4.1 Consultazione di corpora
4.1.1 TextSTAT
| Autore: | Matthias Hüning |
| LicenzA: | Licenza MIT |
| Pagina web: | http://neon.niederlandistik.fu-berlin.de/en/textstat/ |
| Versione: | 2.8 (dicembre 2009) |
TextSTAT (Simple Text Analysis Tool) nasce nel 2000 all'interno del dipartimento di Filologia Nederlandese della Freie Universität di Berlino con l'intento di creare uno strumento di facile utilizzo per la consultazione e l'interrogazione di corpora. L'applicazione è realizzata nel linguaggio di programmazione Python, pertanto richiede come unico prerequisito per essere eseguita sul proprio sistema che vi sia installata e funzionante una distribuzione Python (in genere già presente in maniera predefinita in tutte le maggiori distribuzioni GNU/Linux).
Essendo Python un linguaggio interpretato, non è necessaria alcuna compilazione per eseguire il programma, che può essere avviato semplicemente con un comando come python TextSTAT.pyw una volta all'interno della directory dei sorgenti. TextSTAT è dotato di un'interfaccia grafica molto intuitiva e di facile utilizzo, localizzata nelle principali lingue europee (ma non in italiano) e realizzata grazie al toolkit grafico TKinter, lo standard de facto per numerose applicazioni Python.
Il programma consente la creazione in modalità interattiva di corpora monolingui che possono essere creati a partire da tre fonti: file di testo salvati sul sistema locale, documenti presenti in remoto e recuperati mediante un web spider da un determinato dominio e, infine, interventi presenti in un newsgroup. I formati di documenti supportati sono quelli più diffusi nell'ambito della produttività individuale (.doc, .docx, .odt, .sxw) e di testo semplice (.txt) o HTML nel primo caso; tutti i documenti che corrispondono al tipo MIME di testo (eccetto text/javascript) nel secondo caso; testo semplice nel terzo. Prima dell'importazione, inoltre, può essere necessario selezionare la codifica utilizzata per i testi: come scelta predefinita il programma utilizza la ISO-8859-1 (o ‘Latin 1’).
Purtroppo, lavorando con documenti tanto locali quanto remoti, va segnalato che manca il supporto al formato PDF, ormai sempre più diffuso online grazie alla sua elevata portabilità. Tuttavia, in ambiente GNU/Linux questa apparente lacuna può essere superata con l'utilità da riga di comando pdftotext (in Debian inserita all'interno del pacchetto poppler-utils) che è in grado di convertire in testo semplice la maggior parte file PDF basati su testo (fatto salvo il caso di sistemi di protezione basati su password) pdftotext -enc Latin1 <file pdf> <file di testo>. Il problema persiste invece nel caso di PDF basati su immagine, per i quali diventa obbligatorio il ricorso ad applicazioni OCR.149
Una delle funzionalità più interessanti, nonché uno dei maggiori punti di forza di TextSTAT rispetto ad alternative commerciali o freeware anche molto diffuse (come AntConc), è la possibilità di importare documenti direttamente dal web attraverso lo spider integrato. Attraverso questo strumento, infatti, possono essere analizzate le pagine afferenti al dominio specificato nell'URL immesso dall'utente (oppure solo una parte di esso), seguendo i collegamenti ipertestuali presenti nel sito e scaricandone i contenuti di natura testuale fino al raggiungimento del numero di pagine specificato nella finestra di importazione.
Una volta caricati i documenti, il corpus può essere salvato come progetto, in modo da permetterne la riapertura in un secondo momento e l'eventuale modifica con l'aggiunta o la rimozione di determinati testi. In questo secondo caso, verrà prodotto un file in formato .crp contenente l'intera selezione di testi e accessibile anche qualora i documenti originali dovessero essere cancellati o spostati o, nel caso in cui si fosse trattato di pagine web remote, anche in modalità non in linea.
La consultazione del corpus, invece, avviene attraverso le quattro schede dell'interfaccia principale (figura 39). In primo luogo, è possibile visualizzare l'elenco dei file che costituiscono il corpus per eliminarne alcuni elementi o aprire i file in un browser/editor esterno per visualizzarli o modificarli, a condizione che il relativo URL sia accessibile.
In secondo luogo, è possibile creare una wordlist a partire dai file del corpus, visualizzando ciascuna occorrenza singola (type) accompagnata dalla relativa frequenza (numero di token dello stesso tipo). I risultati possono essere disposti in ordine di rango (ovvero di frequenza decrescente, dalla parola più frequente fino agli hapax), in ordine alfabetico a partire da sinistra o in ordine alfabetico a partire da destra.
