrando filtri interni per altri formati di file.138
Ciononostante la distinzione rimane valida in termini generali: gli strumenti CAT general-purpose non sempre si dimostrano adatti per la localizzazione delle UI, specialmente nell'ambito del SL dove si utilizza il formato PO. Anaphraseus, ad esempio, non mette a disposizione alcuna ottimizzazione per questo formato e tratta i PO come documenti di testo all'interno di OOoWriter.
Questo può rivelarsi decisamente poco pratico: commenti, flag, riferimenti al sorgente, etichette, intestazioni e quant'altro vengono inutilmente presentati per la traduzione e aggiunti alla TM rendendo difficile individuare tutto e soltanto il contenuto che effettivamente deve essere localizzato.
OmegaT d'altro canto soffre del problema opposto: nonostante i PO siano gestiti correttamente, comprese le forme plurali, presentate come stringhe indipendenti, non è possibile visualizzare dalla finestra principale i commenti e i flag accompagnano le stringhe che invece hanno un ruolo di grande utilità per la traduzione.
Inoltre, come già si è avuto modo di osservare, non è consentito avere più traduzioni diverse per una stessa stringa e questo può rappresentare un serio problema per la localizzazione dei file di interfaccia. Tale ‘funzionalità’, nota come match propagation, rappresenta un ostacolo non indifferente, dal momento che due stringhe uguali tradotte in modo diverso all'interno dello stesso progetto.
Nel caso in cui uno stesso segmento sorgente sia una ripetizione tutte le sue occorrenze verranno trattate come lo stesso segmento e in un PO, se anche nell'originale è presente il contesto di disambiguazione msgctxt, questo viene ignorato. Il risultato è che cambiando la seconda occorrenza del messaggio verrà automaticamente sostituita anche la precedente.
Ecco un esempio di come una caratteristica molto utile, anzi ottima, nel caso della traduzione tecnica, possa dar luogo a seri problemi quando la lunghezza dei segmenti si riduce fino all'estremo dei limiti di parola (come spesso accade nella localizzazione delle UI). Sulla scorta di simili considerazioni appare evidente che i programmi per l'elaborazione di PO sono ancora da preferire e difficilmente sostituibili ai fini dello scopo per cui sono stati progettati.
D'altra parte, è anche vero che gli editor di PO presentano una serie di caratteristiche peculiari come la visualizzazione dei commenti, del codice sorgente e dei file ausiliari, la sincronizzazione con sistemi di controllo versione e la modalità di aggiornamento o di fusione che non troverebbero ragione di esistere in un ambiente di traduzione assistita ‘tradizionale’. Per queste ragioni si ritiene opportuno suddividere le conclusioni in due parti, a seconda della categoria di strumenti trattata.
Strumenti CAT/TM generici
Dalla situazione descritta nelle pagine precedenti emerge la netta superiorità di OmegaT che, per la completezza e l'affidabilità che lo contraddistinguono, è in grado di competere ‘ad armi pari’ con alcuni fra i software di traduzione assistita proprietari ben più costosi.
Il programma presenta infatti una serie di ottimizzazioni particolarmente degne di interesse, come la possibilità di caricare infiniti glossari e TM in consultazione, la personalizzazione delle regole di segmentazione e le ricerche avanzate nel progetto che, assieme ai numerosi filtri interni e alle funzionalità statistiche semplificano e rendono molto più efficiente il lavoro del traduttore.
Per quanto riguarda la rilevazione delle corrispondenze, tanto nelle memorie quanto nei file di terminologia, è interessante notare l'integrazione con utilità di analisi morfologica (tokenizer) che permettono un migliore riconoscimento e quindi la possibilità di sfruttare al meglio le risorse esistenti; funzionalità molto importanti soprattutto pensando agli ‘oscuri’ algoritmi di confronto (su cui poco si può dire) delle ben note soluzioni closed-source.
D'altra parte, la creazione di progetti formati da un numero arbitrario di file e la possibilità di salvare copie di backup in fasi intermedie del lavoro facilitano la gestione del progetto e permettono lo scambio fra membri di un gruppo di traduttori o fra questi ultimi e i revisori, in modo simile a quanto avviene con soluzioni proprietarie che prevedono lo scambio di ‘pacchetti’ di traduzione.
