4.4 L'infrastruttura Okapi
| Autore: | Yves Savourel |
| Licenza: | GNU LGPL |
| Pagina web: | http://okapi.opentag.com/index.html |
| Versione: | 0.10 (gennaio 2011) |
Il gruppo di applicazioni Okapi rappresenta il tentativo di fornire un insieme di strumenti dalle molteplici finalità, adatto a intervenire in più fasi del processo di traduzione, dalla creazione delle risorse preliminari al controllo qualità. Si tratta infatti di una serie di strumenti strettamente integrati e progettati per essere utilizzati in successione per portare a termine i compiti del project manager e del traduttore.
Da questo punto di vista si tratta di un'eccezione rispetto a tutte le applicazioni presentate in questo capitolo e nel precedente. In tutti gli altri casi le utilità di traduzione assistita possono essere classificate in una precisa categoria funzionale senza troppe difficoltà: ognuna svolge infatti un solo compito di base senza la ‘pretesa’ di essere una soluzione universale o una suite completa.
In un simile scenario il workflow può essere ‘costruito’ utilizzando in sequenza gli strumenti disponibili, grazie all'interoperabilità garantita dall'applicazione degli standard aperti, estendendo eventualmente lo scopo di applicazione oltre l'idea originaria.175
Nel caso di Okapi invece non solo le varie parti nascono già per essere utilizzate in sinergia ma uno stesso strumento può avere più funzioni anche eterogenee all'interno del processo traduttivo. Rainbow, ad esempio, può essere impiegato sia per l'allineamento/segmentazione che per la traduzione automatica, sia per convertire fra formati diversi che per validare un documento basato su XML, sia per estrarre la terminologia che per le verifiche di QA.
Dal momento che era impensabile replicare nelle varie sezioni ‘funzionali’ del precedente capitolo le stesse utilità presentandole di volta in volta in veste diversa,176 si è ritenuto opportuno dedicare uno spazio separato alle applicazioni Okapi anche sulla scorta del fatto che l'infrastruttura comprende strumenti di natura più propriamente ‘ausiliaria’ che si prestano a essere inclusi in questo capitolo (cfr. 4.4.3 e 4.4.4).
Inoltre, a differenza del TTK che è indirizzato in via quasi del tutto esclusiva ai localizzatori di SL e ai coordinatori dei progetti di localizzazione o della suite PO4A che è destinata agli sviluppatori di software e ai manutentori della documentazione, l'infrastruttura Okapi è rivolta anche e soprattutto ai traduttori di ogni ambito e per scopi di portata più ampia.
Lo sviluppo iniziale del progetto era basato sulla piattaforma .NET di Microsoft e la sua esecuzione in un sistema GNU/Linux avrebbe comportato inevitabilmente il ricorso all'implementazione open source Mono.177
In una fase successiva, per la maggior parte delle applicazioni è stato fatto il port in Java, rendendo possibile l'esecuzione dei programmi con la sola installazione di OpenJDK. Per alcune parti dell'infrastruttura Okapi, come Olifant (uno strumento di modifica interattiva avanzata di dati e metadati contenuti nelle memorie di traduzione) e Abacus (utilità di conteggio parole e statistiche), il processo di transizione non è ancora completo.
Ai fini del presente lavoro, tuttavia, sono state considerate solo le applicazioni disponibili nella distribuzione ‘okapi-apps’ predefinita, disponibile per il download dal portale del progetto. Per avere a disposizione questi strumenti è sufficiente scaricare l'archivio per GNU/Linux (in base alle caratteristiche della propria architettura) e decomprimerlo. Gli script per l'avvio facilitato dei programmi (es. rainbow.sh) sono già forniti assieme agli archivi e alle librerie degli stessi.
In maniera simile al TTK, inoltre, Okapi rappresenta una vera e propria infrastruttura le cui componenti Java (pacchetti di classi, interfacce, ecc.) possono essere riutilizzate per la creazione di nuovi programmi, in virtù della licenza LGPL.
In piena coscienza del fatto che non si tratta di una separazione totale e del tutto corretta dal punto di vista concettuale, è possibile distinguere tre categorie all'interno delle componenti di Okapi: i filtri, gli step e le utilità.
I filtri predefiniti Okapi consentono di avere accesso al contenuto di documenti in diversi formati di partenza ad es. HTML, OpenOffice, OpenXML di Microsoft Office, testo semplice, ecc.178
Questi non si applicano però solamente agli originali del processo traduttivo, ma operano anche sui formati ‘intermedi’ del processo di traduzione: esistono infatti anche filtri per i documenti TTX di Trados, TMX, PO, XLIFF e così via. Inoltre, tutte le utilità predefinite possono essere integrate con nuovi filtri definiti dal programmatore.
Da un punto di vista superiore, l'applicazione di un filtro comporta è un'operazione atomica: un documento di partenza viene processato producendo unità di informazione (‘eventi’). Nel caso del filtro, l'evento è associato a tre distinti tipi di informazione: la componente testuale, le proprietà (parte non testuale che può o non può essere modificata, es. attributi, ecc.) e il cosiddetto scheletro, che rappresenta le informazioni strutturali.
Generalizzando e semplificando fino all'estremo, in Okapi è possibile distinguere vari tipi di operazioni elementari, ciascuna delle quali produce una serie di eventi. A sua volta gli eventi sono associati a un insieme di dati fisici, le cosiddette ‘risorse’.
Nel caso di un'operazione di filtro, queste risorse sono la componente testuale (TEXT_UNIT), le proprietà (START_DOCUMENT, DOCUMENT_PART, ecc…) ed eventualmente le annotazioni. Come già detto, un filtro può produrre, in aggiunta, anche un ulteriore tipo di informazioni di natura strutturale, ad es. lo ‘scheletro’.
Esistono quindi diversi tipi di eventi, fra cui i principali sono gli eventi di filtro (FE), che prevedono la separazione del documento in componenti ‘discrete’ e standardizzate, e l'evento RAW_DOCUMENT (RD), che permette di trasmettere in blocco le informazioni che compongono il documento.
Okapi mette a disposizione una serie di operazioni elementari predefinite, chiamate step, che costituiscono il secondo tipo di componenti dell'infrastruttura. Gli step sono in genere classificati in base alle informazioni in entrata e in uscita (RD e FE) ed è attraverso gli step che è possibile operare la manipolazione dei dati in Okapi. Oltre a quelli preconfezionati, così come per i filtri, possono essere creati nuovi step in base alle esigenze di applicazione.179
Gli step possono a loro volta essere uniti a formare sequenze (pipeline), che in genere hanno inizio con un'istanza di filtro, operano una serie di trasformazioni sulle risorse e terminano con la scrittura di un documento finale (filter writer) che rappresenta l'operazione inversa a quella operata dal filtro e ricrea la struttura del documento.
In un simile contesto gli ‘eventi’ vengono quindi a rappresentare le unità di informazione che vengono trasmesse da uno stadio all'altro della pipeline. Per creare una pipeline in modo corretto occorre quindi fare attenzione a che l'output (RD o FE) dello step precedente sia compatibile in ingresso con il tipo di evento di input dello step successivo (gli step che possono operare indifferentemente sui due tipi di evento esistono ma non sono numerosi, es. ‘Search and Replace’).