La ricerca può essere raffinata specificando un valore minimo e un valore massimo di frequenza che devono essere soddisfatti, attivando o disattivando la distinzione maiuscole/minuscole, o cercando i type che contengono solo una determinata sequenza di caratteri (utile per isolare gli affissi). La lista di frequenze così ottenuta può inoltre essere esportata in formato .csv (o, se l'applicazione viene eseguita in un sistema Windows, nel formato proprietario di MSExcel).
In terzo luogo, TextSTAT permette di generare concordanze in formato KWIC (keyword in context) sia facendo doppio clic su un elemento della lista di frequenze che attraverso la relativa scheda dell'interfaccia. La ricerca può essere effettuata sulla base di un criterio ‘esatto’ (la presenza di una specifica stringa: parola, gruppo di parole, ecc.) oppure attraverso caratteri jolly.
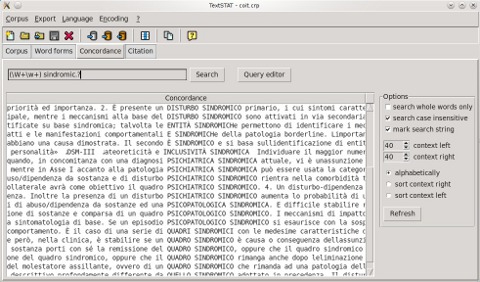 |
Per rendere questo compito facile a tutti gli utenti, anche con chi non ha familiarità con le espressioni regolari in generale e con la sintassi Python per le espressioni regolari in particolare, il programma permette di accedere a una comoda finestra di dialogo in cui è possibile inserire i parametri per le ricerche più elementari (es. gli estremi di un termine di ricerca e il numero di parole massimo e minimo fra di essi), anche se per i compiti più complessi si rende necessario consultare la documentazione.
La ricerca può essere raffinata specificando se cercare o meno oltre i limiti di parola (utile per evitare di specificare, ad esempio, l'espressione \W ai confini della stringa cercata) e distinguendo o meno fra maiuscole/minuscole. La lista di concordanze ottenuta può essere disposta in ordine alfabetico in base al contesto precedente o successivo al termine di ricerca oppure al termine di ricerca stesso se al suo interno erano contenuti caratteri jolly.
L'utente può anche stabilire i limiti di contesto a destra e a sinistra dei termini e ricerca e decidere di evidenziare questi ultimi mediante l'uso delle maiuscole. Inoltre, la lista di concordanze può essere esportata in formato .txt o nel formato proprietario di MSWord (funzionalità utile dal momento che TextSTAT, essendo multipiattaforma, può essere eseguito anche su sistemi Windows).
Infine, facendo doppio clic su una delle righe della lista di concordanze si accede alla quarta e ultima scheda, che permette di visualizzare una riga della visualizzazione KWIC in un contesto più ampio (circa 70 parole a destra e altrettante a sinistra). La riga selezionata viene evidenziata in rosso, mentre in alto appare un collegamento che punta al documento originario qualora fosse necessario prenderne visione nella sua interezza a patto che non sia stato modificato il percorso del relativo file.
Volendo formulare un giudizio complessivo, TextSTAT include tutte le funzionalità di base richieste a un concordancer e si rivela di grande aiuto per il singolo traduttore al fine di gestire corpora di dimensioni relativamente piccole come strumento di supporto per verificare le proprie ipotesi traduttive.
Questo non toglie che rimangano alcuni aspetti carenti o migliorabili: ad esempio, nonostante sia possibile attraverso opportune espressioni regolare effettuare ricerche a più cluster dato un termine di ricerca, non è tuttavia possibile effettuare alcun tipo di analisi di natura statistica sulle collocazioni.150 Altra funzioni non presenti sono la possibilità generare anche liste di parole chiave accanto alle semplici frequenze e il supporto agli n-grammi, purtroppo totalmente assente.
Anche dal punto di vista dell'interfaccia ci sono degli aspetti che possono essere migliorati, dal momento che la lista KWIC permette di disporre i risultati in ordine alfabetico solo in base alla stringa di ricerca, alla prima parola più a destra o a sinistra tralasciando tutti gli elementi precedenti (e successivi) del contesto. Anche l'evidenziazione tramite le lettere maiuscole rischia di risultare poco visibile qualora siano presenti sigle, titoli o altri elementi in maiuscolo nel contesto.