Grazie a OmegaT non solo è possibile scambiare dati fra utenti dello stesso programma, cosa quanto mai utile per la revisione, ma anche utilizzare qualsiasi altro strumento compatibile con gli standard vista l'attenzione degli sviluppatori alla massima portabilità delle risorse, testimoniata dalla compatibilità con il TBX e dall'esportazione delle memorie in TMX nei livelli 1 e 2 dello standard LISA.
Dal punto di vista delle prestazioni negli ultimi due anni sono stati fatti grandi passi avanti, introducendo ad esempio l'analisi delle TM solo nel momento in cui vengono caricati i segmenti. Inoltre, a proposito di velocità di esecuzione, la compilazione dei documenti d'arrivo è molto rapida ed efficiente, il che permette di avere un'anteprima immediata anche prima del termine della traduzione, quasi al livello di WYSIWYG (what you see is what you get).
Oltre alle funzionalità CAT/TM di base considerate finora, OmegaT prevede inoltre una serie di bonus per il traduttore, come il supporto ai dizionari off-line di StarDict, la correzione ortografica automatica durante la digitazione e alcuni strumenti di QA sia interni (verifica dei tag e dei placeholder) ed esterni, come il Languagetool che anticipano gli strumenti dedicati di cui ci si occuperà con maggiori dettagli in 3.4 e 4.4.3.
La più interessante fra tutte le funzionalità aggiuntive, tuttavia, è l'integrazione con la traduzione automatica. Da questo punto di vista, OmegaT si rivela molto all'avanguardia, anche rispetto agli strumenti proprietari più diffusi. Molte voci autorevoli infatti, tra cui lo stesso creatore di Wordfast [Champollion, 2001], sostengono che il futuro prossimo degli esseri umani nella traduzione scritta sarà il solo proof-reading del prodotto dei traduttori automatici.
OmegaT, grazie alla sua versatilità, può essere utilizzato anche per questo genere di post-editing. In tal caso, infatti, non si presenta nemmeno la necessità di preprocessare il documento con costosi o complessi programmi di MT, dal momento che la traduzione automatica può essere realizzata dallo strumento CAT direttamente in fase di inizializzazione del segmento. In questo modo si semplifica di molto la procedura, coinvolgendo una sola persona (il ‘traduttore’ umano incaricato del proof-reading) e una sola applicazione.
Per le sue caratteristiche molto avanzate OmegaT, accanto alla suite Swordfish (cfr. sez. 4.3.2), a Heartsome ad Appletrans (proprietari), rappresenta un'alternativa molto interessante anche per gli utenti di varianti più tradizionali e/o commerciali della famiglia Unix come, ad esempio, Mac OSX.
Non per caso si tratta di uno degli strumenti più diffusi fra i localizzatori di software anche molto importanti come il gruppo italiano di OpenOffice.org. Non è da dimenticare, a proposito della comunità che ruota attorno al programma, il rapporto costante e costruttivo fra utenti e sviluppatori139 e la grande comunità di utenti che sostengono il programma, localizzandone i contenuti, fornendo supporto ai nuovi utenti e producendo documentazione di ottima qualità. Lo sviluppo continuamente attivo, inoltre, lascia sperare che le potenzialità del programma saranno ulteriormente ampliate nei prossimi rilasci.
La situazione è invece molto diversa per Anaphraseus. Nonostante il progetto sia attivo dal 2007, lo sviluppo è portato avanti quasi interamente da un solo sviluppatore e gli ambiziosi obiettivi di sviluppo iniziali non sono ancora stati del tutto raggiunti.
Il programma è particolarmente poco adatto a trattare testi formattati e, come si è detto, gestisce in maniera poco efficiente anche i file di risorse per la localizzazione di software, dal momento che il margine di intervento nella configurazione dei placeable è alquanto ristretto e non è possibile caricare definizioni degli elementi di markup (es. DTD) esterne.
Un altro fattore da considerare è la totale dipendenza dalla piattaforma, dato che per essere utilizzato richiede che sul sistema sia installata una versione della suite di produttività di Oracle (il cui futuro sui sistemi GNU/Linux è abbastanza incerto e tutte le principali distribuzioni stanno migrando a LibreOffice).
Un parziale tentativo di svincolarsi dalla piattaforma sottostante è rappresentato da una versione stand-alone, sulle orme di Wordfast nel passaggio da ‘Classic’ a ‘Pro’. Tuttavia lo sviluppo di questa applicazione sembra procedere abbastanza a rilento e gli ultimi aggiornamenti risalgono al 2009, quindi non è sicuro che l'idea sarà portata avanti.
