2.4 L'internazionalizzazione nel SL
Il movimento che ruota attorno al SL si propone di portare i propri ideali di libertà applicata al software a quanti più utenti possibile in tutto il mondo. Per questo motivo il SL è disponibile in numerose versioni localizzate, allo scopo di renderne più agevole l'utilizzo da parte degli utenti per cui l'inglese rappresenta un ostacolo o di chi semplicemente preferisce utilizzare il proprio computer nella propria lingua.
L'infrastruttura utilizzata nel SL per garantire il Native Language Support, cioè il supporto completo ai diversi locale, è GNU Gettext: una serie di strumenti volti a rendere i processi di internazionalizzazione e localizzazione quanto più semplici ed efficienti possibile.
L'implementazione di GNU Gettext ruota essenzialmente attorno al linguaggio C. Nonostante, infatti, la maggior parte dei moderni linguaggi di programmazione abbia un supporto nativo per l'internazionalizzazione il C, il linguaggio maggiormente utilizzato agli inizi del progetto GNU e alla base del sistema operativo Unix, non era dotato di una libreria di internazionalizzazione o per lo meno di una libreria di internazionalizzazione disponibile sotto licenza libera. Il progetto GNU si propose di risolvere il problema creando la libreria gettext [Prudêncio, 2006].
Attraverso GNU Gettext è possibile gestire tutti gli aspetti che necessitano di localizzazione (chiamati categorie o ‘locale categories’): la rappresentazione dei numeri, il formato di data e ora, la valuta, il set di caratteri e, chiaramente, le stringhe che verranno visualizzate dai programmi. Per esigenze di brevità, tuttavia, questo lavoro si concentrerà esclusivamente sull'ultimo ambito: la localizzazione dei messaggi di testo.
Come si è detto nel capitolo 1, il principio fondamentale su cui si basa l'internazionalizzazione è la separazione delle stringhe testuali da tradurre (elementi dell'interfaccia, messaggi di stato, messaggi di errore, ecc.) in appositi file di risorse esterni al codice sorgente, su cui il traduttore possa lavorare con facilità.
Attraverso una serie di librerie e di utilità, GNU Gettext permette di svolere non solo questo compito, ma di assicurare la sostituzione delle stringhe originali con le traduzioni durante l'esecuzione del programma (runtime), oltre a consentire una più agevole gestione dei progetti di localizzazione multilingui e facilitare l'aggiornamento delle traduzioni al rilascio delle nuove versioni del software.
L'infrastruttura GNU Gettext è analizzata con maggiori dettagli nelle sezioni 2.4.1 e 2.4.2 in quanto rappresenta sicuramente un ottimo esempio delle questioni che sorgono nell'internazionalizzazione e localizzazione di software. Trattandosi di SL, inoltre, i meccanismi sono ‘aperti’ e quindi visibili a tutti anche in termini di gran quantità di materiale tradotto accessibile.28
2.4.1 Il funzionamento di GNU Gettext
Quel che si viene a creare utilizzando GNU Gettext è una sorta di ‘catena di montaggio’ della localizzazione, che può essere illustrata attraverso lo schema riportato in figura 4.
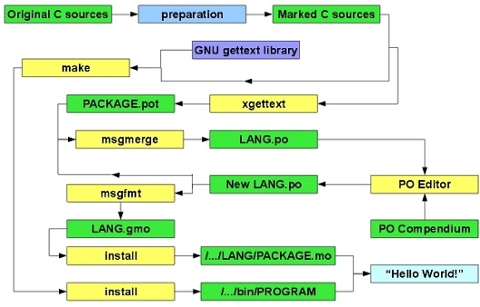 |
Dal codice sorgente opportunamente preparato vengono estratte le stringhe traducibili, queste vengono in seguito confrontate con le eventuali traduzioni preesistenti delle versioni più vecchie del programma e confluiscono in un file di risorse destinato ai traduttori.
Una volta completata la traduzione il file di risorse viene trasformato affinché sia possibile l'interazione con l'eseguibile del programma a runtime, infine tanto il software quanto il file contenente i messaggi tradotti vengono installati nelle posizioni corrette all'interno del sistema.