La funzione delle concordanze inoltre, nonostante sia richiamabile dalla lista di frequenze oppure cliccando sul relativo pulsante sotto la barra degli strumenti, non è accessibile dalla schermata di citazione per cui volendo effettuare una nuova ricerca è necessario spostarsi sulla scheda precedente. Non è altresì possibile osservare dall'interno del programma la posizione delle occorrenze di un termine nei documenti (utile nel caso in cui fosse necessario osservarne la distribuzione).
Dalla pagina principale del progetto è possibile scaricare un manuale per l'utente in inglese relativo alla versione 2.7 del programma [Bennett, 2008], valido anche per la versione successiva dal momento che quest'ultima costituisce in massima parte una bugfix release e non integra nessuna funzionalità sostanzialmente nuova.
La documentazione si limita, però alle funzionalità più elementari, lasciando all'utente il compito di prendere dimestichezza con il programma attraverso l'uso. Per alcuni aspetti più avanzati, come la ricerca mediante espressioni regolari all'interno del corpus, dall'interfaccia stessa dell'applicazione è accessibile l'esaustiva documentazione del modulo re di Python (ancora una volta in inglese).
Qualche ulteriore spunto di riflessione e informazione più dettagliata possono essere ritrovati nel manuale scritto dall'autore del programma disponibile in rete, anche se questo si riferisce a una versione della serie precedente e non è quindi immediatamente applicabile.
4.1.2 IMS Open Corpus WorkBench
| Autori: | Stefan Evert, Arne Fitschen et al. |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://cwb.sourceforge.net |
| Versione: | 3.0 (aprile 2010) |
IMS Corpus Workbench (CWB) è uno strumento di gestione e consultazione per corpora di grandi dimensioni sviluppato presso l'istituto di elaborazione del linguaggio naturale (Institut für maschinelle Sprachverarbeitung) dell'università di Stoccarda.
Il software è disponibile nella pagina principale del progetto sia in formato sorgente che in formato binario precompilato per la più diffuse piattaforme Unix-like (Linux 32 o 64 bit, Mac OS X, Solaris). Questi pacchetti rendono la procedura molto più semplice, dal momento che eliminano la necessità di compilazione e, grazie agli script di installazione l'utente può copiare in maniera automatica gli eseguibili nella corretta posizione in modo da poter utilizzare i programmi.
CWB rappresenta un'architettura formata da una serie di componenti discrete, chiamate anche ‘moduli’, che interagiscono fra loro permettendo metodi di accesso differenziati a più fonti di informazione diverse allo stesso tempo (a livello ‘logico’) in via del tutto indipendente dalla posizione a livello ‘fisico’ dei dati che costituiscono il corpus vero e proprio [Christ, 1994].
L'architettura modulare di CWB è volta a garantire la massima flessibilità e la possibilità di adattamento a diverse situazioni d'uso, l'interazione fra componenti locali e remote, l'elaborazione e la consultazione da parte di più client (e più interfacce), nonché l'utilizzo di un linguaggio di consultazione unificato indipendente dalla natura e dalla locazione delle risorse.151
CWB è costituito da una serie di utilità da riga di comando che rendono possibile la creazione di corpora consultabili che coprono la codifica e l'indicizzazione (ad es. cwb-encode e cwb-makeall), strumenti di estrazione di dati come liste di frequenze (anche più cluster, come cwb-gen-bigrams) e porzioni di testo dal corpus (come cwb-decode, cwb-lexdecode o cwb-scan-corpus), utilità di debug per il controllo delle varie fasi preliminari di preparazione del materiale e, soprattutto, il motore di ricerca e di interrogazione CQP (Corpus Query Processor).
È inoltre disponibile un pacchetto CWB/Perl contenente utilità per l'indicizzazione del corpus, la modifica creazione delle voci di registro (quali cwb-make o cwb-regedit), nonché una serie di API per diversi linguaggi di programmazione che permettono di avere accesso alle risorse linguistiche sfruttando il livello ‘fisico’ di accesso ai dati di CWB.
Sono disponibili, infine anche alcune interfacce alternative alla ‘classica’ riga di comando cqp fra cui un'interfaccia web nota come CQPweb che consente di utilizzare CEQL, una variante del linguaggio di interrogazione di CQP con una sintassi semplificata, utile per le risorse rese disponibili in linea anche ai meno esperti.152
Il software permette di gestire ed interrogare come basi di dati corpora mono- e plurilingui (sia comparabili che paralleli) e, contrariamente a strumenti di analisi più elementari, rende possibile il supporto diversi tipi di annotazione, ovvero l'inserimento di metadati aggiuntivi rispetto al materiale linguistico di cui è composto il corpus. In realtà, come si vedrà a breve, in CWB la differenza fra token e annotazioni è molto sfumata, dal momento che al livello più basso il lexicon è costituito da una serie di voci puramente numeriche ciascuna delle quali è sufficiente a individuare una ‘posizione’ all'interno del corpus, la cui parola associata non è che un mero attributo di natura posizionale (il primo e obbligatorio) al pari di tutte le altre annotazioni.
