4.2 Gestione della terminologia
4.2.1 ForeignDesk TermBase
| Autore: | L10N Bridge Technologies Inc. |
| Licenza: | IBM Public License |
| Pagina web: | http://www.foreigndesk.net |
| Versione: | 6.0.1 (novembre 2001) |
Un'interessante applicazione per la gestione della terminologia è contenuta nell'ITE (Integrated Translation Environment) ForeignDesk prodotto da L10NBridge principalmente ad uso dei propri collaboratori interni per la gestione delle traduzioni e in seguito rilasciato sotto licenza libera nel 2001. In particolare la componente di interesse per questo lavoro è TermBase, il programma per la creazione e consultazione di TB.
TermBase è rilasciato sotto forma di codice sorgente (C++) e in formato binario, in entrambi i casi per Windows. Il suo utilizzo in ambiente GNU/Linux è possibile in maniera molto semplice attraverso progetti come Wine,159 un'applicazione che ne rende possibile l'esecuzione ricreando l'ambiente Win32 attraverso una reimplementazione libera delle librerie condivise (DLL) di Windows. Il modo più semplice per procurarsi il programma è quindi scaricare il file binario, eseguirlo tramite Wine e quindi seguire la procedura guidata di installazione.
La prima operazione da svolgere alla creazione di un nuovo TB è definire la lingua o le lingue di lavoro. Il programma permette infatti di avere indifferentemente TB mono- e plurilingui a seconda delle proprie esigenze. In ogni caso la decisione iniziale non è vincolante dal momento che è possibile aggiungere una lingua in qualsiasi momento dal menu Tools/Languages, scegliendo una nuova lingua fra quelle proposte nell'elenco o, se non presente, una personalizzata.
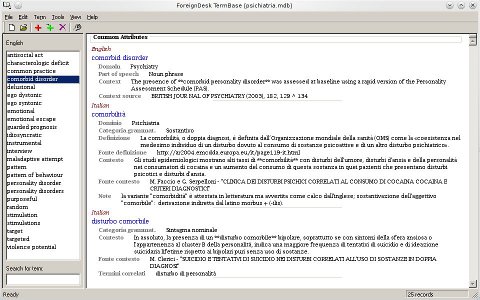 |
In seguito è necessario definire gli attributi che saranno utilizzati all'interno delle schede terminologiche (d'ora in avanti record) del TB. Tali attributi possono essere di due tipi: testo (libero) oppure lista a scelta multipla (picklist). Il tipo di attributo deve essere selezionato al momento della creazione e, nel caso in cui si trattasse di una lista, nella finestra di dialogo per la definizione degli attributi devono esserne specificate le componenti.
Se gli attributi si applicano a livello di termine, è possibile indifferentemente avere le etichette degli attributi in una sola lingua o duplicarle per ciascuna delle lingue di lavoro. Va sottolineato che la scelta del numero, delle etichette e del tipo di attributi (nonché delle componenti interne alle liste) non è definitiva e può essere alterata durante le fasi di redazione successive. Gli attributi possono essere infatti cancellati o ne possono essere aggiunti di nuovi mentre all'interno delle liste è possibile aggiungere, modificare oppure eliminare le voci.
Inoltre il modello così definito può essere riutilizzato con facilità per la compilazione di TB successivi attraverso il menu File/CreateTemplate, in maniera simile a quanto avviene con i più noti programmi di gestione della terminologia proprietari esportando la definizione del modello di struttura del TB.
Una volta definiti le lingue e gli attributi è possibile procedere con la compilazione del TB. I singoli record hanno una struttura fortemente gerarchica che può essere meglio compresa nei termini del metamodello TMF presentato nella sezione A.2 (fig. 51).
Il record corrisponde al livello TE (Terminological Entry), al di sotto del quale si trova la sezione delle lingue LS (Language Section) che contiene al proprio interno i vari termini ed eventualmente i sinonimi in ciascuna lingua, cioè TS (Term Section) ognuno con i propri attributi locali.
È possibile creare un nuovo record dal menu Term/New Record oppure semplicemente premendo il tasto Ins. Nella finestra di dialogo devono essere specificati la lingua del termine da inserire ed eventualmente una serie di attributi di partenza.