Il principio di funzionamento basilare di GNU Gettext può essere reso più chiaro attraverso un esempio semplificato. Verrà presentata qui di seguito l'applicazione dei processi di internazionalizzazione e localizzazione dall'inglese in italiano al più elementare codice C — ovvero il primo programma presentato al lettore del classico testo di B. W. Kernighan e D. M. Ritchie su tale linguaggio di programmazione — che si limita a stampare a schermo una stringa di testo (fig. 5).
|
Volendo localizzare questo programma in italiano, sarebbe necessario tradurre solo ed esclusivamente la stringa passata come parametro alla funzione printf. Tuttavia, com'è possibile vedere, realizzando questo programma non sono stati seguiti i principi della corretta internazionalizzazione perché la stringa da tradurre è stata inserita direttamente nel codice (hard-coded), rendendo in tal modo impossibile procedere alla localizzazione del programma senza intervenire direttamente sul sorgente. Questo comporta il rischio di modifiche involontarie tali da impedire il funzionamento del programma o introdurre bug e che possono rivelarsi molto difficili da individuare, soprattutto in progetti che coinvolgono un gran numero lingue e molte righe di codice.
Attraverso GNU Gettext — come dice il nome stesso («get text») — diventa invece possibile estrarre in maniera automatica dal codice sorgente del programma le stringhe che necessitano di traduzione, grazie allo strumento dedicato xgettext. Affinché questo sia possibile devono però essere apportate alcune modifiche al codice sorgente: in particolare, affinché l'operazione vada a buon fine, le stringhe traducibili devono essere segnalate (o ‘marcate’) dal programmatore in un modo particolare.
Riprendendo l'esempio precedente, ecco uno dei modi in cui si potrebbe riscrivere il codice sorgente, opportunamente internazionalizzato e con le dovute aggiunte per permettere l'esecuzione della versione localizzata.
|
Il sorgente così modificato può essere compilato con il comando gcc hello.c -o helloworld.out ottenendo il relativo file eseguibile helloworld.
Come si può osservare, nel sorgente è stata necessaria l'inclusione di nuovi file di intestazione, in modo da permettere le successive chiamate alle nuove funzioni. Di queste, senza dubbio la più importante è gettext, all'interno della quale sono state ‘inglobate’ le stringhe traducibili.
In tal modo l'argomento della funzione printf viene a essere, a sua volta, il risultato restituito dalla funzione gettext. Per risparmiare tempo, invece di digitare per esteso il nome della funzione gettext per ogni singola stringa, è convenzione fra i programmatori definire una macro inserendo la direttiva per il preprocessore #define _(String) gettext(String) attraverso la quale è possibile racchiudere le stringhe da tradurre all'interno dei caratteri _() (che verranno sostituiti prima della compilazione vera e propria).
L'impiego della funzione gettext rende possibile modificare la lingua del programma in fase di esecuzione vale a dire, nell'esempio in esame, cambiando la lingua della stringa che verrà stampata a schermo. Utilizzando la funzione setlocale per azzerare la macro-variabile LC_ALL non viene impostata di fatto alcuna lingua per il programma permettendo così che quest'ultimo ‘erediti’ la configurazione dal contesto, in base al valore delle variabili d'ambiente impostate nel sistema operativo in cui viene eseguito.
Perciò, eseguendo il file binario, in base alle variabili d'ambiente relative alla lingua (tipicamente $LANG)29 il programma si adatterà alla lingua di sistema. Nel caso in esame, provando a lanciare l'eseguibile si noterà come venga restituita la stringa d'esempio, ma ancora in inglese. Questo accade perché, nonostante nel sistema in uso la variabile d'ambiente $LANG sia impostata a it* (ad es. it_IT.UTF-8), non è stato possibile trovare alcun file contenente la localizzazione nella directory predefinita dei messaggi tradotti, vale a dire /usr/share/locale/<sigla_locale>/LC_MESSAGES.30 Nei passaggi successivi si vedrà come è possibile ottenere il file necessario, in questo caso: /usr/share/locale/it/LC_MESSAGES/hello.mo, il cui nome deve corrispondere a quanto specificato attraverso la funzione textdomain utilizzata nel sorgente del programma (qui per semplicità è stato scelto un nome che rimanda a quello del programma in modo da renderne più facile l'individuazione).