CWB supporta la presenza di più tipi e formati di informazione per rendere il corpus consultabile all'uomo e leggibile alla macchina: le annotazioni possono infatti essere presenti o meno a discrezione di ciascun utente-amministratore e, in caso affermativo, non esiste un paradigma di annotazione adottato come predefinito. Diversi formati e livelli di annotazione possono essere implementati in tutto o in parte in base all'uso che si intende fare del corpus e alla natura stessa dei testi.153
Dal punto di vista pratico, le informazioni di cui si compone un corpus in CWB possono essere organizzate su più livelli (non tutti necessariamente presenti allo stesso tempo):
- Attributi posizionali: ogni posizione del corpus è accompagnata un certo numero di attributi costituiti da stringhe di testo, fra i quali il più importante è la parola (che costituisce il token associato alla posizione), seguita da altre annotazioni quali la parte del discorso (POS, dall'inglese part of speech), le informazioni di natura morfosintattica (categoriali), la forma base (lemma) della parola, ecc.
- Attributi strutturali, collocati fra un token e l'altro e segnalano l'inizio e la fine di una delle unità costituenti (sezione, paragrafo, frase); a un livello di granularità inferiore gli attributi strutturali possono essere impiegati per segnalare l'inizio e la fine dei sintagmi ma, attualmente, non permettono l'annidamento ricorsivo di elementi della stessa natura uno all'interno dell'altro e rendono pertanto non immediata la trasposizione di rappresentazioni dei costituenti frasali come lo schema X-bar in uso nella grammatica generativo-trasformazionale.
- Attributi multilivello, che rappresentano relazioni a distanza all'interno o all'esterno del corpus, come gli n-grammi associati alla sequenza posizioni del corpus (attualmente il supporto è limitato ai bigrammi) o all'allineamento di determinate unità con il materiale in un'altra lingua nel caso in cui ci si trovi a gestire un corpus parallelo; a differenza degli attributi strutturali le annotazioni di questo tipo permettono la sovrapposizione e i collegamenti fra posizioni non adiacenti del corpus ma, tuttavia non supportano la ricorsività: ad es. è possibile collegare una frase a un'altra del corpus parallelo ma non, all'interno della frase, una parola a un'altra.
- Attributi dinamici, vale a dire, quegli attributi che non sono memorizzati a livello fisico ma vengono generati da uno strumento esterno dinamicamente nella fase stessa di interrogazione.
Affinché le informazioni qui presentate siano correttamente riconosciute e visibili durante l'interrogazione, il materiale, sia esso di natura linguistica o metalinguistica, richiede un laborioso processo di preparazione. Una descrizione in dettaglio delle fasi della preparazione va ben oltre la portata di questo lavoro e l'ottima documentazione fornita dagli sviluppatori comprende manuali guide pratiche per gli amministratori di corpora CWB. Quel che segue è un riassunto molto generale volto a far comprendere la complessità della procedura, decisamente fuori dalla portata del singolo traduttore.
CWB utilizza un proprio formato interno di sola lettura articolato in una serie di file per memorizzare i corpora tutti i livelli di annotazione elencati sopra (ben sette file sono necessari per i soli attributi a livello di token, cioè posizionali). È questo formato di sola lettura a permettere la modularità e la praticità di consultazione di corpora anche di grandi dimensioni, con l'eventuale possibilità di compressione per ridurre il consumo di spazio su disco.
La preparazione del materiale comporta una serie di operazioni come la normalizzazione del set di caratteri, la tokenizzazione (cioè l'isolamento dei token nel formato ‘verticale’ in cui ogni riga corrisponde a una posizione del corpus), la codifica binaria del lexicon nel formato interno di CWB con il relativo indice in cui ogni posizione è individuata da un intero senza segno.
Nel caso in cui si intenda realizzare un corpus annotato, è necessario inserire le annotazioni direttamente all'interno del file verticale oppure su file separati anche in un secondo momento. L'operazione di annotazione in generale, e di annotazione posizionale in particolare, può essere anche effettuata in un momento successivo, a patto di produrre i relativi file binari con cwb-encode e aggiornare i file di registro inserendo le dichiarazioni dei nuovi attributi. L'unico requisito necessario in questa fase è che ad ogni posizione del corpus risulti associato lo stesso numero di attributi posizionali.