La creazione degli attributi in ogni caso è più comoda dalla schermata principale del programma, facendo clic con il tasto destro del mouse sul termine della scheda e selezionando New Term Attribute oppure facendo clic sulla sezione Common Attributes in alto e selezionando New Common Attribute per inserire un attributo comune (vd. poi).
In modo simile, l'inserimento di nuovi termini da affiancare al termine vedette oppure equivalenti in altre lingue può essere effettuato dal menu Term/New Term o con la combinazione di tasti Maiusc+Ins. Gli attributi specifici per i nuovi termini sono inseriti in modo analogo a quanto appena detto per il primo termine del record.
Per comprendere appieno la procedura di creazione di un nuovo record è necessario tenere in considerazione la distinzione fra le due macrocategorie disponibili: gli attributi comuni, riferiti a tutti i termini del record che quindi si applicano al di sopra del livello della lingua, e gli attributi locali, specifici per ciascun termine.
Dopo aver creato un record è possibile inserire per prima cosa gli attributi comuni (i campi dominiali o la definizione, ad esempio, qualora si scelga di averli in una sola lingua, oppure ancora il cliente) e in seguito gli attributi specifici di tutti i termini presenti.
Per facilitare la creazione delle schede, il programma offre anche la possibilità di creare degli input model contenenti una lista di valori predefiniti per gli attributi comuni che si prevede di utilizzare in tutti i record. Va sottolineato che gli input model (se ne può usare più d'uno) possono comprendere solo attributi comuni e possono essere salvati, riutilizzati e combinati fra loro. Inoltre all'utente è lasciata aperta la possibilità di abilitare o disabilitare un input model a seconda delle esigenze e delle circostanze.
Nel caso purtroppo frequente — specie all'inizio di un nuovo lavoro di documentazione — in cui ci si accorgesse di errori od omissioni nella definizione della struttura del record, questa può essere modificata anche in corso d'opera. Come detto in precedenza, è possibile integrare attributi mancanti e liste a cascata incomplete oppure eliminare determinati attributi e sostituirli con altri intervenendo sul modello di struttura. I nuovi attributi possono essere in seguito inseriti nelle schede come quelli di partenza, permettendo così una grande flessibilità e comportando una minima perdita di lavoro svolto (solo i dati inseriti nei campi modificati) nel caso in cui fosse necessario ritornare sui propri passi e modificare la configurazione delle schede.
Le componenti delle liste a cascata possono anche essere modificate, piuttosto che eliminate e ricreate; per gli attributi invece la sola modifica non è possibile e quindi si rende necessario cancellare l'attributo e ricrearlo. Parimenti, non è possibile trasformare il tipo di un attributo da testo libero a lista, ferma restando la possibilità di cancellarlo e di crearne in seguito uno di nuovo con le caratteristiche volute. Se anche l'attributo avrà lo stesso nome, le informazioni inserite andranno comunque perse e occorrerà rifare quella parte della scheda. Ciononostante questo è molto più economico che ripartire da zero con tutte le schede.160
Il contenuto dei campi degli attributi, così come del campo termine, può essere modificato facendo doppio clic sul punto interessato. Nel caso dei termini e degli attributi di testo, apparirà un campo di modifica all'interno della finestra principale dell'applicazione o, nel caso delle liste, comparirà l'elenco a cascata delle scelte disponibili immediatamente sotto il cursore e sarà possibile operare la modifica. Inoltre, gli attributi possono anche essere raggruppati per facilitarne la manipolazione (ad es. la cancellazione).
In TermBase è anche molto semplice aggiungere una nuova lingua al TB, funzionalità utile se la risorsa viene reimpiegata in progetti diversi o utilizzata da più collaboratori. È sufficiente selezionare la lingua dal menu Tools/Languages e in seguito aggiungere i nuovi termini dal menu Term/New Term specificando la nuova lingua.