Rainbow, l'interfaccia principale alle componenti di Okapi, è dotato inoltre di un lungo elenco di pipeline predefinite sufficienti già di per sé a coprire molte delle esigenze del traduttore. Strettamente connesso a queste, il terzo tipo di componenti di Okapi è rappresentato da una serie di utilità disponibili sempre attraverso questa applicazione.
In altre parole si tratta di sequenze di operazioni simili alle pipeline dal punto di vista dell'utente, ma che non sono ancora state trasformate in step predefiniti. Due di queste utilità sono particolarmente rilevanti verranno presentate nella sezione successiva specifica dedicata a Rainbow.
Per approfondire i dettagli tecnici relativi all'infrastruttura Okapi sulle pagine del progetto è disponibile una gran quantità di documentazione (in inglese) rivolta agli utilizzatori dei programmi ma soprattutto agli sviluppatori che intendono ricorrere al set di API di Okapi per i propri progetti, nonché un wiki rivolto soprattutto a questa seconda categoria di lettori. Le applicazioni Okapi sono attualmente disponibili in inglese e, se dotate di interfaccia grafica, si appoggiano alle librerie GTK+ tramite lo Standard Widget Toolkit (SWT) di Eclipse per Java.
4.4.1 Rainbow
Rainbow intende dare accesso a una serie di strumenti utili per la traduzione della documentazione di software, delle guide in linea e di tutto il materiale accessorio presente nel processo di traduzione.
Gli strumenti presenti in Rainbow altro non sono che le componenti dell'infrastruttura Okapi cui si è già fornita una concisa introduzione (filtri, step, utilità). Si tratta di elementi virtualmente indipendenti gli uni dagli altri rispetto ai quali il programma svolge solo la funzione di front-end.180
Nella situazione tipica, si tratterà di un front-end grafico, dal momento che il programma è dotato di una GUI ma ciò non toglie che possa anche essere eseguito da riga di comando, specificando i file di input, l'utilità o la pipeline da eseguire e le opzioni del caso. Ai fini della presente concisa trattazione tuttavia ci si concentrerà sull'utilizzo di Rainbow da interfaccia grafica.
Per utilizzare Rainbow è necessario, prima di tutto, specificare i file di partenza nelle apposite liste di ingresso (input list) presenti nella finestra principale. A ogni lista è associata una directory ‘radice’ che rappresenta la posizione predefinita da cui si assume che i file provengano e dove, in assenza di specifiche in senso diverso, saranno salvati i documenti di uscita. La radice della lista di ingresso, in genere la directory ‘home’ dell'utente, può essere modificata da Input/Edit Root (F2).
Per ogni documento aggiunto alla lista di ingresso è necessario controllare l'associazione con il relativo filtro e le impostazioni di quest'ultimo (Alt-Invio). In seguito devono essere impostati i parametri necessari all'esecuzione degli strumenti, specificando lingue e codifica dei documenti di ingresso e di uscita nella relativa scheda del programma e, nell'ultima scheda a destra, altre impostazioni tra cui il nome dei file d'arrivo (in cui può essere inserito un prefisso, un suffisso o un interfisso oppure può essere sostituita l'intera estensione).
Le impostazioni e le liste di file di ogni sessione possono essere salvate in un file di progetto (estensione .rnb), in modo da poter riprendere con facilità il lavoro in un secondo momento.
Dopo aver inserito il o i file di partenza nelle liste di ingresso, è possibile selezionare dal menu Utilities le azioni da portare a termine con Rainbow che possono essere suddivise in tre categorie. In primo luogo è possibile creare la propria pipeline personalizzata, inserendo gli step in base alle proprie esigenze e facendo poi clic su Execute. Una lista di step può anche essere salvata su un file .pln per essere riutilizzata in futuro.
In secondo luogo, è possibile scegliere fra le utilità cui si è accennato in precedenza, vale a dire la creazione di un pacchetto di progetto per l'elaborazione successiva con uno strumento CAT, il post-processing di un pacchetto di progetto concluso preparato con Rainbow, l'allineamento di due file per la creazione di una memoria di traduzione, la modifica della codifica o del BOM nei file UTF-8 e la conversione in RTF. In questo caso l'operazione verrà portata a termine dopo aver specificato le eventuali impostazioni e confermato l'intenzione di procedere.
In terzo e ultimo luogo, esistono una serie di pipeline predefinite, in cui i vari step a disposizione sono già stati assemblati per realizzare le operazioni più importanti specificando (se necessario) alcune impostazioni nella finestra di dialogo Pre-Defined Pipeline e in seguito facendo clic su Execute.
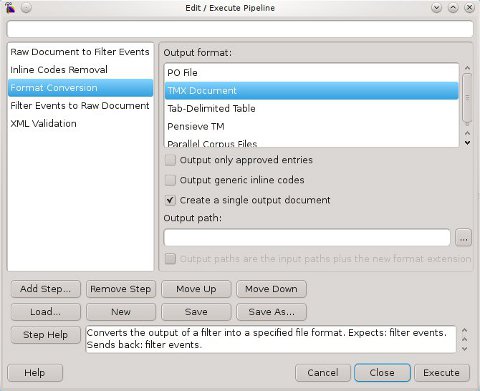
Fra queste vale senza dubbio la pena di citare la ricerca e la sostituzione, anche con espressioni regolari, direttamente sul documento o solo sul contenuto applicando uno step del tipo ‘Raw Document to Filter Events’ prima e un ‘Filter Events to Raw Document’ dopo la sostituzione.
È anche possibile effettuare la conversione dei documenti da un formato all'altro, la modifica i caratteri di fine riga181 l'estrazione della terminologia, il confronto due traduzioni dello stesso documento e una serie di verifiche di QA. In ognuno dei tre casi il programma, dopo l'esecuzione delle utilità, mostra in una finestra temporanea i messaggi di errore e di avvertimento restituiti dall'utilità chiamata in causa, in modo da permettere la correzione di eventuali errori.
Appare evidente che le potenzialità di Rainbow sono limitate, per molti versi, solo dalla fantasia dell'utente che può comporre a seconda delle proprie esigenze i 43 step disponibili. Lo stesso è possibile dire per i file di ingresso e di uscita che spaziano da da OpenDocument a OpenXML (MSOffice), da PO a XLIFF e .ts, da HTML a XML, dal TMX al TTX (Trados) e sono gestiti dai 24 filtri di Okapi.
Le combinazioni risultanti sarebbero veramente troppe per trovare spazio entro i limiti di questo lavoro, tuttavia è altrettanto evidente che alcune pipeline sono molto interessanti perché permettono di colmare alcune ‘lacune’ rispetto a quanto possono fare gli altri strumenti CAT liberi per il traduttore.
Nella rimanente parte di questa sezione verranno quindi presentate alcune simulazioni di casi in cui Rainbow può rivelarsi utile. Gli esempi, in cui si è cercato di mostrare sia l'utilizzo degli strumenti predefiniti che di pipeline personalizzate, illustrano come il programma possa intervenire in diverse fasi del processo traduttivo dall'allineamento alla QA.
 |
Esempi pratici di utilizzo di Rainbow
Un primo ambito in cui Rainbow può essere utile è l'allienamento di file in più lingue per produrre una TM. A questo proposito, come già anticipato, sono disponibili due modalità: il cosiddetto ‘ID-based Alignment’ e il ‘Sentence Alignment’.