Considerazioni simili riguardano gli attributi di natura strutturale, che possono essere inseriti sotto forma di marcatori in stile SMGL all'interno del file verticale a patto di passare le opportune opzioni allo strumento di codifica o aggiunte in un secondo momento con l'utilità cwb-s-encode.
La fase successiva prevede che il corpus venga registrato: tutti gli strumenti di CWB accedono al corpus non attraverso la posizione particolare dei singoli file quanto piuttosto attraverso un opportuno file di registro presente in una directory centrale,154 in cui sono contenuti tutti i registri dei corpus disponibili per l'utente.
Il file di registro è fondamentale, poiché contiene le informazioni sulla posizione di tutti i file fisici che costituiscono la rappresentazione interna di CWB, la dichiarazione di tutti gli attributi e l'elenco degli utenti cui consentire l' accesso in lettura. Inoltre, il nome del file di registro rappresenta il nome simbolico con cui gli utenti possono accedere al corpus in consultazione, dato che identifica in modo univoco la rappresentazione dei dati per il motore di interrogazione.
Da ultimo, è necessario procedere all'indicizzazione vera e propria degli attributi, per ognuno dei quali deve essere generata una serie di ulteriori file, con uno dei front-end messi a disposizione da CWB. Una volta ultimata anche questa operazione, i dati ‘fisici’ (ad es. il file verticale di partenza) non sono più necessari per la consultazione del corpus: la sua rappresentazione interna, eventualmente compressa per ridurre il consumo di spazio sul supporto di memorizzazione, e gli indici sono sufficienti a consentire l'accesso a tutti i dati.
Come già visto, infatti, a livello logico gli attributi posizionali definiti in fase di preparazione del materiale (anche in più momenti diversi, su più file fisici, ecc.) sono visti come una sequenza di entità associate a ogni posizione del corpus. Così il token, ossia la stringa di testo individuata da una specifica posizione è il valore dell'attributo Word, l'informazione categoriale il valore dell'attributo Pos, e così via. Il linguaggio di interrogazione di CQP permette proprio di individuare corrispondenze sulla base del valore di tali attributi, che possono essere combinati fra loro in sequenze di espressioni regolari che andranno a essere valutate per confronto con ciascuna posizione del corpus.
In fase di consultazione, il motore di interrogazione ricerca tutte le corrispondenze dell'espressione di ricerca all'interno del corpus. Le corrispondenze sono costituite da ‘intervalli’ del corpus le cui estremità sono rappresentate dalla posizione iniziale e finale della stringa di ricerca e la cui lunghezza è variabile indipendentemente dalla lunghezza della ricerca, dal momento che le espressioni regolari possono contenere quantificatori per designare eventuali ripetizioni della sottostringa cercata.
Il risultato di una ricerca è un insieme di corrispondenze, in altre parole, un insieme di intervalli del corpus [Christ, 1994]. La modalità di visualizzazione predefinita è KWIC, in cui la stringa cercata è evidenziata con colori e parentesi angolari, all'interno dell'interfaccia testuale di cqp, come output del comando di ricerca.
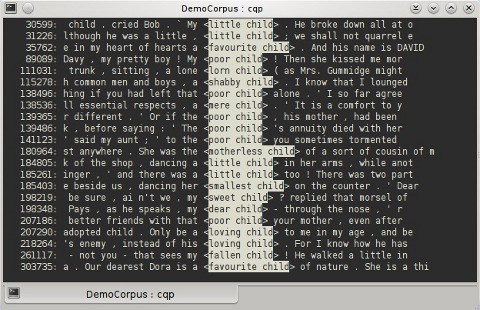 |
La maggior parte delle interrogazioni in CQP è realizzata sulla base di corrispondenze dei valori degli attributi posizionali e sulla posizione degli attributi strutturali, ragion per cui saranno questi due tipi il fulcro della breve trattazione che si presenta a continuazione.
Per quanto riguarda i primi, l'interrogazione avviene mediante una serie di condizioni, ciascuna associata ad almeno una chiave di ricerca. Come già detto, gli stessi token non sono che attributi posizionali al pari degli altri, per i quali la sintassi tipica precede una dichiarazione di attributo, seguita da un operatore booleano, seguito a sua volta dalla chiave di ricerca racchiusa fra apici doppi come, ad esempio, [word="child.*" & pos="N.*"];.