Per ottenere questo file, è necessario procedere alla localizzazione vera e propria. La fase preliminare prevede, appunto, l'estrazione delle stringhe traducibili dal file sortente attraverso lo strumento xgettext, mediante il quale è possibile ottenere un file PO (Portable Object) oppure un file POT (Portable Object Template), cioè il modello da cui ricavare i file .po per le varie lingue di progetto.
Si immagini di aver chiamato il file sorgente dell'esempio precedente hello.c. Eseguendo a questo punto il comando xgettext hello.c -o hello.pot si avrà la creazione di un nuovo file chiamato hello.pot, contenente la lista delle stringhe da tradurre.
In fase di esecuzione le stringhe in lingua di partenza verranno automaticamente sostituite dalla relativa traduzione sulla base del loro msgid (message identity), che deve pertanto essere univoco. In genere i file POT, i modelli non orientati verso nessuna lingua in particolare, vengono creati dallo sviluppatore stesso.
Gli incaricati della localizzazione nelle singole lingue, in seguito, possono ricavare da questo modello i file su cui lavorare attraverso lo strumento msginit con il comando (sarà necessario rispondere alle domande poste interattivamente dal programma) msginit -i hello.pot -o hello.po.
La differenza principale fra il file PO così ottenuto e il modello originale è contenuta nel primo messaggio, il cosiddetto ‘PO header’ (cfr. 2.4.2). I campi di questa intestazione appaiono ora in parte completati (in base alla lingua impostata nel sistema, alla propria identità, ecc.) e soprattutto il messaggio non è più contrassegnato come fuzzy.
Una volta ottenuto il file PO, questo può essere elaborato dal traduttore attraverso un semplice editor di testo oppure uno strumento dedicato, inserendo le traduzioni delle stringhe nel campo msgstr "". In figura 7 si riporta l'aspetto che verrebbe ad aver il file hello.po una volta ultimata la traduzione.
|
I file PO si collocano, dal punto di vista concettuale, sullo stesso piano rispetto al codice sorgente del programma dal quale, infatti, derivano. Si tratta di file human readable (intellegibili da parte dell'uomo) su cui lo sviluppatore interviene direttamente e indipendenti dalla piattaforma. Inoltre, al pari del codice sorgente (cfr. par. 2.1.1) devono subire un processo di compilazione per poter essere eseguiti dalla macchina (ovvero, caricati dinamicamente a runtime sulla base delle impostazioni di sistema).
A questo scopo, GNU Gettext mette a disposizione lo strumento msgfmt. Questo ha il duplice scopo di eseguire un controllo del file PO verificando ad esempio che sia stata rispettata la struttura sintattica del formato e di procedere alla sua compilazione (cfr 3.4.1). Eseguendo pertanto il comando msgfmt hello.po -o hello.mo otterrà un file MO (Machine Object) contenente il catalogo dei messaggi destinato all'esecuzione. Le stringhe non tradotte o marcate come fuzzy vengono ignorate e appariranno in inglese durante l'esecuzione da parte dell'utente finale, dando origine a un programma ‘misto’ localizzato solo in parte.
I file MO sono molto vicini dal punto di vista concettuale al codice oggetto del programma. Si tratta di file di natura binaria non destinati a essere modificati dall'uomo ma solo ad essere letti dalla macchina e, pur derivando dallo stesso file PO, il loro formato può variare da sistema a sistema. L'unico sistema per modificare un file MO è decompilarlo con lo strumento msgunfmt, intervenire sul relativo PO e quindi rieseguire msgfmt.31
Come già detto, affinché sia possibile che il catalogo contenuto nel file MO sia utilizzato in fase di esecuzione è necessario che tale file abbia il nome specificato come argomento della funzione textdomain nel sorgente e che venga copiato nella directory predefinita dei messaggi tradotti del sistema (o nella posizione non standard impostata tramite bindtextdomain). Eseguendo a questo punto il programma, la stringa apparirà finalmente in italiano.
GNU Gettext permette inoltre di gestire gli aspetti dinamici della localizzazione del software che è un processo continuo durante l'intero ciclo di vita del programma.
A ogni aggiornamento di versione, infatti, tipicamente saranno state aggiunte, eliminate o modificate alcune stringhe, per cui devono essere disponibili degli strumenti che permettano di gestire con anche i conseguenti aggiornamenti dei cataloghi dei messaggi con la stessa facilità con cui è possibile portare a termine il primo ciclo di localizzazione.