Il primo caso può essere ottenuto in due modi leggermente diversi: combinando gli step ‘Raw Document to Filter Events’, ‘Segmentation’ e ‘Id-Based Aligner’ oppure con uno strumento predefinito denominato ‘ID-Based Alignment’ (si noti la differenza nel nome). Il principio di funzionamento è però lo stesso: dati i documenti in un formato in cui le unità di testo siano identificabili univocamente da un ID o etichetta, l'allineatore associa le unità sulla base del loro identificativo.
Questa strategia ha applicabilità limitata, dal momento che è necessario disporre di documenti in cui le unità di testo siano già marcate in modo univoco da degli identificatori (caso però non infrequente nel caso dei file di risorse utilizzati nella localizzazione, es. i .properties Java).
Utilizzando lo step ‘Id-Based Aligner’ (FE → FE) il risultato dell'operazione può essere: o un TMX, nel qual caso i FE rimangono invariati oppure, se non si genera il TMX, negli eventi restituiti ogni unità di testo sarà trasformata in una nuova unità di testo bilingue. Se si ricorre invece alla procedura predefinita, l'output può essere almeno una fra le seguenti possibilità: un TMX contenente l'allineamento, un TMX contenente i segmenti che non è stato possibile allineare o un database in formato Simple TM (uno dei formati tipici di Okapi assieme al Pensieve TM).182
Un ulteriore vantaggio se si sceglie di utilizzare la procedura predefinita è che è possibile avere accesso in caso di errori a una finestra di revisione ‘manuale’ simile per certi versi a quella di Bitext2tmx in cui ogni punto problematico è segnalato con un messaggio di avvertimento ed è possibile tentare la correzione automatica, intervenire direttamente, modificare le regole di segmentazione, unire, dividere, modificare o spostare i segmenti. Nel caso di unità di testo mancanti, è anche possibile operare una pretraduzione automatica per colmare le eventuali lacune presenti nei testi da allineare.183
L'allineamento basato su frase, invece, non è previsto fra le sequenze predefinite ma può essere ottenuto con una semplice pipeline del tipo ‘Raw Document to Filter Events’ + ‘Sentence Alignment’. In questo caso l'operazione di segmentazione non è necessaria perché possono essere caricate delle regole di segmentazione personalizzate fra le impostazioni dello step ‘Sentence Alignment’.
Quest'ultimo accetta FE in ingresso e, nella versione attuale, li restituisce senza alcuna modifica (a differenza di ‘Id-Based Aligner’) ma genera una memoria in formato TMX.
Per questo tipo di operazione tuttavia i documenti devono subire una previa preparazione, in modo da essere già perfettamente allineati e avere lo stesso numero di unità di testo, come la totalità degli strumenti visti nella sezione 3.2.
L'algoritmo di allineamento è in grado di associare le frasi presenti nei due documenti sulla base della loro lunghezza, anche con corrispondenze 1:2, 2:1, 1:0, 2:3 ecc. In tal caso, però, verranno restituiti dei messaggi di avvertimento nel file di log in modo da avvertire l'utente di eventuali errori o perdite di informazione. Non è disponibile invece alcuno strumento di verifica interattiva della struttura allineata prodotta.
Scegliendo la procedura di allineamento automatica ‘ID-Based Alignment’ o inserendo nella pipeline uno step ‘Segmentation’ (FE → FE) prima di una operazione di allineamento ci si trova nella tipica situazione di dover inserire in Rainbow delle regole di segmentazione. In questo caso, il programma è in grado di leggere correttamente lo standard SRX della LISA.184
In mancanza di un documento contenente le regole per la lingua specificata o nella necessità di apportare delle modifiche, questo è possibile facendo clic sul pulsante Edit, che causerà l'apertura di una sessione di Ratel (cfr. 4.4.4). Si rimanda alla relativa sezione per i ulteriori dettagli.
Un altro campo di applicazione molto significativo è l'estrazione della terminologia. Da questo punto di vista si è visto che l'unico strumento disponibile è poterminology (cfr. 4.2.2), il quale però presenta molti vantaggi ma anche alcuni svantaggi non trascurabili: un solo formato di ingresso, un formato non standard di uscita nonché uno scarso supporto alla terminologia bilingue.
Rainbow comprende al suo interno una sequenza di azioni predefinita che permette di ottenere risultati simili, applicando un filtro specifico per il tipo di file in ingresso (RD → FE) e facendolo seguire dallo step ‘Term Extraction’ (FE → FE). L'output di quest'ultimo (FE) può essere ignorato senza problemi, in quanto non ha subito alcuna trasformazione diretta dopo l'estrazione, ma accanto a questo viene prodotto un file di testo semplice contenente i candidati termini e le relative frequenze con cui compaiono nei file di ingresso.
Questo approccio comporta alcuni piccoli miglioramenti rispetto a poterminology. In primo luogo, è possibile estrarre terminologia da tutti i formati supportati dagli oltre venti filtri dell'infrastruttura Okapi: i file possono essere inseriti tutti in una lista di ingresso curandosi relativamente poco del loro formato (è sufficiente che siano nella stessa lingua) senza più essere limitati ai PO o ai formati convertibili in PO.
In secondo luogo, l'output del programma è sempre non standard ma è molto più leggibile e di utilità maggiore se i termini estratti non devono essere utilizzati in ambiti dove si richiedano file PO per la terminologia (es. Pootle o Virtaal); inoltre, di ciascun termine viene mostrata in modo esplicito la frequenza.
Esistono però almeno due svantaggi non indifferenti: da una parte, Rainbow supporta solo l'estrazione di terminologia monolingue e non è in grado di riconoscere equivalenti in lingua d'arrivo nemmeno se in ingresso viene fornito un file bilingue in cui il potenziale ‘termine’ coincide con la lunghezza della TU.
Non ha nemmeno senso, pertanto, parlare di gestione dei sinonimi, dal momento che i termini vengono riconosciuti solo singolarmente.
In secondo luogo, le possibilità di configurazione sono leggermente più ridotte rispetto a quelle illustrate per poterminology: mancano infatti le ottimizzazioni tipiche dei file di risorse (controllo sui termini di dimensione pari a quella della TU, numero di riferimenti ai sorgenti considerato ai fini della rilevanza, ecc.).
I restanti parametri che possono essere configurati sono simili a quelli già visti per poterminology: numero minimo e massimo di parole che possono costituire i termini, frequenza minima con cui un'espressione deve comparire per essere candidata, distinzione fra maiuscole e minuscole, indipendenza delle sottostringhe e stoplist. Inoltre può essere caricata una lista di parole che non possono apparire all'inizio o alla fine dei termini.
Rainbow può anche essere utilizzato per estrarre il contenuto bilingue da un formato chiuso, come il .ttx (tipico di SDL Trados 2007), in modo da poter lavorare sul documento con uno strumento diverso. Nella fig. 45 è rappresentata, a titolo esemplificativo, la finestra di dialogo per la composizione di una possibile sequenza di operazioni adatta a questo scopo.
Il documento bilingue di partenza viene per prima cosa convertito da RD a FE per isolare il contenuto testuale, in seguito viene applicata la conversione in formato TMX (FE → FE), quest'ultimo viene convertito nuovamente in RD e viene eseguita una validazione dello stesso (RD → RD) tramite un file DTD specificato dall'utente.