Come si può osservare, l'uso delle parentesi quadre separa le condizioni che si riferiscono a posizioni del corpus distinte le une dalle altre. È fondamentale in questo tipo di ricerche tenere in considerazione gli operatori logici and (&) e or (|), implicazione (->) e gli operatori di confronto (es. = ‘uguale a’, != ‘diverso da’) che vengono interposti fra l'attributo e la relativa chiave.
Inoltre, le stringhe all'interno delle chiavi di ricerca utilizzano la sintassi delle espressioni regolari (in stile grep) con i relativi metacaratteri (caratteri jolly, quantificatori, ecc.). Accanto ai quantificatori tipici delle espressioni regolari (+, *, ?) possono essere impiegati anche espressioni del tipo {m,n} dove m rappresenta il numero minimo di occorrenze e n il numero massimo entro cui deve essere compresa la corrispondenza (qualora fosse presente solo un valore numerico, questo è interpretato come il limite minimo di occorrenze necessarie per la corrispondenza). È da osservare, infine, che i quantificatori possono essere utilizzati non solo all'interno dei valori degli attributi posizionali, ma anche in riferimento a interi gruppi di condizioni racchiuse fra parentesi tonde.
Gli attributi dinamici da valutare ai fini della corrispondenza vengono specificati ancora una volta come condizioni all'interno delle parentesi quadre accanto a quelli posizionali. Un esempio di questo è l'attributo dinamico predefinito f, che valuta sulla base del parametro fornito la frequenza nel corpus dell'elemento specificato come argomento.
Così, ad esempio, per cercare i dieci aggettivi più ricorrenti nel corpus che co-occorrono con il sostantivo ‘child’, la ricerca potrebbe essere [word="child" & pos="N.*"][pos="JJ.*" & f(word)>10];.
Diverso è il discorso per gli attributi strutturali che, non facendo riferimento ad alcuna posizione ‘concreta’ nel corpus vengono richiamati semplicemente come tag SGML (<s>, <article>, ecc.). Ad esempio, per cercare i nomi propri presenti a inizio di frase è sufficiente digitare </s> [pos="NPS?"]; dove l'espressione </s> indica appunto la fine di una frase in maniera indipendente dal delimitatore, cioè dal segno di interpunzione presente nel testo.
Un uso particolarmente interessante delle unità di testo specificate dagli attributi strutturali permette di limitare le corrispondenze restituite all'interno dei confini delle unità in modo da ricercare, ad esempio, due parole separate da un numero arbitrario di elementi non specificati (indicati a CQP mediante l'espressione []*) ma all'interno della stessa frase o dello stesso testo della raccolta grazie al costrutto within. Un esempio di utilizzo di questo tipo di sintassi sarebbe nome:[pos="N.*"] ([]* word=nome.word] ){2} within s; il cui risultato è costituito da tutte le sequenze di posizioni del corpus in cui lo stesso sostantivo è presente almeno tre volte all'interno della stessa frase.
Come si può notare, nella sintassi CQP l'espressione [], spesso seguita da un quantificatore, corrisponde a una posizione generica, di cui non si vuole specificare alcuna caratteristica. L'esempio illustra anche una interessante funzionalità di CQP e cioè la possibilità di assegnare delle etichette a una condizione, in questo caso l'etichetta è ‘nome’, che assume il valore della posizione del corpus interessata dalla corrispondenza, i valori dei cui attributi possono essere richiamati all'interno di condizioni successive (nell'esempio il token stesso, cioè il valore dell'attributo word).
Nella visualizzazione dei risultati può inoltre essere specificato il contesto da mostrare a destra e a sinistra della corrispondenza cercata, tanto a dimensione fissa che dinamica (es. s a destra per visualizzare dalla posizione interessata fino alla fine della rispettiva frase, in un corpus contenente annotazioni di tipo strutturale). Il numero di corrispondenze, vale a dire la frequenza assoluta, può essere contato e stampato a schermo, oppure informazioni relative alla frequenza possono essere utilizzate a loro volta per filtrare i risultati mostrando solo un certo numero di risultati.
I risultati delle ricerche possono essere disposti in ordine alfabetico crescente o decrescente sulla base di uno qualsiasi degli attributi posizionali, oppure in ordine casuale indipendentemente dalla posizione del corpus in cui si trova la stringa cercata. La presenza di maiuscole o di segni diacritici ai fini dell'ordinamento può essere ignorata impostando dei particolari flag (%c e %d rispettivamente).