Per le sue caratteristiche il programma è più indicato per lavori di piccola entità, vista l'impossibilità di creare progetti e le scarse prestazioni con documenti di grandi dimensioni, in cui sia importante visualizzare ‘direttamente’ il testo formattato in fase di traduzione, sfruttando a questo proposito tutta potenza di OpenOffice.org.
Concludendo, in tabella 3 sono riportate le caratteristiche salienti di OmegaT e Anaphraseus in modo da rendere più facile un confronto fra le due alternative. I parametri presi in esame sono in una certa misura ispirati a [Ciola, 2007], anche se quest'ultimo lavoro si concentra sugli applicativi disponibili come software proprietario.
| OmegaT | Anaphraseus | |
|---|---|---|
| Creazione di progetti | ✔ | ✘ |
| Visualizzazione statistiche di progetto | ✔ | ✘ |
| Statistiche sui match in TM | ✔ | ✘ |
| Unità di segmentazione disponibili | frase, paragrafo | frase |
| Editor interno | ✔ | ✘ |
| Correttore ortografico | ✔ | ✔ |
| Inserimento automatico/facilitato tag | ✘ | ✘ |
| Visualizzazione ‘ridotta’ dei tag | ✔ | ✘ |
| Integrazione con machine translation | ✔ | ✘ |
| Modifica regole di segmentazione | ✔ | ✔ |
| Compatibilità con SRX | ✘ | ✘ |
| Supporto standard TMX | ✔ | ✔ |
| Numero TM utilizzabili | ∞ | 1 |
| TU sensibili al contesto | ✘ | ✘ |
| Personalizzazione soglia corrispondenza | ✘ | ✘ |
| Evidenziazione delle differenze in fuzzy | ✔ | ✘ |
| Funzionalità di ricerca in TM | ✔ | ✘ |
| Ricerche avanzate in TM (data, autore) | ✔ | ✘ |
| Ricerca con espressioni regolari | ✔ | ✘ |
| Integrazione con risorse terminologiche | ✔ | ✔ |
| Compatibilità con TBX | ✔ | ✘ |
| Numero glossari utilizzabili | ∞ | 2 |
| Ottimizzazione ricerca terminologica | (plug-in) | caratteri jolly |
| Modifiche dirette ai glossari | solo creazione | ✘ |
| Supporto a dizionari off-line | ✔ | ✘ |
| Marcatura messaggi per revisione | ✘ | ✘ |
Editor di file di risorse
Venendo, invece, alle soluzioni disponibili per la traduzione dei PO, gli approcci possibili alla questione sono essenzialmente tre. Una prima soluzione, la più ‘tradizionale’ da un punto di vista storico, prevede l'uso di un editor di testo fortemente ottimizzato, in cui non sono offerte funzionalità di CAT/TM in senso stretto se non preprocessando il materiale con strumenti esterni (le utilità di GNU gettext), come nel caso di GNU Emacs (sez. 3.3.3).
Con questo programma lavoro diviene molto veloce ed efficiente e, nonostante rispetto alla struttura PO non vi sia alcuna interfaccia di astrazione, le funzionalità non mancano: dalla QA alla consultazione dei sorgenti e dei file ausiliari, dalle statistiche alle modifiche dello stato dei messaggi. L'integrazione con GNU gettext assicura inoltre la massima funzionalità, più di molti altri (parzialmente incompleti) programmi per la localizzazione.140
Ciononostante un ostacolo non trascurabile è che il po-mode, come dice il nome stesso, può essere impiegato solo per i file di risorse in formato PO e quindi il programma resta valido come editor per la localizzazione solo per il SL. L'incompatibilità con XLIFF e l'impossibilità di gestire ‘direttamente’ memorie di traduzione o risorse terminologiche rendono di fatto molto difficile l'utilizzo del programma in altri ambiti.
Un secondo approccio al problema, di cui alcuni esempi sono già stati visti nella sezione 2.4.3, prevede invece la collaborazione dei localizzatori in una piattaforma interamente basata su web, con un editor di traduzione online e la gestione dei vari aspetti del processo di traduzione completamente decentralizzata e, nella maggior parte dei casi, non sotto la diretta responsabilità del traduttore-localizzatore.
Quest'ultimo caso prevede quindi un metodo di lavoro fortemente asimmetrico o ‘decentralizzato’, in cui il traduttore è solo l'anello finale di una catena in cui sono soggetti terzi a detenere il controllo del processo, a creare, amministrare e predisporre per l'utilizzo le risorse di traduzione e a trattare i documenti finali.