Dato un file PO già tradotto relativo alla versione precedente del programma e un file POT aggiornato all'ultima versione, grazie allo strumento msgmerge è possibile ottenere un nuovo file PO aggiornato oppure, in alternativa, aggiornare quello di partenza (opzione -U). In ognuno dei due casi, il file di destinazione conterrà quattro tipi di stringhe.
In primo luogo, saranno presenti le stringhe già tradotte con tutti i riferimenti (i commenti #:, cfr. 2.4.2) aggiornati alla nuova posizione nel codice sorgente. Il secondo caso è costituito dai segmenti tradotti in precedenza ma non presenti nella nuova versione, che verranno marcati come obsoleti e spostati alla fine del file.
In terzo luogo, il file aggiornato conterrà tutte le stringhe nuove presenti nel POT ma non tradotte in precedenza, che verranno aggiunte fra le altre coppie in base all'ordine in cui compaiono nel sorgente (in modo da permettere di ricostruire gli eventuali legami fra le stesse) pronte per essere tradotte.
Il quarto caso è però il più interessante dal punto di vista del traduttore, perché riguarda le stringhe il cui msgid ha subito delle modifiche ma non è stato interamente cambiato. In quest'eventualità viene applicata la funzione di fuzzy matching inclusa in msgmerge: i segmenti contenuti nel PO ‘simili’ ma non del tutto uguali al nuovo modello verranno aggiornati per quanto riguarda i riferimenti al sorgente ma verrà anche inserita in automatico la traduzione preesistente nel relativo campo msgstr e il messaggio verrà marcato come fuzzy.
Inoltre, eseguendo il comando msgmgerge è anche possibile specificare attraverso l'opzione -C uno o più file chiamati compendia contenenti un insieme di messaggi ricorrenti già tradotti e comuni a diversi programmi. È interessante notare come il file PO della versione precedente e il compendium in associazione con lo strumento msgmerge svolgano una funzione equiparabile a quella delle TM nella traduzione assistita ‘tradizionale’.
GNU Gettext comprende molte altre funzionalità come strumenti per manipolare i file PO al fine di estrarre solo stringhe con determinati attributi, confrontare più file e rimuovere i messaggi duplicati. In opposizione alla procedura ‘manuale’ qui descritta a titolo di esempio, sono inoltre disponibili dei programmi che automatizzano in parte la gestione e la manutenzione di progetti multilingui (come gettextize).
Una trattazione completa di tutti questi strumenti sarebbe impossibile in questa sede, per tutti gli approfondimenti si rimanda quindi alla documentazione di GNU Gettext disponibile in formato Texinfo in tutti sistemi GNU in cui tale infrastruttura è installata oppure online, ad esempio in GNU Project [2010a].
2.4.2 Il formato PO
Come descritto nel paragrafo precedente, il formato principale attraverso il quale viene realizzata la localizzazione avvalendosi dell'infrastruttura GNU Gettext è il PO, che si è pertanto affermato come il principale veicolo di gestione delle traduzioni nel SL (e non solo). Tale formato è stato implementato per la prima volta dalla Sun Microsystems sul sistema Solaris, sulla base di uno standard Uniforum [Ferretti, 2004, s.p.].
Si tratta di un formato compatto, facilmente leggibile e in grado di contenere non soltanto le stringhe traducibili ma anche una serie di informazioni accessorie utili per la traduzione e che vale la pena di considerare con più attenzione. Nel capitolo 3, infatti, verrà considerata una serie di editor di file PO, che si distinguono gli uni dagli altri proprio per la modalità di modifica e la visualizzazione delle informazioni contenute nei file di lavoro.
Volendo quindi lavorare con un editor specializzato piuttosto che con un semplice editor di testo generico, è importante che il traduttore conosca i dettagli di questo formato, in modo da saper valutare i pregi e i difetti di ciascuna applicazione, perché non tutte danno accesso alla totalità delle informazioni e non tutte nello stesso modo.