Anche le etichette degli attributi nella nuova lingua (qualora si decidesse di avere etichette dei campi e le voci delle liste a cascata specifiche per lingua) possono essere aggiunte alla definizione della struttura senza perdere alcunché del lavoro svolto in precedenza. Va ricordato ancora una volta che sempre grazie alla funzione New Term è possibile inserire un numero arbitrario di sinonimi (al livello TS) per ciascuna lingua.
Un'altra interessante caratteristica di TermBase è la possibilità di effettuare delle ricerche nel TB, nelle quali è consentito anche l'utilizzo dell'asterisco come carattere jolly. A scapito della praticità di consultazione, purtroppo, la ricerca ha effetto solo sulla lista dei termini in lingua di partenza ragion per cui, volendo considerare le voci in lingua d'arrivo (compresi i sinonimi che afferiscono a uno stesso record), l'unica possibilità è invertire la direzione linguistica attraverso il menu Tools/Languages. Non è invece possibile cercare all'interno del contenuto dei campi degli attributi (quella che in alcuni programmi viene chiamata ‘full text search’).
È possibile inoltre accedere in automatico a informazioni riepilogative sulla natura del TB dal menu Tools/Statistics: così facendo verrà visualizzato il numero di record totali e l'elenco delle lingue dei vari termini.
Una funzionalità non presente è, invece, la possibilità di creare all'interno dei campi degli attributi collegamenti, né riferimenti interni al TB né collegamenti a risorse esterne, ma resta tuttavia possibile l'inserimento di indirizzi in formato URL all'interno degli attributi. Qualora si scegliesse di esportare per la consultazione il TB in formato HTML, nulla vieta inserire ‘a mano’ i collegamenti ipertestuali intervenendo direttamente sul sorgente HTML.
TermBase opera in maniera predefinita su database .mdb, cioè il formato utilizzato nativamente da MS Access XP (e versioni precedenti) nonché da SDL-Trados MultiTerm. In realtà i dati possono essere importati ed esportati anche nel formato TSV, il che rende molto facile lo scambio di dati con la maggior parte dei programmi,161 funzionalità particolarmente utile per convertire i glossari redatti sotto forma di tabella o di foglio di calcolo. Le banche dati terminologiche possono essere anche acquisite e trasformate in formato di testo semplice per l'utilizzo con le vecchie versioni di MultiTerm. Infine va segnalato che l'esportazione è possibile anche in formato HTML, per la presentazione e per rendere i dati di immediata consultazione su qualsiasi piattaforma, indipendentemente dal software installato.
L'esportazione dei dati può anche essere diretta verso un nuovo TB con la possibilità di impostare un filtro basato sulle lingue contenute nei record, sui valori dei singoli attributi comuni e degli attributi specifici per termine (più condizioni possono essere combinate con operatori logici booleani).
L'importazione diretta da un altro file .mdb non è invece consentita: per unire due TB si rende obbligatorio un passaggio intermedio attraverso un documento TSV. La procedura di importazione è però molto avanzata e permette di minimizzare la perdita dei dati (assegnando un valore di lingua/attributo per ciascuna colonna) ed è possibile impostare la politica di sostituzione/fusione dei record qualora vi fossero dei duplicati oppure, in alternativa, scegliere se sovrascrivere l'intero TB.
Nonostante la mancanza di aggiornamenti negli ultimi anni, TermBase è uno strumento abbastanza valido per la gestione della terminologia. L'interfaccia utente, caratterizzata dall'estrema razionalità e localizzata in inglese, permette un facile accesso a tutte le funzionalità di base. Inoltre, il programma è corredato da un'esaustiva guida in linea accessibile dal menu di aiuto (anch'essa in inglese) suddivisa per argomenti e di facile consultazione.
Le procedure guidate di importazione, esportazione e creazione dei filtri sono ben curate e guidano l'utente passo passo nei compiti che potenzialmente potrebbero presentarsi problematici. Inoltre, la possibilità di esportare in diversi formati fra cui l'HTML rende i database altamente portabili.