Il secondo passaggio per poter lavorare sul file con uno strumento aperto consiste nella conversione in XLIFF, che può essere letto e modificato agevolmente sulla maggior parte degli strumenti CAT. Questo può essere fatto in modo molto semplice inserendo il TMX creato nella prima lista di ingresso e utilizzando la creazione di un pacchetto per la traduzione (Utilities/Translation Package Creation). Lo XLIFF sarà posizionato nella cartella di lavoro finale del pacchetto in modo da poter essere elaborato con qualsiasi strumento compatibile con XLIFF fra quelli presentati nella sezione 3.3.
Una delle molteplici funzionalità di Rainbow è la pretraduzione di un documento o traduzione in automatico dello stesso (‘Leveraging’). Il programma è in grado di accettare un file bilingue non tradotto, o contenente delle TU non tradotte dall'umano, e di ‘colmare’ questi vuoti con una risorsa di traduzione esistente.
A questo scopo, sono presenti degli opportuni ‘connettori’ (connectors) che operano come intermediari fra Okapi e TM locali (Simple TM), locali/remote (Pensieve TM, GlobalSight TM, Translate Toolkit TM) o solo remote (MyMemory, TAUS Data Association, OpenTran Web Repository)185 e alcuni fra i più diffusi servizi di traduzione automatica liberi o a pagamento (CrossLanguage, Microsoft Translator, Google Translate e Apertium).
Ovviamente, anche nel caso in cui si disponesse di file TMX locali è possibile sfruttarli per la pretraduzione convertendo la TM in uno dei due formati di Okapi, Simple TM e Pensieve TM prima di processare i file, ad es. con l'utilità Pensieve TM Import.
Se invece è in uso uno servizio di MT locale non accessibile con i connettori di Okapi, lo step ‘Batch Translation’ permette di risolvere il problema specificando il comando da invocare per richiamare il programma, cui verranno passate le informazioni (RD) e producendo come risultato ancora RD.
Grazie a questi potenti strumenti e all'estrema flessibilità di Okapi è possibile, dato un file bilingue colmare anche le lacune di quegli strumenti CAT che non prevedono l'integrazione con la MT. In questo modo, non solo è possibile avere accesso a una varietà più ampia di risorse rispetto a quelle messe a disposizione da OmegaT o Virtaal, ma si ottiene anche il vantaggio di avere un progetto interamente gestibile off-line da parte dell'incaricato della traduzione.
Un breve esempio di applicazione: si supponga di avere un PO tradotto e di voler confrontare la traduzione umana con il risultato di una MT. È possibile quindi cancellare la traduzione con msghack --empty < file.po > -o < file_vuoto.po >, caricare il file ‘ripulito’ dalle traduzioni nella prima lista di ingresso di Rainbow, creare una pipeline con ‘Raw Document to Filter Events’ + ‘Leveraging’ + ‘Filter Events to Raw Document’ e impostando il proprio servizio di MT (es. Google Translate) per la pretraduzione in modo da ottenere un documento tradotto automaticamente.
In seguito le due traduzioni possono essere comparate con la sequenza predefinita chiamata ‘Translation Comparison’ che permette di confrontare fino a tre traduzioni, una per lista di ingresso, generando un TMX oppure un dettaglio in HTML (spaziatura, punteggiatura e uso delle maiuscole possono essere o non essere tenuti in considerazione).
Rainbow permette inoltre di creare pacchetti di traduzione, tramite il menu Utilities/Translation Package Creation. Il procedimento,186 prevede l'inserimento di tutti i file da processare in una lista di ingresso, l'impostazione delle lingue di partenza, di arrivo, della codifica dei documenti originali e di quelli finali e del nome che i documenti dovranno avere dopo il post-processing.
Attraverso l'utilità Translation Package Creation è possibile, quindi, procedere alla creazione vera e propria del pacchetto.
Questo comporta in primo luogo la scelta del formato di lavoro, che dipende dallo strumento CAT da utilizzare per portare a termine il lavoro: XLIFF generico, progetto di OmegaT oppure RTF bilingue (tipico del workflow delle vecchie versioni di SDL Trados con Translator's Workbench + MSWord).
In secondo luogo, è necessario selezionare il nome del pacchetto e la posizione nel file system dove verrà creato. In seguito è necessario specificare se il pacchetto dovrà essere compresso (con l'utilità zip) e se deve essere operata una pre-segmentazione con file SRX (esistenti o creati ‘al volo’ con Ratel).
Infine è possibile specificare se il documento deve essere pretradotto e, in caso affermativo, una risorsa primaria (e in via opzionale una secondaria) come fonte dei segmenti tradotti. Le opzioni disponibili corrispondono ai connettori già illustrati per l'operazione di leveraging e per questi è possibile specificare una soglia di corrispondenza minima affinché i segmenti possano essere recuperati o delle penalità (esclusione) relative ai metadati delle TU.
Al termine della procedura sarà creato il pacchetto con all'interno una serie di file e di directory. Gli originali e i file necessari al post-editing sono conservati nella directory original, mentre nella radice del pacchetto sono salvati un file manifest.xml, anch'esso necessario alla creazione dei documenti finali nonché un report in HTML riguardante il numero di segmenti totali, di corrispondenze esatte, parziali e di segmenti non presenti in memoria.
L'output prevede anche, ovviamente, la creazione di un file di lavoro per ogni documento di partenza (.xlf o .rtf a seconda dei casi) più una serie di TMX. Nel caso di un pacchetto generico basato su XLIFF o su RTF, i file da tradurre e i TMX sono rispettivamente nella directory work e nella radice del pacchetto; nel caso dei pacchetti per OmegaT, invece, verrà ricreata la struttura dei progetti tipica di questa applicazione per cui i file da tradurre si trovano in source e le memorie in tm. In quest'ultimo caso viene creato anche il file omegat.project contenente le impostazioni di progetto.
Tutte le traduzioni che è stato possibile trovare nelle risorse di input, sia il file bilingue di ingresso sia le TM o i servizi di MT impostati in fase di creazione, sono contenute nei TMX del pacchetto. In particolare possono essere generati fino a quattro file TMX: tre per le traduzioni presenti nel documento bilingue di partenza (approved, unapproved e alternate a seconda che fossero state approvate, non approvate o presenti come <alt-trans> nello XLIFF) nonché un file leverage.tmx per le corrispondenze fuzzy recuperate dalla memoria.
Nel caso specifico dei progetti per OmegaT le corrispondenze totali dalla TM e le traduzioni approvate presenti nel documento bilingue sono memorizzate nel file project_save.tmx all'interno della directory omegat, in accordo con le convenzioni tipiche di questo programma.
Una volta che la traduzione del contenuto del pacchetto è stata ultimata, per ottenere i file tradotti nel formato originale è necessaria un fase di post-processing, che può essere realizzata ancora una volta dall'interno di Rainbow inserendo nella lista di ingresso il file manifest.xml del pacchetto, selezionando Utilities/Translation Package Post-Processing. Nella finestra di dialogo Translation Package Manifest è possibile verificare che tutti i file bilingui siano presenti, quali saranno i documenti d'arrivo generati, filtrare i segmenti tradotti da inserire nei documenti d'arrivo (utilizzando solo quelli approvati e inserendo l'originale negli altri casi) o, in alternativa, impostare come approvati tutti i segmenti tradotti che andranno a essere inseriti.