In una simile prospettiva poca importanza ha la tecnologia per la traduzione lato utente, dal momento che il processo viene svolto interamente online con l'ausilio di un solo web browser, in una direzione abbastanza divergente dalle premesse di questo lavoro. Nonostante le interessanti potenzialità e implicazioni per il futuro, quindi, si è ritenuto opportuno menzionare per completezza anche questo genere di soluzioni.141
Un terzo gruppo di programmi è invece molto vicino dal punto di vista concettuale ai TEnT ‘classici’, in cui il processo di traduzione avviene contestualmente all'interrogazione di una banca dati contenente le unità di testo tradotte in precedenza e di risorse terminologiche costruite dall'utente (anche se caratteristiche tipiche dei CAT come la segmentazione del testo di partenza, il clean-up, ecc. non sono significative in questa prospettiva).
Le utilità di questo tipo (sez. 3.3.4 e succ.) presentano differenze anche profonde le une dalle altre e sono state disposte dalle più complete a quelle meno funzionali. Al primo posto si collocano Virtaal e Lokalize che, per motivi diversi, possono essere considerate le alternative migliori per la localizzazione.
I principali punti di forza di Lokalize sono il supporto ai progetti (con TM separate), le ottime funzionalità di ricerca e l'interfaccia per la modifica interattiva dei glossari, unica nel suo genere. Non sono da dimenticare anche le ottimizzazioni nel recupero delle corrispondenze dalla memoria, il controllo ortografico e le funzionalità avanzate utili al localizzatore (es. sincronizzazione e fusione).
Virtaal invece, oltre che per l'avanzato riconoscimento di placeable e convenzioni ortografiche, si distingue per il suo orientamento deciso verso le risorse online: l'integrazione con Open-Tran, i glossari di progetto scaricabili automaticamente, le TM remote, i motori di traduzione automatica, il ‘web look-up’ dalla finestra principale, ecc…
Anche in questo caso il supporto alla terminologia è buono, con la possibilità di modificare in parte i glossari, il supporto nativo al TBX e ai glossari di OmegaT e un abbozzo di funzionalità di stemming. Nonostante l'interfaccia apparentemente scarna (in realtà volutamente semplice e pulita) si dimostra a tutti gli effetti un'applicazione moderna e proiettata verso il futuro grazie anche alla comunità molto estesa che ha alla radice.
Curiosamente questi progetti sono fra gli ‘ultimi arrivati’ nel campo della localizzazione (risalgono uno al 2007 e l'altro al 2008) ma nonostante questo si dimostrano superiori alle alternative preesistenti e con cui si pongono in competizione, escludendo il caso di KBabel, che è stato intenzionalmente rimpiazzato da Lokalize (e per questo non considerato ai fini di questo lavoro).
Wordforge, inizialmente conosciuto con il nome di ‘Pootling’, è il primo editor per la localizzazione sviluppato in proprio all'interno della WordForge Foundation nata dagli sforzi congiunti di Translate.org.za e di KhmerOS. Anche se di fatto entrambe le associazioni hanno collaborato alla creazione e alla crescita di Pootle e del TTK, la prima ha proseguito in maniera autonoma sviluppando Virtaal proponendo quest'ultimo come scelta consigliata agli utenti.
Wordforge permette di ottenere il massimo dagli strumenti del TTK, la stessa base su cui è costruito Virtaal, attraverso una comoda interfaccia grafica. In questo modo è possibile ottenere le conversioni fra formati di file, l'importazione e l'esportazione da TMX, il calcolo di statistiche sui singoli documenti (anche con il calcolo dei match) e, soprattutto, gli ottimi filtri di QA integrati che rappresentano tutt'ora un'eccezione (esclusi i controlli di base di Emacs) rispetto alla norma.
Inoltre, permette di superare in maniera molto elegante i problemi ‘congeniti’ di prestazioni con TM di grandi dimensioni e a questo proposito, è in grado di svincolarsi dal database fisico con la pretraduzione e l'inserimento delle corrispondenze come traduzioni alternative direttamente nel documento principale, garantendo la massima velocità e portabilità. Parimenti la possibilità di inglobare un glossario nei file bilingui XLIFF libera il file di traduzione da risorse locali, facilitando il ripristino e la condivisione di dati fra più traduttori, una funzionalità unica fra tutti gli strumenti qui considerati.