Va precisato che i PO e i POT sono file di testo semplice. La codifica predefinita è UTF-8 (in alcuni progetti obbligatoria). Utilizzarne una diversa è possibile, a condizione che sia dichiarata nell'intestazione, ma non auspicabile. Nei progetti di localizzazione in cui i volontari lavorano su sistemi operativi diversi per assicurare la leggibilità può essere necessario adottare anche una convenzione sul carattere di fine riga da usare. In genere viene impiegato LF (line feed), vale a dire il formato tipico dei sistemi Unix-like.
La struttura dei file PO
Un file PO è costituito da una serie di stringhe in inglese, ciascuna accompagnata dall'eventuale traduzione in lingua d'arrivo. Per questo motivo un file in questo formato è rappresentato da una successione di coppie msgid/msgstr, che vengono a formare il cosiddetto ‘catalogo dei messaggi’ (message catalogue).
Il concetto di catalogo dei messaggi è in parte sovrapponibile a quello di TM, in quanto entrambi svolgono un ruolo ‘intermedio’ nel processo di localizzazione ed entrambi hanno la funzione di immagazzinare le traduzioni. In realtà il PO, a differenza di una TM, è strettamente legato al contenuto di partenza (cioè al codice sorgente) e viene usato per generare direttamente il contenuto ‘d'arrivo’ (il file MO), ragion per cui è possibile accostarlo, più che a una memoria, a un formato di scambio bilingue.32 Per altri motivi, come la presenza dei messaggi obsoleti, il PO è invece più simile a una memoria di traduzione che a un semplice formato bilingue orientato a un singolo task di traduzione.
Oltretutto una raccolta di file PO precedentemente tradotti relativi a programmi diversi (compendium) può essere utilizzata come una vera e propria TM e infatti esistono una serie di strumenti che permettono la conversione dal formato PO al TMX e viceversa.33
In questo modo è possibile accedere al catalogo dei messaggi in modalità interattiva durante la traduzione con uno strumento CAT/TM. Come detto in precedenza, l'utilità msgmgerge di GNU Gettext permette di utilizzare il catalogo dei messaggi per la pretraduzione automatica e il recupero dei fuzzy match da un compendium in modo non interattivo. In maniera analoga, l'utilità pot2po del Translate Toolkit permette di generare un file PO per la traduzione a partire da un modello impostando anche la soglia di corrispondenza personalizzata per la TM (ancora in formato PO).
Passando dalla teoria alla pratica, il catalogo dei messaggi di un file PO34 è illustrato nella figura 8. Com'è possibile notare, ogni messaggio originale è segnalato dalla voce msgid ed è racchiuso fra apici doppi. La relativa traduzione, all'interno del campo msgstr è anch'essa compresa fra apici doppi.
|
Quando un messaggio o la relativa traduzione sono lunghi (in genere, oltre la soglia di 80 caratteri) è possibile andare a capo inserendo gli apici di chiusura e riaprendoli alla riga successiva (fig. 9).
|
Questo non comporta alcuna differenza dal punto di vista del risultato, perché utilizzando tale convenzione le stringhe verranno concatenate. Se un messaggio si estende su più righe è buona norma iniziare con una stringa vuota dopo msgid e msgstr in modo che tutte quelle successive risultino allineate a sinistra, per una migliore leggibilità. Alcuni editor gestiscono la divisione delle righe in modo automatico, ma in altri casi è necessario intervenire manualmente. È importante ricordare, quindi, che affinché il file sia valido ogni riga deve essere racchiusa fra apici doppi.
Il fatto che gli apici doppi siano utilizzati come delimitatori delle stringhe implica che questi non possono essere inseriti direttamente all'interno delle stesse. Per questo motivo, laddove una lingua utilizzi come virgolette tipografiche gli apici doppi, per inserirli è necessario ricorrere al carattere di escape \.
In modo simile a \, esistono altre sequenze di escape che si trovano con frequenza nei file PO, come la tabulazione (\t) e il carattere di newline (\n).35 Anche per inserire la barra inversa è necessario ricorrere a //, perché una barra singola è interpretata sempre come inizio di sequenza di escape.
|
Lasciare il campo della traduzione vuoto non invalida il file ma, una volta compilato e installato, l'applicazione mostrerà il relativo messaggio in inglese non trovando alcuna traduzione nel catalogo.
Tutte le righe che iniziano con il carattere # sono invece commenti, che svolgono una particolare funzione per il traduttore e il revisore oppure hanno un significato particolare per gli strumenti di controllo (quali msgfmt).