Un ultimo esempio di uso del programma in esame è il controllo qualità delle traduzioni: anche in questo caso i software considerati nella sez. 3.4 si erano rivelati, pofilter in particolar modo, molto validi ma di applicabilità abbastanza limitata. Grazie a Rainbow e all'infrastruttura Okapi è possibile estendere numerosi controlli di QA a tutti i file bilingui supportati. È bene segnalare fin da subito che esistono due modalità di controllo: non interattiva e interattiva.
La prima altro non è che una pipeline di Rainbow in cui al file bilingue viene applicato un filtro (RD → FE) seguito dal ‘Quality Check’. Il risultato prodotto è l'analisi in batch tutti i file presenti nella lista di ingresso generando un dettaglio degli errori in HTML dove questi ultimi sono evidenziati con colori diversi e accompagnati da una breve nota esplicativa.
La modalità interattiva invece consente non solo la rilevazione degli errori ma anche la possibilità di spostarsi da uno all'altro attraverso una comoda interfaccia grafica. Questa funzione, accessibile dal menu Tools/Run Quality Check Session, in pratica apre una sessione di CheckMate dove i file di partenza sono quelli contenuti nella lista di ingresso di Rainbow. Dal momento che le impostazioni dello step di QA, i controlli eseguiti e i messaggi di errore sono identici, si tornerà sui dettagli del procedimento nella sezione 4.4.3 dedicata appunto a CheckMate.
Concludendo, Rainbow può essere visto in un certo senso come il ‘cuore’ di Okapi, dal momento che permette di interagire con tutte le componenti nonché con tutti i programmi principali di questa infrastruttura. Attraverso la sua interfaccia è infatti possibile accedere a Ratel e CheckMate e, attraverso le operazioni di conversione, è possibile effettuare anche molte delle operazioni che tikal svolge invece dalla riga di comando.
Come si ritiene di aver seppur sommariamente illustrato nel ridotto spazio a disposizione, i casi in cui Rainbow può essere utilizzato con profitto sono potenzialmente illimitati. Si tratta infatti di uno strumento flessibile in grado di intervenire in molte fasi del processo traduttivo colmando le lacune degli altri strumenti disponibili come SL e, soprattutto, dalle enormi potenzialità che lasciano ben sperare in ulteriori miglioramenti ed estensioni.
Rainbow, come tutto Okapi, è inoltre corredato da una buona documentazione in rete che spazia dalle guide passo a passo per i principianti alle descrizioni più ‘tecniche’ che strizzano l'occhio ai power user più smaliziati. Volendo a tutti i costi evidenziare un difetto, in alcuni punti il materiale disponibile tradisce forse di essere orientato più a lettori con una certa preparazione tecnica che all'utente comune.187
Come risultato le informazioni possono risultare poco chiare o non abbastanza esplicite in certi punti, lasciando sì al lettore dotato di sufficiente curiosità il piacere della scoperta ma spesso insistendo su tecnicismi relativamente poco utili o comprensibili al di fuori di una ‘cerchia’ di pochi eletti.
4.4.2 Tikal
Si tratta di uno strumento a riga di comando che, appoggiandosi alle librerie Okapi, permette di eseguire alcune fra le operazioni più comuni del processo di localizzazione. Come nel caso di Rainbow, tutta la potenza di tikal sta nel grande supporto ai formati di file garantito dai filtri e dalla versatilità degli step Okapi. La differenza principale fra i due programmi risiede nell'interfaccia: solo testuale nel caso di tikal, principalmente grafica nel caso di Rainbow.
Molto di quanto esposto nella sezione precedente resta quindi ancora valido: ad esempio, la consultazione di TM o servizi di MT e la pretraduzione (leveraging) sfruttano il sistema di connettori già illustrato in precedenza. In maniera analoga le operazioni di conversione, di estrazione del testo e di reinserimento dei contenuti tradotti nel formato originale si appoggiano al sistema di filtri Okapi.
Le operazioni che possono essere svolte da riga di comando con tikal possono essere classificate nelle seguenti categorie:
- estrazione e reinserimento di contenuti verso e da file XLIFF;
- pretraduzione e consultazione delle risorse di traduzione;
- importazione ed esportazione da Pensieve TM;
- conversione in formati bilingui (TMX, PO, TSV e CSV);
Il primo gruppo di operazioni prevede l'estrazione del contenuto da tradurre da documenti monolingui e la creazione di file XLIFF per la traduzione (opzione -x, ‘eXtract’). Il filtro associato a ciascun formato di file in ingresso può essere selezionato in maniera automatica in base all'estensione oppure impostato manualmente con l'opzione -fc e indicando il nome del filtro (es. okf_openoffice).188
Possono inoltre essere impostate le lingue di partenza e di arrivo, la codifica dei file originali e, se si preferisce, un'opzione per disabilitare la copia predefinita del testo sorgente nel segmento destinato a essere modificato dal traduttore (opzione -nocopy).
In fase di estrazione è possibile segmentare il contenuto testuale del documento con le regole di segmentazione predefinite (-seg) presenti nella directory config della posizione in cui sono installate le ‘okapi-apps’ oppure con un file SRX di cui va specificato il percorso completo.
L'estrazione può essere associata, come prevedibile, alla segmentazione e alla pretraduzione del documento con una risorsa di traduzione. In questo caso è possibile specificare il tipo e le opzioni necessarie per accedere alla stessa, ad esempio, -pen per una Pensieve TM (seguita dalla directory che contiene il database dei segmenti) oppure -google per il servizio di MT di Google. Se si utilizza una TM inoltre è possibile specificare la soglia minima di corrispondenza al di sotto della quale le TU sono ignorate e il nome del file TMX contenente quelle che sono state invece recuperate come valide.
A estrazione ultimata si otterrà un documento avente il nome dell'originale seguito dall'estensione .xlf e, a seconda delle opzioni, un file TMX pronti per essere elaborati con qualsiasi strumento CAT che supporti questi due standard aperti. Al termine della traduzione, sempre attraverso tikal, è anche possibile convertire il documento o i documenti tradotti nuovamente nel formato dell'originale.
Per quest'operazione è necessario disporre dell'originale e del file bilingue tradotto nella stessa directory e con gli stessi nomi assegnati da tikal in fase di estrazione. Invocando tikal con l'opzione -m (‘merge’), seguita da un serie di parametri opzionali (codifica di partenza e di arrivo, lingua di partenza e di arrivo, nome della configurazione del filtro) e dal nome del o dei file XLIFF da processare, si ottiene la creazione dei documenti di arrivo.
La procedura finora illustrata con tikal rispecchia molto da vicino la creazione e il post-processing dei pacchetti di traduzione in formato XLIFF generico con Rainbow.
Dal punto di vista concettuale le due azioni hanno la stessa finalità, con la differenza che mentre nel secondo caso si ottiene un pacchetto già organizzato in cartelle, con il contenuto delle TM e dell'eventuale file bilingue di partenza separato in base al tipo e alla qualità delle corrispondenze, mentre in questo caso no.