Ai numerosi aspetti positivi che il programma ha all'attivo, tuttavia, non sembra corrispondere un pari riconoscimento in termini di adozione da parte degli utenti almeno allo stato attuale. La pagina principale del progetto non è raggiungibile da mesi, il programma non è molto pubblicizzato all'esterno di KhmerOS e in molti aspetti si nota che manca il ‘traino’ di una comunità di utenti molto nutrita: ad esempio, non è realizzata la localizzazione in molte lingue (fra cui l'italiano) e la documentazione, in formato ‘tradizionale’ o wiki, è quasi del tutto inesistente. A questo proposito la situazione è abbastanza esemplificativa di quel che può accadere a progetti di SL in caso di condizioni sfavorevoli.
Gli ultimi due programmi presentati, Gtranslator e Poedit, sono per certi versi dotati di meno funzionalità e più difficilmente applicabili a contesti diversi dalla localizzazione di SL dato il mancato supporto a formati diversi dal PO (in particolare lo XLIFF). Entrambe le applicazioni, inoltre, non offrono all'utente alcun controllo sulla terminologia, operano con TM in formato non standard senza alcuna possibilità di esportazione facilitata e adottano una politica di confronto fra TU ai fini delle corrispondenze alquanto discutibile.
Se il primo però può essere esteso tramite plug-in e reso più simile ai consueti ambienti di traduzione, il secondo appare molto meno versatile.142 È vero che, in linea di principio, piuttosto che implementare male una caratteristica rendendola di fatto inutile o introducendo possibili malfunzionamenti nel programma è meglio non implementarla affatto. Ma quando esistono alternative migliori, più potenti e, soprattutto, ugualmente libere, ha più senso scegliere il programma che meglio si adatta alle esigenze attuali del localizzatore.
Se Gtranslator e Poedit hanno una limitata applicabilità al di fuori della localizzazione del SL per il solo supporto al PO, una considerazione per certi versi ancor più restrittiva vale per Qt Linguist che nasce essenzialmente per i file di risorse .ts utilizzati per la localizzazione di molte applicazioni realizzate con il toolkit grafico Qt di Nokia.143
Nonostante molte delle ‘tradizionali’ applicazioni Qt per GNU/Linux (basti pensare a tutti i programmi di KDE) utilizzino con successo il formato PO di GNU Gettext, le Qt prevedono in alternativa un workflow proprio, destinato principalmente alle applicazioni cross-platform, in grado di svincolare i programmi dall'infrastruttura GNU Gettext tipici di GNU/Linux.144
La procedura per la localizzazione è molto simile, in linea di principio, a quanto esposto nella sezione 2.4.1, che non a caso è stata descritta in quanto rappresentativa delle questioni che si pongono a qualsiasi livello. I sorgenti devono essere preparati invocando la funzione tr() in cui l'array di caratteri che rappresentano la stringa traducibile viene passato come parametro. Lo strumento lupdate genera o, a seconda dei casi, aggiorna il file di risorse; questo viene modificato dal traduttore e in seguito ‘compilato’ in un (formato .qm) che può essere caricato direttamente dall'applicazione localizzata a run time.
La localizzazione con Qt Linguist, tuttavia, presenta in maniera ancora più amplificata gli stessi problemi riscontrabili con GNU Gettext. In primo luogo utilizza strumenti propri e un formato proprio per i file di risorse, sebbene anche le altre applicazioni (fra cui Virtaal in maniera automatica) ne permettano l'elaborazione grazie ai convertitori del TTK ts2po/po2ts che ne riconducono il trattamento a quello dei PO.
In secondo luogo, come GNU Gettext agli inizi, adotta un formato proprio anche per le risorse di traduzione e cioè il .qph, che ostacola la condivisione delle TM e costituisce un ulteriore potenziale limite all'applicazione su larga scala del programma. Tuttavia, essendo il framework Qt rilasciato sotto tre possibili licenze GPL (versione 3), LGPL o commerciale esso è impiegato anche in applicazioni proprietarie e, data la sua vocazione ai dispositivi mobili e alle tecnologie orientate al web,145 è probabile che un investimento di tempo e risorse possa valere la pena anche per gli aspiranti professionisti della localizzazione che potrebbero trovarsi a operare con questi strumenti anche in ambito lavorativo.