La creazione dei nuovi record è inoltre ottimizzata e resa più semplice grazie alla possibilità di creare attributi comuni e di creare degli input model che risparmiano all'utente le operazioni più ripetitive permettendo di focalizzare l'attenzione solo sugli attributi realmente importanti. Va sottolineata, infine, la possibilità di effettuare degli aggiustamenti in corso d'opera della definizione di struttura dei record e delle lingue, caratteristica che minimizza il lavoro da rifare in caso di correzione e non impone al traduttore il fardello di riprendere il lavoro ex novo o di percorrere strade rischiose come l'esportazione e l'importazione di TB con un modello di definizione diverso.
Il difetto, se può essere definito tale, che può porre seri limiti all'utilizzo del programma è la sua sempre più evidente obsolescenza. TermBase è stato rilasciato sotto licenza libera nel 2001 e la versione beta del rilascio previsto per il 2002 purtroppo non è mai giunta allo stato stabile. Una delle funzionalità più interessanti dell'applicazione, la compatibilità con le banche dati terminologiche create con strumenti di traduzione assistita proprietari di maggior diffusione, permette di importare file prodotti solo da TRADOS Multiterm 5 perché la definizione degli attributi per l'esportazione (cioè il file .mdx) fornita assieme a ForeignDesk per garantire la compatibilità è inutilizzabile con le versioni successive della nota suite.
4.2.2 Translate Toolkit per la terminologia
Come già anticipato nella sezione 2.4.3, esistono alcuni strumenti all'interno del TTK sviluppati per facilitare il lavoro dei responsabili della terminologia all'interno dei progetti di localizzazione. I programmi più interessanti a questo riguardo sono due: poterminology, grazie al quale è possibile estrarre terminologia mono- e bilingue da file PO tradotti e csv2tbx, un convertitore in grado di produrre risorse nel formato standard TBX a partire da documenti comma-separated values.
Poterminology
Il programma è uno script Python in grado di estrarre terminologia producendo particolari file PO implementabili all'interno di piattaforme di traduzione assistita online basate su PO (es. Pootle). Se un gruppo di localizzazione si avvale di Pootle è infatti possibile caricare sia risorse terminologiche globali, che si applicano a tutti i progetti di una determinata lingua, sia TB di progetto inserendo gli opportuni file PO nella directory del progetto.
Lo script accetta in ingresso uno o più file PO bilingui con la stessa combinazione linguistica oppure POT (monolingui, con la stessa lingua di partenza) ed è eventualmente in grado di operare anche su un'intera directory.
Il risultato dell'estrazione terminologica sarà tanto più valido quanto più numerosi saranno i file in ingresso, tuttavia poterminology può essere utilizzato anche su singoli file.
Accanto ai file (o directory) di ingresso e il nome del glossario di uscita, il programma accetta una serie di parametri di ottimizzazione dell'estrazione terminologica che garantiscono un ampio margine di flessibilità.162 Ad esempio, con l'opzione -stopword-list="file" è possibile caricare una lista di esclusione (file) personalizzata contenente le espressioni che andranno escluse dalla ricerca dei termini. L'opzione -accelerator="acceleratori" specifica i caratteri utilizzati come acceleratori (cfr. 2.4.2) nello stile del progetto perché vengano ignorati ai fini dell'estrazione. Con -sort, invece, è possibile disporre i termini del glossario in un particolare ordine (in base alla frequenza, alfabeticamente o a seconda della lunghezza).
L'opzione -update="file" permette invece di aggiornare un glossario (file) con i PO provenienti da nuove traduzioni o creati da un altro progetto di localizzazione in modo da mantenere la coerenza a livello di risparmiare lavoro agli addetti alla terminologia. Va inoltre segnalato che la direzione linguistica del glossario può essere invertita rispetto a quella dei PO di partenza ricorrendo all'opzione -invert.
Per quanto riguarda la selezione dei termini sono disponibili invece dei parametri di ‘soglia’ che permettono di specificare ulteriori criteri oltre alla lista di esclusione. Un aspetto fondamentale è rappresentato dall'opzione -term-words, che permette di impostare il numero massimo di parole di cui dovranno essere composti termini. Impostare a 1 il valore di questo parametro, il cui valore implicito è invece 3, ha da un lato lo svantaggio di ridurre la ricerca solo a espressioni di una sola parola ma, d'altra parte, è molto utile per ridurre il tempo di esecuzione se si lavora con directory di grandi dimensioni.