L'approccio di tikal anche se meno personalizzabile è tuttavia molto più rapido e intuitivo, a meno che non si vogliano modificare le configurazioni di più filtri per documenti di ingresso in formati diversi o ci sia l'esigenza di personalizzare ‘al volo’ le regole di segmentazione (nei quali casi con l'interfaccia a Ratel e la possibilità di modifica delle configurazioni dei filtri, Rainbow diventa di gran lunga preferibile).189
Inoltre, tikal può essere utilizzato per tradurre in modo automatico con una risorsa di traduzione basta su TM o MT una serie di documenti (opzione -t).
In pratica si tratta dell'esecuzione di un'operazione di estrazione ed eventuale segmentazione seguita immediatamente e senza alcuna interazione con l'utente da un merge. In alternativa la risorsa di traduzione può essere solo consultate in riferimento a un segmento di testo specificato dall'utente.
|
Con le opzioni -imp e -exp, il programma è in grado di importare ed esportare dati da un database Pensieve TM in modo simile a quanto visto per Rainbow con l'omonima procedura guidata. Nel caso di tikal il file di input e di uscita è in ogni caso il TMX mentre per le importazioni o le esportazioni da/verso altri formati bilingui è necessaria una conversione.
Infine, tikal è molto utile per convertire documenti mono- e bilingui nei formati PO, TMX e tab-separated utilizzando rispettivamente gli switch -2po, -2tmx e -2tbl. Le opzioni generali da specificare, che ricordano le impostazioni di Rainbow, sono le lingue e le codifiche di partenza e di arrivo.
Inoltre, in modo simile a quanto operato con lo XLIFF nella fase di estrazione con l'opzione -nocopy, è possibile scegliere se il segmento destinato alla lingua d'arrivo debba essere vuoto (trgempty) oppure identico all'originale (trgsource).190
In pratica si tratta di operazioni che sfruttano gli step di Okapi e che possono essere replicate in Rainbow con sequenze base articolate in tre fasi: un ‘Raw Document to Filter Events’, ‘Format Conversion’, ‘Filter Events to Raw Document’. In questo caso l'approccio di Rainbow è utile se la conversione è solo il passaggio intermedio per ulteriori fasi che possono essere aggiunte alla pipeline, se invece lo scopo è solo la conversione, tikal può rivelarsi molto più vantaggioso in termini di economia di tempo.
È possibile osservare, inoltre, che il primo e l'ultimo utilizzo di tikal qui esemplificati rappresentano l'equivalente Okapi della sezione dei convertitori del TTK (cfr. sez. 2.4.3). In molti casi infatti il TTK dispone di uno strumento analogo che svolge le stesse operazioni di un filtro Okapi: odf2xliff, xliff2odf, xliff2po, po2tmx, ts2po, csv2po, ecc…
L'approccio Okapi al problema è più semplice dal punto di vista dell'utente finale perché nonostante a ‘basso’ livello gli strumenti siano molteplici e specializzati, Okapi grazie a Rainbow e a tikal mette a disposizione due interfacce utente uniche e adatte a tutti gli scopi rendendo quindi ‘trasparente’ il formato di partenza. Al contrario il TTK lascia ‘visibile’ la distinzione e diventa difficoltoso ricordare i nomi e le opzioni richieste da tutte le sue numerose utilità per saper utilizzare quella giusta al momento giusto.
Inoltre, come già accennato più volte, tikal (ma è l'infrastruttura sottostante di Okapi a permetterlo) è in grado colmare una apparente lacuna del TTK vale a dire la conversione da PO a TMX, che può essere portata a termine con estrema facilità utilizzando i parametri illustrati sopra.
4.4.3 CheckMate
CheckMate è uno strumento che permette di svolgere operazioni di QA su uno o più documenti, in tutti i formati bilingui supportati da Okapi (PO, TMX, XLIFF, TS, TTX, RTF bilingui, eccetera). Il funzionamento del programma è simile a Rainbow: a ciascuna sessione di lavoro si associano uno o più documenti da elaborare come nelle ‘liste di ingresso’ specificando per ogni file la codifica, la lingua di partenza, la lingua di arrivo e le impostazioni del filtro Okapi per l'estrazione del contenuto. I dati e le impostazioni di sessione possono essere salvati e riaperti in un secondo momento. Per iniziare il controllo è sufficiente fare clic sul pulsante Check All.
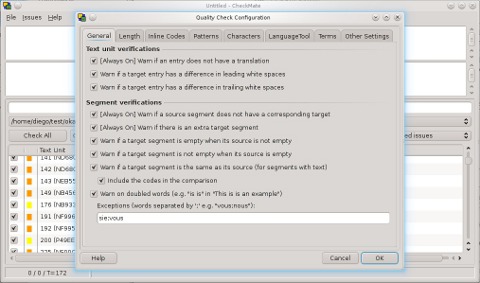
Le numerose opzioni per il controllo qualità messe a disposizione da CheckMate sono suddivisibili nelle seguenti sette categorie:
- controlli che hanno effetto sull'unità di testo191:
- verifica che ogni unità di testo abbia una corrispondente traduzione associata (non che la traduzione sa vuota);
- verifiche sugli spazi all'inizio (leading spaces) e alla fine (trailing spaces) dell'unità di testo della traduzione;
- controlli che hanno effetto a livello di segmento:
- verifica che tutti i segmenti del testo di partenza abbiano una traduzione associata (nel caso di testi non segmentati questo ha lo stesso effetto che il corrispondente controllo sull'unità di testo) ovvero che nel testo di partenza non vi siano segmenti con un identificatore che non esiste nella parte tradotta;
- verifica che tutti i segmenti in lingua d'arrivo siano associati a un relativo segmento di partenza (corrispondenza 1:1);
- verifica che non vi sia un segmento in lingua d'arrivo vuoto per un segmento di partenza non vuoto e viceversa;
- verifica che il segmento di partenza e quello d'arrivo non siano identici quando il primo contiene almeno un carattere di possibili ‘parole’ cioè lettere (\p{Ll}, \p{Lu}, ecc.) o numeri (\p{Nd}) escludendo però selettivamente tutti i tag, placeholder o una qualsiasi sequenza il cui equivalente sia impostato a <same> nella scheda ‘Patterns’ di configurazione del programma;
- ripete il controllo precedente includendo anche i tag e i codici interni al segmento (ad es. la verifica non dà un esito positivo quando il segmento di partenza e quello d'arrivo differiscono solo per i codici, mentre quello precedente sì);
- verifica che nel segmento in lingua d'arrivo non siano presenti parole ripetute (senza distinzione fra maiuscole e minuscole), è possibile inserire anche liste di eccezioni a questa regola inserendo le parole che possono apparire ripetute nel campo di testo sottostante separate da un punto e virgola;
- controlli basati sulla lunghezza della traduzione:
- verifica che la traduzione non sia più lunga di una data percentuale del numero di caratteri dell'originale (senza contare i codici di formattazione interni), in questo caso è possibile inserire un numero di caratteri al di sopra del quale il segmento (originale) viene considerato ‘lungo’ e due valori percentuali per specificare di quanto può eccedere la traduzione rispetto all'originale nel caso di segmenti ‘lunghi’ e nel caso di segmenti ‘corti’;
- verifica che la traduzione non sia più corta di una data percentuale del numero di caratteri dell'originale secondo le modalità descritte per il caso precedente, differenziando ancora fra segmenti ‘lunghi’ (al di sopra della soglia di caratteri specificata) e ‘corti’ con percentuali di tolleranza diverse per le due eventualità;
- controllo sui codici interni ai segmenti:
- verifica che non siano stati alterati i codici di formattazione interni ai segmenti, sia nel numero che nel contenuto ma non nell'ordine degli stessi; è possibile inserire una lista di codici (con distinzione maiuscole/minuscole) che possono essere omessi nella traduzione o di codici che possono apparire ridondanti nella traduzione senza generare positivi;
- Controllo sulle sequenze di caratteri (v. sotto);
- controlli basati sui caratteri:
- verifica l'eventuale presenza di caratteri corrotti, ad esempio se un file con codifica UTF-8 viene aperto erroneamente come ISO-8859-1;
- rileva la presenza di caratteri non inclusi nella codifica specificata nel campo sottostante, permettendo eventualmente i caratteri che corrispondono all'espressione regolare specificata nel secondo campo (anche se non farebbe parte della codifica impostata sopra);
- controllo della terminologia (ancora in fase di sviluppo):
- verifica basata su un glossario, il testo di partenza viene analizzato controllando la presenza di termini, il cui equivalente specificato nel glossario deve essere presente in lingua d'arrivo (positivo se il termine non è riconosciuto nel testo d'arrivo);192
- verifica dei termini come stringhe, cioè ricercando corrispondenze esatte fra la stringa di partenza e la stringa di arrivo in base al glossario (utile quando il termine coincide con il segmento, come nei file di interfaccia grafica).