Gli elementi costitutivi dei file PO
Un file PO contiene al suo interno una serie di campi e di commenti. La differenza fra queste due componenti è che i commenti vengono ignorati in fase di compilazione, mentre i campi sono significativi.
Per la precisione, i campi sono msgstr, contenente la traduzione, msgctxt, contenente l'eventuale contesto di disambiguazione e msgid, contenente il messaggio di partenza.
Il valore dei campi ha due funzioni: contenere il catalogo delle traduzioni e permettere l'identificazione del messaggio affinché la sua traduzione sia visualizzata al posto della stringa originale in fase di esecuzione. Per questo motivo esistono due tipi di campi: identificativi e non identificativi.
Il campo msgctxt è l'unico opzionale: viene usato solo in casi particolari ma, quand'è presente, ha valore identificativo. La sezione contenente la traduzione dev'essere sempre presente, anche se vuota (msgstr " "), ma non ha alcun effetto ai fini dell'identificazione del messaggio. L'elemento msgid, infine, è obbligatorio, non può essere vuoto36 ed è il principale responsabile dell'identificazione del messaggio. Questo può variare la sua posizione all'interno del file PO: possono variare i suoi commenti o la traduzione, ma fintanto che msgid e msgctxt sono invariati, per GNU Gettext si tratterà sempre dello stesso messaggio.
I commenti, invece, sono irrilevanti ai fini dell'identificazione del messaggio. Esistono cinque categorie di commenti che hanno in comune il fatto di essere introdotti dal carattere #. Gli unici destinati a essere modificati dal traduttore sono quelli in cui il carattere di commento è seguito da uno spazio vuoto (#_), chiamati appunto ‘commenti del traduttore’ che permettono di inserire annotazioni e si mantengono attraverso il ciclo di vita del PO.37
I commenti presenti negli esempi visti finora sono introdotti invece dalla sequenza #: e, com'è possibile osservare, contengono le informazioni relative alla posizione del messaggio nel codice sorgente. Grazie a questi commenti, ossia grazie ai riferimenti al sorgente, il traduttore può avere maggiori informazioni sul contesto in cui compare il messaggio (dato che, trattandosi di SL, il sorgente è facilmente disponibile).
Ad esempio, controllando il codice nella posizione indicata per la prima stringa in fig. 8, è possibile dedurre che la stringa ‘Exact match’ viene utilizzata in una casella di spunta all'interno di una barra di ricerca. Molti editor di file PO permettono di avere accesso al punto del sorgente contenuto in questo tipo di commenti con un clic o con una scorciatoia (cfr. sez. 3.3).
In alcuni casi il riferimento al codice sorgente, però, non è sufficiente a garantire la qualità della traduzione. Lo sviluppatore può quindi inserire nel sorgente dei particolari commenti prima di richiamare la funzione gettext. Tali commenti verranno estratti automaticamente da xgettext (se eseguito con le opportune opzioni) e inseriti nel file PO, segnalandoli con un punto dopo il carattere di commento (#.). I commenti vengono riconosciuti dal programma di estrazione perché iniziano tutti con un'espressione convenzionale (ad esempio ‘i18n’ in KDE o ‘translator(s)’ in GNOME).
Esistono tuttavia dei casi in cui questo genere di commenti viene inserito non dallo sviluppatore ma in via automatica dal programma di estrazione. Nelle traduzioni per KDE, ad esempio, è frequente per indicare la posizione della stringa nei file .ui di interfaccia grafica, poiché il riferimento al ‘sorgente’ .cpp punta in realtà a un file temporaneo38 presente al momento della creazione del PO (v. fig. 11). In questo stesso esempio è possibile osservare un secondo commento estratto automaticamente, grazie al quale è possibile capire che la stringa in questione andrà a costituire il titolo della finestra principale.
| #. i18n: file: MainWindow.ui:17 #. i18n: ectx: property (windowTitle), widget (QMainWindow, MainWindow) #: rc.cpp:6 rc.cpp:64 MainWindow.cpp:291 MainWindow.cpp:407 msgid "Office Viewer" msgstr "Visore per Office" |
Traducendo documentazione (ad es. in un formato SGML) i commenti estratti automaticamentehanno invece la funzione di segnalare il livello (titolo, paragrafo, chiave di ricerca) della stringa in questione.