Oltre alla lunghezza, esistono altre quattro opzioni che permettono di impostare ulteriori restrizioni di selezione in base al numero di occorrenze. Il criterio più ‘grezzo’ è costituito da -inputs-needed="minimo", che causa l'esclusione dei termini che appaiono in un numero inferiore a minimo di file diversi (in genere pari a 2 se si usa un numero di file in ingresso maggiore di uno).
Per avere maggior controllo sui messaggi costituiti da un solo termine, che potrebbero essere selezionati come termine ma non avere alcuna rilevanza, è disponibile l'opzione fullmsg-needed="minimo" grazie alla quale è possibile escludere i termini che compaiono un numero inferiore a minimo di volte. Similmente, per i termini che compaiono solo come sottostringa di un messaggio ma non come unico elemento di un messaggio, è possibile ricorrere a -substr-needed="minimo". Da ultimo possono essere utili anche l'opzione -locs-needed="minimo", per escludere i termini ricorrenti in un numero inferiore a minimo di posizioni diverse del codice sorgente originale (contenuto nei riferimenti al sorgente del PO).
I termini estratti da poterminology andranno a costituire un file PO contenente come messaggio in lingua di partenza il termine estratto e, se possibile, la relativa traduzione come messaggio in lingua d'arrivo. Le traduzioni infatti vengono estratte solo per i termini la cui dimensione coincide con quella di un intero messaggio, in caso contrario lo script non ha a disposizione alcun sistema per identificare la sottostringa contenente il termine equivalente in lingua d'arrivo.
Qualora fossero presenti più traduzioni diverse per uno stesso termine nei file di partenza, la voce terminologica sarà marcata con il flag fuzzy e in lingua d'arrivo compariranno tutte le alternative separate da un punto e virgola, accompagnate dal nome del file in cui ricorre.
L'estrazione dei termini è basata sulla frequenza degli stessi nei file PO/POT di partenza considerati senza ripetizioni, secondo i valori di soglia predefiniti o impostati dall'utente. I messaggi plurali non vengono considerati, così come gli specificatori di formato, i tag degli elementi e le entità (X)HTML nonché le indicazioni di inclusione o esclusione di termini semplici o composti contenute nella stoplist predefinita.163
Infine un ultimo criterio non trascurabile in base al quale i termini sono selezionati è la l'indipendenza delle sottostringhe, di fondamentale importanza quando si lavora con espressioni composte e complesse che vanno oltre i confini della singola parola. Può accadere infatti che, dove il limite -term-words sia impostato a 3 (valore predefinito), un'espressione composta da due parole possa superare la selezione basata sulle liste di esclusione e sulla soglia di frequenza ma sia presente sempre in co-occorrenza con lo stesso terzo elemento. In questo caso l'ultimo test di poterminology permette di ‘filtrare’ l'espressione selezionando solo la serie di tre parole come termine. Lo stesso principio si applica a dimensioni di cluster più elevate, sempre in favore dell'espressione più lunga ed eliminando quella più corta.
Concludendo, lo script è semplice ma al tempo stesso molto potente. I valori di soglia e la lista di esclusione predefiniti sono un buon punto di partenza per l'utilizzo di base del programma mentre l'ottima e abbondante documentazione disponibile sulle pagine web dedicate al TTK rende assai facile la creazione di regole personalizzate anche ai meno esperti.
Tra i difetti non è possibile non segnalare le limitazioni nell'estrazione della terminologia bilingue. Il programma non implementa infatti alcun sistema di riconoscimento dei possibili equivalenti in lingua d'arrivo quando il termine estratto sia di dimensione inferiore quella dell'intero messaggio. In tal caso, sebbene le traduzioni siano presenti nel file PO di partenza, si richiede l'intervento manuale dell'utente per compilare i campi rimasti vuoti.