Come accennato sopra, è possibile inoltre effettuare delle verifiche basate sulle sequenze di caratteri. Questo controllo verifica che le sequenze specificate o nel testo sorgente o nel testo di destinazione (in base a quale dei due deve essere ‘letto’ per primo dal programma) siano modificate o mantenute invariate nella controparte della TU secondo le impostazioni immesse nella sezione ‘Patterns’ della finestra di configurazione.
Queste stesse sequenze influenzano anche il comportamento dei controlli di basati sul segmento perché non saranno generati positivi qualora le uguaglianze fra originale e traduzione rispecchino le regole di questa sezione.
Di ogni sequenza è necessario specificare se è o meno abilitata, il segmento (sorgente o destinazione) che deve essere analizzato e la gravità dell'errore in caso di positivo. Le sequenze sono immesse come espressioni regolari nella colonna (sorgente o destinazione) mentre nella controparte della TU può essere immessa un'espressione regolare (es. riutilizzando parti dell'espressione sorgente del tipo \1, \2) oppure <same> se non devono esserci variazioni. Ad esempio 1 1 [\w\.\-]+@[\w\.\-]+ <same> specifica che gli indirizzi email non devono essere alterati nei segmenti di arrivo rispetto a come appaiono nel testo di partenza e, se ciò accade, viene riportato un errore di gravità media. Ogni regola infine può essere corredata da una breve descrizione. Le liste di sequenze possono anche essere importate ed esportate in formato .txt tab-separated per riutilizzi futuri o in altre sessioni.
Da ultimo, vale la pena di menzionare che le funzionalità e i controlli di CheckMate possono essere estesi tramite il ricorso a un servizio esterno (locale o remoto) come un LanguageTool uno strumento di verifica libero e open source (LGPL) che permette il riconoscimento di errori di stile o di natura grammaticale specifici per lingua.193
I controlli di QA qui descritti non hanno alcun effetto sulle parti di testo che sono marcate (es. in XLIFF) come non traducibili. Invece è possibile impostare che vengano controllati tutti i messaggi, solo quelli approvati oppure solo quelli non approvati. Altre impostazioni accessorie che possono essere personalizzate sono il formato del dettaglio degli errori (HTML) o tab-separated e se questo file deve essere aperto una volta ultimato il controllo. Le configurazioni di tutti i controlli di CheckMate qui descritti possono inoltre essere salvate come file .qccfg ed essere importate in future sessioni.
 |
Il fondamento su cui è basato CheckMate è il ‘Quality Check Step’ di Okapi. In qualità di FE → FE lo si trova implementato in Rainbow dove opera in modalità non interattiva generando il dettaglio degli errori in HTML o TSV. In una sessione di CheckMate, invece, lo step è utilizzato come RD → RD con la possibilità di navigare fra un errore e l'altro (ma non di correggerli direttamente).
Come già visto, inoltre, il programma può essere utilizzato in modalità stand-alone oppure se ne può aprire una sessione dall'interno di Rainbow.
Concludendo, CheckMate rappresenta la soluzione Okapi al problema della QA, lasciato in parte irrisolto dagli strumenti di GNU Gettext e del TTK. Queste ultime due soluzioni (l'ultima in particolare) a dispetto della potenza della flessibilità, rimangono fortemente limitate dal solo formato di entrata PO. Anche i controlli effettuati, validissimi per quanto riguarda i file di risorse utilizzati per la localizzazione delle interfacce del SL, perdono in parte di significato se trasferiti ad ambiti di applicazione più estesi.
CheckMate invece permette di superare questo problema grazie al gran numero di filtri Okapi e si avvicina molto a strumenti disponibili come software non libero gratuiti (es. ApSIC Xbench) o non liberi. Per rendersi conto delle potenzialità del programma è sufficiente dare uno sguardo alla documentazione disponibile online, cui questa trattazione si è ispirata ma di cui una sintesi e una semplificazione sono state purtroppo inevitabili per ragioni di spazio.
4.4.4 Ratel
Ratel è l'editor per le regole di segmentazione dell'infrastruttura Okapi: il suo unico formato di entrata e di uscita sono i file contenenti le regole stesse, nel formato standard SRX. Se utilizzato per la verifica delle regole su casi reali, il programma accetta in ingresso anche documenti in testo semplice da segmentare ed è in grado di generare un resoconto dettagliato in HTML.
Come Rainbow e CheckMate, si tratta anche in questo caso di un programma dotato di interfaccia grafica, realizzata secondo le stesse modalità viste per questi ultimi.
La finestra principale di Ratel, eccezion fatta per la barra dei menu, può essere divisa in due parti: la prima dà accesso alle regole di segmentazione vere e proprie, organizzate secondo lo schema linguistico come previsto dallo standard SRX, mentre la seconda area contiene un testo d'esempio (modificabile a piacere dall'utente) di cui viene mostrata la divisione in segmenti che sarebbe operata applicando le regole presenti nella prima parte della finestra.
L'intero contenuto della sessione di Ratel comprese le opzioni tipiche del programma e l'esempio, che sono extra rispetto allo standard, è salvato nel documento SRX finale e quindi tutte le regole, le impostazioni e le modifiche all'esempio (utili per inserire casi di prova per la propria lingua) non vanno perse alla chiusura del programma e possono essere recuperate in un momento successivo.
Per comprendere il funzionamento di Ratel è indispensabile richiamare alcuni punti chiave dello standard SRX (cfr. appendice A.3). Il primo elemento imprescindibile è che il documento permette di salvare le regole di segmentazione in gruppi, ciascuno associato a uno schema linguistico, più eventuali regole predefinite che hanno applicazione a prescindere da quest'ultimo.
Omettendo volutamente i dettagli del caso quindi, ogni regola appartiene a un gruppo o schema linguistico che è a sua volta associato a un'etichetta identificativa. Alla fine del documento SRX, invece, avviene la ‘mappatura’ delle lingue: tramite una coppia di opportuni attributi, i codici di locale che corrispondono a un'espressione regolare vengono associati alla relativa etichetta, la quale a sua volta rimanda al gruppo di regole definito inizialmente.