Nel caso riportato in fig. 12, ad esempio, il commento permette di capire che la stringa costituisce il titolo di una sezione del manuale.
|
Osservando con attenzione gli esempi appare evidente un'altra importante caratteristica del formato PO: qualora la stessa stringa appaia più volte all'interno del sorgente, questa non viene riportata altrettante volte nel catalogo. Ciò è dovuto al fatto che, come visto in precedenza, in fase di esecuzione i messaggi vengono identificati ed estratti dal catalogo sulla base del loro msgid, che quindi deve essere univoco.
La diretta conseguenza di ciò è che in un file PO non possono esistere due messaggi aventi lo stesso msgid: il messaggio comparirà solo una volta e i riferimenti a tutte le sue occorrenze nel sorgente verranno raggruppati in un unico commento (#:).
Se ciò da un lato evita di fare più volte lo stesso lavoro (la ripetizione della stringa equivale infatti un match interno), può anche portare a un grande potenziale svantaggio.
Avendo a che fare con messaggi formati da poche parole, com'è tipico nelle interfacce grafiche, può infatti accadere che una stringa necessiti di più traduzioni diverse in lingua d'arrivo. Per esempio, un solo termine che può essere sia un sostantivo che un verbo, o un aggettivo che può subire variazioni morfologiche di genere e numero in lingue come l'italiano.
La soluzione offerta da GNU gettxt e dal formato PO per questo genere di problemi è introdurre un campo identificativo speciale (msgctxt) che, associato al msgid rende nuovamente univoca la stringa.39
Attraverso questo campo è possibile offrire al traduttore ulteriori indicazioni utili per la traduzione. È molto importante, quindi, che anche l'editor utilizzato per tradurre il PO tenga conto che apparenti ‘ripetizioni’ non sono in realtà tali se hanno un contesto diverso anche se questa caratteristica, purtroppo, non è sempre implementata (cfr. 3.3.1). Nel caso della fig. 13, ad esempio, è stato segnalato che la stringa si riferisce a una ‘nuova sessione’ e non all'apertura di un ‘nuovo file’.
|
Quando il ciclo della localizzazione viene ripetuto in occasione del rilascio di una nuova versione del software, il programma msgmerge gestisce l'aggiornamento del file PO introducendo alcuni nuovi elementi e modificandone altri. Tutti i messaggi in cui msgid e msgctxt sono rimasti invariati non subiscono alcuna variazione, eccetto l'eventuale aggiornamento dei riferimenti qualora la loro posizione nei sorgenti fosse cambiata.
Anche per i messaggi completamente nuovi, nulla di diverso rispetto a quanto detto finora: le nuove stringhe sono inserite all'interno del file fra quelle già presenti, seguendo l'ordine in cui si presentano nel sorgente. I nuovi messaggi sono costituiti, come sempre, da campi identificativi, sezione per la traduzione, commenti estratti automaticamente e riferimenti alla posizione nel codice.
I messaggi non più presenti nel nuovo codice sorgente e non recuperabili come fuzzy subiscono invece un trattamento particolare. Non vengono eliminati subito, come si potrebbe pensare, ma vengono spostati in fondo al file e commentati con la sequenza # . Tutti i commenti riguardanti questi messaggi sono eliminati, ad eccezione dei commenti del traduttore (indipendenti dalla presenza o meno della stringa nel codice sorgente).
Ai fini del lavoro di traduzione e della successiva compilazione è come se questi messaggi non esistessero, per questo motivo gli editor di file PO non ne permettono in genere la visualizzazione. Ciononostante sono mantenuti per un certo periodo perché potrebbero essere inclusi nuovamente nel sorgente più avanti, se la porzione di codice che conteneva tali messaggi è stata rimossa solo in via temporanea.
La funzione svolta dai messaggi obsoleti è in diretta concorrenza con quella di una memoria di traduzione. Se tutti i traduttori condividessero la stessa TM nel corso del progetto, non ci sarebbe infatti alcuna necessità di mantenere i messaggi obsoleti; tuttavia questo non sempre è possibile e non tutti i traduttori usano strumenti CAT/TM.