Parimenti, l'ordinamento può anche essere basato sul contesto a destra o a sinistra delle posizioni interessate dalla corrispondenza: è possibile utilizzare il contesto in modo assoluto, oppure limitatamente a un certo numero di posizioni o caratteri. La sintassi da utilizzare in questi casi è molto flessibile e sofisticata, permette infatti di ricorrere a punti di ancoraggio simbolici accompagnati da un eventuale spiazzamento positivo o negativo, nonché di effettuare ricerche in ordine diretto o inverso. Volendo proporre un semplice esempio, la stringa [pos="JJ.*"]{2}[pos="N.*"] sort by word %cd on match..matchend[-1]; corrisponde a tutti i sostantivi preceduti da almeno due aggettivi, e visualizza i risultati in ordine alfabetico basato sulla parola a partire dalla prima posizione (il primo aggettivo) fino alla penultima posizione (cioè l'ultimo della serie di aggettivi).
È da tenere presente che le ricerche possono essere effettuate tanto sul corpus nella sua interezza quanto su porzioni dello stesso individuate, ad esempio, da una ricerca precedente, che può essere memorizzata attraverso un'etichetta simbolica. CQP permette ulteriori filtri sui risultati attraverso le operazioni fondamentali fra insiemi (unione, intersezione, differenza) in modo da rendere le ricerche non solo precise e potenti ma anche di più facile comprensione per l'utente, dal momento che l'utilizzo di un operatore di questo tipo è più immediato rispetto a formulare una nuova ricerca includendo i criteri aggiuntivi specialmente nel caso in cui, come di frequente nel caso di interrogazione manuale dei corpora, la risoluzione dei problemi avviene per gradi e ipotesi successive (approccio prova-errore).
Chiaramente, il linguaggio di interrogazione supporta costrutti molto più complessi e quelli presentati non sono che una piccolissima frazione a titolo puramente esemplificativo delle possibilità in CQP di interagire con i diversi tipi di dati memorizzati all'interno del corpus.155
Uno dei punti di forza di CWB è infatti la documentazione abbondante ed esaustiva, che può essere reperita facilmente in inglese e in tedesco sulla pagina del progetto. Sono disponibili, d'altra parte, numerose guide passo per passo alla preparazione del materiale dei corpora e alla consultazione tramite CQP sulle quali è stata basata questa breve presentazione, in particolare [Evert, 2010a] e [Evert, 2010b].
Grazie alle sue caratteristiche, CWB è uno degli strumenti più avanzati oggi disponibili per la consultazione e l'analisi dei corpora, ed è infatti adottato in tutti i maggiori centri di ricerca nell'ambito della linguistica computazionale. Il vastissimo repertorio di funzionalità disponibili, di cui quelle presentate non sono che un pallido riflesso, non fa sentire affatto il bisogno di una GUI in senso ‘tradizionale’: l'interfaccia testuale di cqp è molto potente e, grazie alla flessibilità dello strumento, non rappresenta un limite, al contrario.
Tuttavia l'ingente mole di lavoro preparatorio per codificare il corpus e la necessità di apprendere un linguaggio come il CQP per l'interrogazione dello stesso lo rendono più adatto a linguisti, terminologi e lessicografi piuttosto che ai singoli traduttori.
Inoltre, per poter sfruttare al meglio le potenzialità del programma occorre avere a disposizione un corpus bilanciato e di dimensioni appropriate, ma a differenza di altri programmi più elementari considerati in precedenza in CWB la procedura di aggiunta di nuovi testi (da file locali o dal web) non è resa facile dal punto di vista dell'utente finale, visto il complesso iter preliminare di preparazione del materiale. Si rende necessario quindi un investimento in termini di tempo e di sforzo molto ingente, cosa che spesso va oltre le possibilità del singolo traduttore in vista di progetti di dimensioni medie o ridotte.
4.1.3 Considerazioni finali
Le alternative presentate in questa sezione, pur avendo lo scopo in comune, possono essere considerate diametralmente opposte in termini del target di utenti cui sono destinate: mentre TextSTAT è rivolto principalmente a studenti di corsi di lingue straniere cui un concordancer può essere utile anche e soprattutto ai fini dell'apprendimento, CWB è rivolto a ricercatori e linguisti computazionali.
Oltre che nelle funzionalità offerte, la differenza emerge anche nel livello di competenza richiesto per utilizzare i due strumenti. Il primo si presta ad essere utilizzato da comuni utenti ‘desktop’ e soprattutto da studenti non ancora in possesso delle competenze di traduttori o linguisti di professione. Funziona infatti senza problemi su tutti i sistemi operativi più diffusi, è dotato di un'interfaccia grafica semplice e intuitiva, non richiede particolari conoscenze per consultare, amministrare o costruire corpora di dimensioni ridotte e, anzi, facilita di molto il lavoro includendo anche funzionalità di conversione e addirittura di crawling integrate.
