Il formato TMX
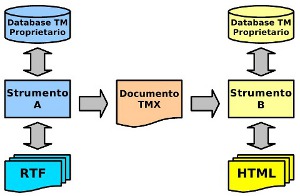
Il TMX è uno standard aperto che permette l'interscambio di memorie di traduzione tra diversi sistemi di traduzione assistita minimizzando o eliminando il rischio di perdita di dati, indipendentemente dallo strumento e dalle caratteristiche dei database ‘proprietari’ utilizzati (figura 49) [Asuni, 2005].
Il suo rilascio iniziale risale al 1998 ma la versione attuale della specifica è la 1.4b del 2005. Il TMX è basato su XML e al suo interno si richiama a vari standard ISO per la definizione della data e dell'ora e dei codici delle lingue e delle nazioni [Savourel, 2005].
Trattandosi di un formato XML-compliant, i file TMX si aprono con una dichiarazione XML (non obbligatoria ma consigliata) contenente informazioni sulla versione di XML utilizzata ed eventualmente la codifica caratteri e come qualsiasi documento XML, anche i TMX possono essere descritti secondo le categorie di ‘validità’ e di well-formedness.
Il TMX è un documento XML ben formato (well-formed). Questo comporta che sia presente uno e un solo elemento ‘radice’ in apertura (nel nostro caso <tmx>…</tmx>) contenente tutti gli altri elementi e cioè che questo sia il primo a essere aperto e l'ultimo a essere chiuso al termine del documento.
Un'altra conseguenza è il fatto che per tutto il documento debba venir rispettato l'ordine di apertura e di chiusura degli elementi, senza omissioni né errori nell'annidamento degli stessi, in modo che per ogni tag di apertura di un elemento contenuto all'interno di un elemento sovraordinato, anche il rispettivo tag di chiusura si trova nel sovraordinato.211
Un'ultima implicazione del vincolo di well-formedness è che nel documento non possono essere presenti caratteri come parentesi angolari e la ‘e commerciale’ se non facenti parte della sintassi di markup o delle entità predefinite.
In quanto documento XML ben formato, un file TMX può essere letto anche se non provvisto della ‘DOCTYPE declaration’, contenente il riferimento alla DTD e, di conseguenza, alle regole sintattiche di markup per la classe di documento quindi senza rispettare necessariamente il vincolo della ‘validità’ che è invece subordinato al rispetto della struttura specificata nella DTD.
A livello strutturale, l'elemento radice (<tmx>) prevede la presenza dell'attributo obbligatorio version (relativo alla versione 1.4b, 1.4a, 1.3, ecc… del formato TMX cui si fa riferimento) e contiene a sua volta due elementi: <header> e <body>.
 |
L'elemento <header> è utilizzato per tutte le informazioni relative al documento, e può contenere al suo interno gli elementi facoltativi <note> (per eventuali commenti), <prop> (es. il dominio della TM) e <ude> (codifica definita dall'utente). Gli attributi obbligatori od opzionali di <header> permettono invece di definire lo strumento e la versione utilizzati per creare la memoria, il tipo di segmentazione adottato, la data di creazione e l'ID dell'utente che ha creato la memoria, ecc…
L'elemento <body> racchiude al suo interno, invece, i dati veri e propri, ovvero la sequenza di unità di traduzione (TU) che costituiscono la TM vera e propria. Ciascuna unità di traduzione è contenuta all'interno di un elemento opzionale <tu>. Non sono previsti altri elementi possibili nel corpo del documento né alcun tipo di attributo per questo elemento.
L'elemento <tu> corrisponde alla singola unità di traduzione. Grazie ad alcuni attributi facoltativi è possibile specificare il tipo di dati, lo strumento di creazione, la data di creazione o di modifica della TU, il formato di TM e la codifica di origine o stabilire alcune specifiche istruzioni per il raggruppamento delle TU attraverso l'attributo tuid.
Gli elementi, invece, che possono essere contenuti in <tu> sono <note> (per i commenti) o <prop> (utilizzabile, ad esempio, per stabilire un ordinamento delle TU) e, chiaramente, almeno un elemento <tuv> o, in genere, almeno una coppia per le varianti della TU nelle diverse lingue (a meno che nella TM non siano presenti stringhe orfane).