Il secondo concetto fondamentale è la formulazione delle regole stesse all'interno degli schemi linguistici, che avviene tramite tre parametri di base: se la regola specificata rappresenti un'interruzione o una non-interruzione, l'espressione regolare che identifica la sequenza prima del punto di applicazione della regola e l'espressione regolare che identifica la sequenza successiva. Le regole hanno effetto in un preciso ordine e questo ne determina la priorità: quelle che compaiono prima nel documento vengono applicate per prime e, in genere, le regole di non-interruzione vengono prima delle regole di interruzione.
La terza idea alla base dell'SRX sono le specifiche introdotte a partire dalla versione 2.0 del formato che hanno lo scopo di rendere univoca l'interpretazione delle regole, ossia la politica di associazione delle lingue ai gruppi di regole, l'assegnazione al segmento precedente o successivo dei tag (di apertura, chiusura o indipendenti) nel caso in cui questi si trovino immediatamente dopo un punto di interruzione e la segmentazione dei subflow incapsulati in un segmento (informazioni che fanno parte dell'intestazione SRX).
La prima parte dell'interfaccia di Ratel permette di avere accesso a tutte e tre queste componenti: il gruppo linguistico, le regole e le informazioni necessarie alla corretta elaborazione del documento.194
La seconda parte dell'interfaccia invece contiene il testo d'esempio e il risultato della segmentazione. Va segnalato che questo testo d'esempio è unico per tutti i gruppi linguistici specificati nella sezione precedente e, in quanto aggiuntivo rispetto allo standard LISA, è presente nel file SRX accanto agli altri elementi di estensione di Ratel che hanno effetto solo all'interno dell'infrastruttura Okapi.
I tre concetti legati allo SRX e illustrati in precedenza hanno inoltre un impatto immediato sulla descrizione e sul funzionamento del programma. Gli schemi linguistici alla base del primo e le regole del secondo permettono di accostare Ratel a OmegaT, il quale ripropone sia la suddivisione delle regole in gruppi, sia l'ordine di priorità (cfr. sez. 3.3.1).
Inoltre, anche i parametri che compongono le regole sono gli stessi: interruzione/non-interruzione (come il lettore ricorderà in OmegaT si preferisce l'espressione ‘eccezione’) e le espressioni regolari che individuano il punto di interruzione o di non-interruzione, che nel contesto di OmegaT prendono il nome di pattern o, nella traduzione italiana del programma, ‘modelli’.
Anche la notazione delle espressioni regolari alla base della seconda idea è la stessa in entrambi i programmi, vale a dire quella per le regexp in Java, che differisce leggermente dalla notazione ICU (International Components for Unicode) adottata invece dallo standard SRX.195
L'unica differenza di comportamento fra OmegaT e Ratel risiede nel terzo concetto illustrato sopra: l'interpretazione dei gruppi e degli schemi linguistici. Nel primo, il codice associato della lingua viene confrontato con tutti i pattern che identificano i gruppi di regole secondo un modello ‘a cascata’.
Si ricorderà, ad esempio, che a un testo la cui lingua è Italiano (Svizzera), associata al codice di locale IT-CH, vengono associate prima le regole generali per l'italiano (perché ‘matcha’ l'espressione IT.*) poi, se presenti, quelle specifiche per l'italiano svizzero (perché ‘matcha’ l'espressione IT-CH) e infine quelle generiche (cfr. 3.3.1).
Nel caso di Ratel questo comportamento può essere ricreato, selezionando fra le opzioni ‘Cascade language map matching’, ma non è quello predefinito. La ragione di una simile scelta è molto semplice: può generare ambiguità e non è in questo modo che i creatori dello standard SRX intendevano venisse utilizzato il formato (cfr. A.3).
Ratel è in grado di aprire e importare sia SRX 1.0 che SRX 2.0 ma è bene fare attenzione a che l'opzione sia selezionata in base allo strumento che ha generato l'SRX visto che non applicare lo stile a cascata o applicarlo dà luogo a risultati diversi.
In ogni caso durante il salvataggio Ratel converte in modo automatico il documento in SRX 2.0, eliminando ogni ambiguità e producendo un file che opera come atteso, sempre che l'opzione sia stata impostata correttamente.
Per il resto, invece, quanto detto relativamente alle regole in OmegaT è valido anche per Ratel. Replicando in quest'ultimo le espressioni utilizzate per il primo, è possibile ottenere file SRX conformi allo standard ed esportabili su ogni piattaforma.
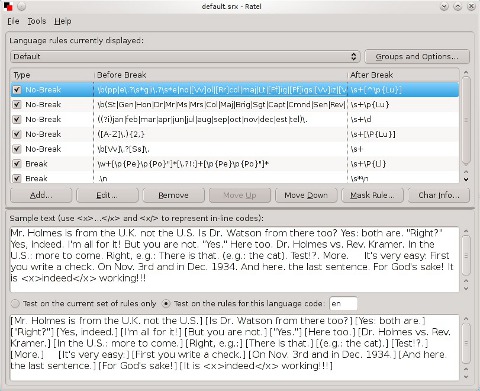 |
Il pulsante ‘Groups and Options’ permette di accedere alle già citate opzioni dello standard SRX, a quelle aggiuntive di Okapi e agli schemi linguistici (che possono essere aggiunti o modificati), ciascuno associato all'espressione che ne consente la mappatura eventualmente corredata da un commento.
Le regole presenti nell'area di testo sottostante possono essere aggiunte o modificate, intervenendo sui tre parametri fondamentali già illustrati, e aggiungendo dei commenti mnemonici utili a ricordarne l'utilità. Le regole possono essere anche eliminate dalla lista e spostate in alto o in basso per determinarne la priorità.
Come nel caso di OmegaT, di cui la sintassi è infatti analoga, non è difficile creare nuove regole o personalizzare quelle esistenti. Ad esempio se una regola crea un'interruzione dopo una sequenza corrispondente a ([A-Z]\.){2,} e prima di \s+\p{Lu} significa che dopo tutti gli acronimi (formati da almeno due lettere maiuscole separate da un punto) verrà creata un'interruzione se sono seguiti da uno o più caratteri di spaziatura e da una lettera maiuscola.
È possibile anche inserire una ‘mask rule’, cioè una speciale espressione regolare le cui sequenze corrispondenti saranno isolate sempre come segmenti a prescindere da tutte le regole precedenti (si tratta di un'estensione non conforme allo SRX). Infine, selezionando un carattere nel campo dell'esempio, è possibile ottenere le informazioni relative cliccando su ‘Char info’, utile se ad esempio se ne vuole determinare la proprietà Unicode (‘character type’) per creare nuove regole.
Se si riceve da un cliente un documento da tradurre corredato da un file SRX per la segmentazione, queste possono essere aperte con Ratel (e modificate all'occorrenza) per poi essere utilizzate all'interno di Rainbow al fine di creare un progetto per OmegaT (utilità di creazione pacchetti di traduzione) o inserite in uno step ‘Text Segmentation’ per i propri scopi. Ecco quindi un altro importante esempio di come una lacuna presente negli strumenti di traduzione liberi possa essere colmata grazie a Okapi.
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/