Diverso è il caso del secondo, che richiede invece uno sforzo in termini di tempo e competenze non indifferente per la creazione e la manutenzione dei corpora, peraltro giustificato se questi sono di dimensioni considerevoli. Già di per sé tale fatto, unito alla necessità dei programmi di un sistema Unix-like per funzionare,156 lascia immaginare una separazione dei ruoli (e delle postazioni) fra i responsabili della creazione e dell'amministrazione delle risorse ‘lato server’ e gli utilizzatori del materiale in consultazione ‘lato client’: non a caso i metodi di consultazione diffusi sono il cqp testuale, che ben si presta a essere utilizzato via connessione remota sicura (ssh), e le interfacce web.
Le differenze fra i due programmi si fanno ancora più evidenti se si prendono in esame le caratteristiche supportate. TextSTAT, ad esempio è ottimo per la visualizzazione di concordanze o l'elaborazione di wordlist e, con qualche accorgimento se si utilizzano le espressi regolari, anche per uno studio in prima approssimazione delle collocazioni (cfr. 39).
Rispetto alle più diffuse soluzioni proprietarie si riscontrano però alcune carenze che pongono seri limiti all'utilità del programma. Per quanto riguarda la lista delle frequenze, ad esempio, emerge l'impossibilità di gestire cluster di più unità, così come di studiare la distribuzione di queste ultime all'interno dei singoli documenti.
D'altra parte, la consultazione avanzata è ulteriormente limitata dall'assenza di supporto agli schemi di annotazione, il che impedisce la gestione delle informazioni strutturali o morfosintattiche considerate per CWB. Inoltre, TextSTAT non contempla alcun algoritmo in grado di estrapolare parole chiave, né sulla base di corpora di riferimento né di wordlist di lingua generale.
Visto il bacino d'utenza cui il programma è rivolto, non è possibile considerare questi aspetti come veri e propri ‘difetti’: il programma intende essere semplice, come evidenziato dal significato dell'acronimo contenuto nel suo nome, e si rivela uno strumento perfettamente per sia per i discenti di una lingua straniera che per i traduttori alle prese con progetti di medie e piccole dimensioni: in entrambi i casi la consultazione di un corpus è un'attività ‘accessoria’ rispetto allo scopo finale e cioè produrre un testo fruibile e accettabile secondo i canoni di un determinato uso linguistico (diafasia, convenzioni, ecc…).
Essendo rivolto agli studiosi di linguistica computazionale, CWB è invece uno strumento completo e soprattutto scalabile, in grado di adattarsi alle necessità di ogni singola applicazione, nel senso che pur essendo estremamente complesso le sue funzionalità possono essere sfruttate in tutto o in parte a seconda delle risorse disponibili (questa è la ragione della sua elaborata architettura modulare).
Un esempio della flessibilità di CWB è il supporto a più livelli per gli schemi di annotazione senza vincoli sulla qualità e la quantità delle stesse. Questo fa sì che possano essere adottate le procedure di annotazione automatiche e/o manuali che si ritengono più opportune anche in momenti potenzialmente diversi.
Il limite maggiore di un simile approccio, come già segnalato, è che comporta una mole di lavoro non indifferente e in genere fuori dalla portata del singolo individuo (come potrebbe essere un traduttore freelance) a meno che non si considerino corpora di dimensioni ridotte, ma con l'inconveniente la dimensione ridotta andrebbe a scapito della rappresentatività del campione.
Inoltre, nonostante CWB fornisca una serie di utilità per la costruzione del corpus, il motore di interrogazione CQP e un'interfaccia di consultazione, tutte le operazioni preliminari come la normalizzazione del set di caratteri, la tokenizzazione, l'annotazione e il riconoscimento dei lessemi devono essere portate a termine con strumenti esterni, alcuni dei quali disponibili fra i ‘tradizionali’ comandi per processare testo di Unix (iconv, tr, ecc…) ma altri non sempre accessibili e, purtroppo, non sempre liberi.157
La parte più interessante per il singolo traduttore è invece l'interfaccia di interrogazione del CQP che, disponendo di un corpus già preparato da altri, permette di ottenere una gran quantità di informazioni. Un ottimo esempio open source e consultabile via web con la sintassi CQP è rappresentato dai corpora OPUS158 (paralleli e allineati, con annotazione posizionale Pos).
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/