Oltre ai problemi di compatibilità dovuti all'utilizzo di formati propri e strumenti propri per la gestione del lavoro, un altro problema comune a molti editor per la localizzazione disponibili come SL è rappresentato dalla riservatezza dei dati.
La maggior parte degli strumenti considerati usano una TM locale predefinita (spesso in formato non TMX) non modificabile direttamente dall'utente, ragion per cui oltre a mescolare segmenti provenienti da più file, da più fonti e potenzialmente da più lingue, creano un potenziale problema per la confidenzialità dei dati.
In tal modo, informazioni potenzialmente riservate restano salvate nella postazione di lavoro e l'utente non ne ha il pieno controllo. Si tratta di un problema irrilevante nel caso in cui si abbia a che fare con la localizzazione di SL, dal momento che anche i file di risorse sono accessibili a tutti e in genere coperti dalla stessa licenza (libera) sotto cui è rilasciato il programma localizzato tuttavia, nel caso in cui si intendesse avvalersi di questi strumenti per scopi ‘personali’ il problema può manifestarsi con maggiore gravità.
Per concludere, anche questa sottosezione è completata da uno specchietto riepilogativo (tabella 4) che mette a confronto le funzionalità di tutte le applicazioni presentate, mettendo in luce i principali punti di forza e di debolezza di ciascuna alternativa, ispirato in parte dall'omologa tabella disponibile all'indirizzo http://translate.sourceforge.net/wiki/guide/tools/comparison.
| Emacs | Lokalize | Virtaal | Qtlinguist | WordForge | Gtranslator | Poedit | |
|---|---|---|---|---|---|---|---|
| Creazione di progetti formati da più file | ✔ | ✔ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Visualizzazione statistiche di progetto | ✔ | ✔ | ✘ | ✔ | ✔ | ✘ | ✘ |
| Statistiche ponderate sui match in TM | ✘ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Correttore ortografico | ✔ | ✔ | ✔ | ✘ | ✔ | ✔ | ✔ |
| Inserimento automatico/facilitato tag | ✘ | ✔ | ✔ | ✘ | ✘ | ✔ | ✘ |
| Integrazione con MT | ✔ | (script) | ✔ | ✘ | ✘ | ✘ | ✘ |
| Supporto allo standard TMX | n. p. | ✔ | importaz. | ✘ | ✔ | ✘ | ✘ |
| Supporto XLIFF | n. p. | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ |
| Numero di TM locali utilizzabili | n. p. | 1; | 1 | ∞ | 1 | 1 | 1 |
| TU sensibili al contesto (penalità, ecc.) | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| Personalizzazione soglia corrispondenza | n. p. | ✘ | ✔ | ✘ | ✔ | ✔ | ✘ |
| Evidenziazione delle differenze in fuzzy | ✘ | ✔ | ✔ | ✘ | ✔ | ✘ | ✘ |
| Funzionalità di ricerca in TM | n. p. | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ |
| Ricerche avanzate in TM (data, autore) | n. p. | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ |
| Ricerca con espressioni regolari | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ |
| Integrazione con risorse terminologiche (locali) | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ |
| Compatibilità con lo standard TBX | n. p. | ✔ | ✔ | ✘ | ✔ | ✘ | ✘ |
| Numero di glossari locali utilizzabili | n. p. | 1 | ∞ | ∞ | 1 | nessuno | nessuno |
| Ottimizzazione ricerca terminologica | n. p. | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ |
| Modifiche dirette ai glossari | n. p. | ✔ | creaz. | ✔ | ✘ | ✘ | ✘ |
| Evidenziazione della sintassi | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| Consultazione file ausiliari (terza lingua) | ✔ | ✔ | ✘ | ✔ | ✔ | ✔ | ✘ |
| Marcatura messaggi come fuzzy | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Visualizzazione commenti estratti automaticamente | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Visualizzazione riferimenti al sorgente | ✔ | (script) | ✔ | ✔ | ✔ | ✔ | ✔ |
| Accesso rapido al codice sorgente | ✔ | ✔ | ✘ | ✔ | ✘ | ✔ | ✔ |
| Visualizzazione commenti del traduttore | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Inserimento commenti del traduttore | ✔ | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ |
| Visualizzazione campi identificativi precedenti | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ |
| Visualizzazione contesti di disambiguazione | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| Verifiche di QA sui messaggi tradotti | ✔ | (script) | ✘ | ✔ | ✔ | ✘ | ✔ |
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/