Un'altra considerazione negativa è l'applicabilità limitata dello script a contesti in cui si lavora con il formato PO. Se da un lato tale problema può essere aggirato per i file bilingui (come detto in precedenza i formati XLIFF e TMX possono essere convertiti in PO in modo relativamente semplice), il PO di terminologia generato da poterminology rimane una risorsa terminologica in formato non standard che per essere utilizzata deve essere convertita in TBX, in tab-separated o comma-separated.164 Ciononostante, poterminology rimane uno strumento molto utile rappresenta una buona base di partenza per la creazione di risorse terminologiche più elaborate.
Csv2tbx
Si tratta anche in questo caso di uno script Python eseguibile esclusivamente da riga di comando che permette di convertire glossari in formato CSV nel formato TBX standardizzato dalla LISA. Trattandosi di uno strumento del TTK, anche in questo caso sulle pagine web del progetto è disponibile la relativa documentazione.
L'utilità di un simile strumento è che permette di utilizzare con gli strumenti di traduzione assistita glossari prodotti con un qualsiasi foglio di calcolo, editor di testo o anche provenienti da workflow PO (es. poterminology → po2csv).
Il programma accetta in ingresso uno o più file in formato .csv e produce .tbx. Fra le opzioni più interessanti va segnalata la possibilità di specificare la codifica caratteri dei documenti in ingresso e, sempre in riferimento a questi file, la possibilità di assegnare un valore alle ‘colonne’ del documento CSV. Si assume implicitamente che queste ultime siano tre (lingua di partenza, lingua d'arrivo, commenti) oppure due, e tramite l'opzione -columnorder è possibile impostarne l'ordine per garantire la corretta trasposizione nel TB.
L'utilizzo dello script è molto facile, tuttavia sono necessari alcuni accorgimenti. In primo luogo non è possibile impostare la direzione linguistica: il programma dà per scontato che la lingua di partenza sia l'inglese, come in effetti avviene nella quasi totalità dei progetti di localizzazione, mentre la lingua d'arrivo non viene impostata rendendo necessario intervenire ‘a mano’ sul TBX.
Inoltre la struttura del TB generato dal programma è molto elementare e l'eventuale colonna dei commenti non viene presa in considerazione, per cui vengono preservati solo il primi tre livelli del modello per la rappresentazione della terminologia.
Partendo da un semplice file CSV anche la gestione dei sinonimi non è facilmente implementabile. L'unica possibilità di evitare doppioni è intervenire direttamente sul file TBX generato e inserire un secondo termine all'interno del livello LS (Language Set).
4.2.3 Considerazioni finali
Gli strumenti trattati in questa sezione sono utili per la gestione, la manipolazione e la creazione, anche automatizzata di risorse terminologiche. In particolare, le utilità del TTK qui presentate sono in parte sovrapponibili al livello 203 della classificazione di Melby, in quanto consentono l'estrazione terminologica e la creazione di un database a partire da materiale segmentato o allineato. TermBase di ForeignDesk, invece, permette la creazione manuale di risorse terminologiche per la consultazione.
La gestione della terminologia, riprendendo considerazioni simili a quelle fatte per gli allineatori, è purtroppo uno dei punti più ‘dolenti‘ per il traduttore che intenda avvalersi di SL. In vista di una soluzione ottimale, le funzionalità viste finora andrebbero come minimo integrate in un unico strumento, dal momento che nessuno può essere considerato completo.
TermBase dovrebbe integrare le procedure di estrazione automatica di poterminology e la possibilità di importare ed esportare in un formato compatibile con gli altri strumenti qui analizzati mentre gli strumenti del TTK dovrebbero prevedere anche la consultazione e le funzionalità di modifica interattiva tipiche di TermBase.
Purtroppo, dati i diversi formati su cui operano, è molto difficile usare anche gli strumenti in sequenza se non in casi particolari in cui la struttura dei record sia molto elementare (ad es. convertendo in CSV un PO termine-termine ottenuto con poterminology, trasformando quest'ultimo in un tab-separated e importandolo in TermBase).