L'elemento <tuv> è utilizzato per contenere i singoli segmenti e richiede la presenza dell'attributo lang relativo alla lingua del segmento che segue, espressa come locale nel formato IT-IT, EN-US, ecc…212 Altri attributi facoltativi dell'elemento <tuv> consentono di specificare lo strumento e la data di creazione o di modifica della variante nonché, ancora una volta, la codifica.
Gli elementi opzionali che possono essere contenuti in <tuv> sono <prop> e <note> (v. sopra) mentre deve essere presente uno e un solo elemento <seg> che ha la funzione di contenere il testo vero e proprio del segmento. Rappresenta l'ultimo degli elementi strutturali del TMX. Non può avere nessun attributo e contiene elementi testuali (testo, spazi tranne che all'inizio o alla fine della stringa, caratteri di fine riga) ed eventualmente uno o più elementi in linea.
Accanto a quelli strutturali, vale a dire gli elementi che costituiscono il ‘contenitore’ per la parte testuale, nei documenti TMX possono comparire anche elementi in linea cioè che non interrompono il flusso di testo, compaiono esclusivamente racchiusi all'interno di elementi <seg> e possono presentarsi in qualsiasi ordine.213 Gli elementi in linea consentono di specificare il markup del contenuto dei segmenti, rendendo possibile in tal modo generare il documento d'arrivo con lo stesso formato di quello di partenza anche disponendo della sola TM.
Gli elementi hanno la funzione di racchiudere al proprio interno i tag e cioè le specifiche della formattazione del testo di partenza. Considerando il problema nell'ottica della traduzione assistita possono presentarsi tre casi:
- istruzioni di formattazione (grassetto, corsivo, ecc…) limitate a parole singole o che, in ogni caso, iniziano e finiscono all'interno dello stesso segmento (frase o paragrafo);
- istruzioni di formattazione i cui elementi di apertura e di chiusura, però, non appartengono allo stesso segmento;
- codici che corrispondono a funzioni isolate, che non hanno un elemento di chiusura esplicitato nel documento (come accade con le immagini, ad esempio).
Gli elementi in linea utilizzati nel TMX saranno quindi: <bpt> (begin paired tag) e <ept> (end paired tag) per il primo caso, <it> (isolated tag) per il secondo caso e <ph> (placeholder) per il terzo caso. L'elemento <ut> (unknown tag) era usato per i tag non riconosciuti dallo strumento CAT ma è attualmente deprecato e se ne consiglia la sostituzione con <ph>.
Gli elementi <hi> e <sub>, pur essendo in linea, non racchiudono i tag di formattazione del documento originale ma testo (che deve essere quindi tradotto) e rappresentano, rispettivamente le parti evidenziate (highlight), ad esempio unità terminologiche, nomi propri, termini che non devono essere modificati (da un'eventuale traduzione automatica) e porzioni di testo incapsulate (subflow), come l'attributo title dei collegamenti ipertestuali nell'HTML o le note a piè di pagina, che fanno parte della TU solo per motivi di segmentazione.
Il grande vantaggio dovuto alla presenza degli elementi in linea è di permettere agli strumenti CAT di trattare, con l'eccezione di <hi> e <sub>, il testo in essi contenuto, e cioè i tag o gli elementi di controllo del testo di partenza (ad es.<f0> e cioè <f0>) in maniera diversa rispetto al resto del testo.
È possibile, ad esempio, ignorare i caratteri in essi contenuti (per evitare di abbassare il livello di match quando i tag rappresentano l'unica differenza) o considerarli come un'unica entità in modo da segnalare il fuzzy match tenendo conto che però sono solo i tag a essere diversi.
Non tutti gli strumenti CAT si comportano comunque, allo stesso modo riguardo le etichette di formattazione presenti nei segmenti. Per garantire il massimo dell'interoperabilità il formato TMX offre due diversi livelli di implementazione, chiamati rispettivamente Livello 1 e Livello 2: nel primo caso, le memorie contengono solo il testo semplice, lasciando che sia il traduttore a occuparsi, in caso di leverage di reinserire i tag correttamente, nel secondo invece la memoria permette di esportare e importare sia il contenente che il contenuto, rendendo possibile l'ottimizzazione cui accennato sopra.
|
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/