Dopo aver strutturato il database con lo strumento di ForeignDesk, tuttavia, si ottiene una risorsa sufficientemente completa, con record strutturati simili a quelli delle soluzioni proprietarie, ma accessibile in sola consultazione e inutilizzabile con la gran parte degli strumenti CAT esaminati nella sezione 3.3.165
Una soluzione seppur molto parziale a quest'ultimo problema, evitando il ricordo a TermBase è consiste nell'impiegare editor XML esterni alcuni dei quali, oltre ai ‘classici’ editor di testo disponibili in ambito GNU/Linux, permettono di leggere DTD caricate dall'utente, visualizzare la struttura ad albero degli elementi del documento, modificarne in maniera selettiva contenuti testuali e gli attributi. Un interessante programma di questo tipo, molto indicato anche per cui non ha nessuna esperienza con l'XML è senza dubbio Serna di Syntext,166 disponibile sia in versione commerciale che open source e installabile molto facilmente attraverso il gestore di pacchetti di molte distribuzioni.
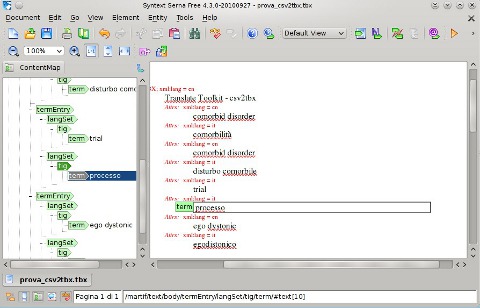 |
Una volta aperto un file TBX, com'è possibile osservare in figura 42, l'interfaccia del programma ricorda molto da vicino quella sia quella di TermBase che quella dei più diffusi applicativi proprietari per la creazione di database terminologici. Tuttavia, Serna non permette una vera e propria consultazione ma solo la creazione o la modifica del documento e, non essendo pensato per interagire con risorse di terminologia, non permette le funzionalità di base di ricerca, filtro, importazione ed esportazione di record.
Inoltre, non essendo presente alcuna ottimizzazione per la gestione dei database terminologici, gli interventi dell'utente richiedono comunque una conoscenza piuttosto approfondita della struttura specifica del TBX sia per l'aggiunta di nuovi record che per la definizione dei campi e dei possibili valori che possono assumere. A causa di queste forti limitazioni, non è stato ritenuto opportuno riservare uno spazio dedicato a soluzioni di questo tipo nella presente sezione.
Invece, per quanto fortemente incomplete, TermBase e poterminology rappresentano per il momento le uniche alternative disponibili nell'ambito del SL e perciò si è ritenuto necessario segnalarne comunque l'importanza. Essendo soprattutto la seconda rivolta più ai coordinatori e ai terminologi dei progetti di localizzazione che ai singoli traduttori, è pur vero che le carenze hanno impatto minore su questi ultimi.
Da questo punto di vista la situazione non è però molto dissimile per il software proprietario, dal momento che in genere gli strumenti per la gestione della terminologia sono comunque pensati più per terminologi e project manager che per i singoli traduttori al punto che gli strumenti più avanzati (es. estrazione terminologica) sono venduti con licenze a parte rispetto al pacchetto freelance.
Infine, si ricorda che accanto a agli strumenti trattati in questa sezione esistono anche applicazioni sviluppate come applicazioni CAT/TM (cfr. 3.3) e quindi per scopi più generici ma che permettono anche di creare e modificare banche dati terminologiche più o meno sofisticate in formato TBX.
La maggior parte di questi programmi, tuttavia, integra funzionalità di sola lettura o di scrittura molto limitata, ad esempio consentendo la creazione di nuove voci terminologiche ma non la modifica di quelle esistenti e solo come equivalenze esatte in formato ‘termine-termine’.
L'unica eccezione degna di nota è, a questo riguardo, Lokalize, che comprende sia la possibilità di inserire informazioni a un livello superiore rispetto a quello della lingua (es. campi dominiali) sia una comoda interfaccia grafica di amministrazione e modifica di tutto il glossario.
Da ultimo, va segnalato che ulteriori possibilità per la creazione, ancora una volta automatizzata, di database terminologici simili a poterminology saranno considerate a proposito dell'infrastruttura Okapi, in particolare nella sez. 4.4.1. Il vantaggio di questa soluzione è la possibilità di accettare in ingresso formati diversi dal PO e di produrre direttamente un risultato in TBX.
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/