I messaggi in cui il msgid o il msgctxt ha subito variazioni sono considerati come nuovi messaggi ai fini della localizzazione. Tuttavia gli strumenti di aggiornamento come msgmerge dispongono di un algoritmo di confronto fra segmenti in grado di individuare le stringhe che hanno subito variazioni parziali. Anche l'aggiunta o la perdita di un campo msgctxt, avendo quest'ultimo valore identificativo, fa sì che il messaggio risulti come nuovo e che la traduzione precedente sia recuperata per via del msgid invariato pur non essendo considerata un match completo.
I messaggi per cui è stato possibile recuperare una traduzione sulla base dell'algoritmo di confronto saranno segnalati attraverso un nuovo tipo di commento: il flag #, fuzzy (si tornerà in seguito sulla funzione dei flag). Questo fa sì che il messaggio, pur contenendo un campo msgstr non vuoto, non sia considerato come tradotto, perché in attesa di verifica da parte del traduttore umano, ma tuttavia facilita l'aggiornamento perché evita di ripetere parte del lavoro già svolto in precedenza.
Oltre a questo flag, i messaggi fuzzy possono contenere anche un altro tipo di commenti e cioè il vecchio msgid (e, qualora sia stato aggiunto o modificato, anche il msgctxt) del file PO precedentemente tradotto.40 In questo modo il traduttore potrà fare il confronto in modo molto più facile, senza cercare di ricostruire la natura del cambiamento (che potrebbe essere anche la correzione di un errore tipografico) e senza bisogno di andare a controllare il PO della versione precedente. I commenti di questo tipo sono segnalati da #| com'è possibile vedere nell'esempio in fig. 14.
|
Un file PO è formato, infine, anche da alcuni elementi che non contengono alcuna traduzione. Si tratta dei commenti iniziali e dell'intestazione, di cui si è già visto un esempio in fig. 7.
In genere un file PO inizia con una serie di commenti (non obbligatori): il primo normalmente rappresenta il titolo del file e specifica quale programma viene tradotto e in quale lingua. Gli altri commenti forniscono informazioni relative alla licenza e alle persone che hanno lavorato sul file nel corso degli anni.
L'intestazione, invece, ha la struttura a campi tipica dei messaggi, ma si distingue dai messaggi propriamente detti per avere il msgid vuoto. All'interno della sezione msgstr sono contenute informazioni di natura amministrativa. La struttura di questo pseudo-messaggio è formata da una serie di stringhe concatenate, ciascuna delle quali termina con un carattere di newline (dette ‘campi’ dell'intestazione).
I campi hanno la struttura chiave: valore il cui significato è facilmente ricavabile dal nome. Vengono completati automaticamente se si usa msginit per ricavare il PO, sulla base delle variabili d'ambiente e di alcune domande interattive durante l'esecuzione del comando.
Anche utilizzando molti editor di file PO dedicati i campi saranno riempiti senza bisogno di ulteriori interventi, sulla base delle impostazioni memorizzate nel programma stesso al momento dell'installazione. Vale comunque la pena di notare il campo contenente le informazioni sul set di caratteri (qualora non fosse presente verrà restituito un errore in fase di compilazione).
L'ultimo campo dell'intestazione è particolarmente interessante e riguarda il modo di gestire i plurali. Nell'ottica di una buona localizzazione non ha senso inserire nei messaggi espressioni come ‘%d file(s)’ perché questo renderebbe alquanto arduo per il traduttore produrre un solo messaggio accettabile per qualsiasi valore di %d.
Per questo motivo i messaggi contenenti placeholder destinati a essere sostituiti con numeri hanno due identificatori distinti in inglese: msgid e msgid_plural.
Come viene gestita, invece, la situazione in lingua d'arrivo? Qualsiasi studente di questa facoltà sa che non è possibile dare per scontato che tutte le lingue seguano la stessa regola dell'inglese per il plurale. Per ciascuna lingua diviene necessario quindi dichiarare nell'intestazione il numero di forme esistenti (per ognuno dei quali esisterà un msgstr diverso indicizzate a partire da zero) e specificare una regola attraverso la quale la funzione gettext calcolerà il caso da applicare.
L'italiano segue la stessa regola dell'inglese: esistono due forme (singolare e plurale), il singolare si usa con il numero 1, il plurale con lo zero e in tutti gli altri casi. Nell'intestazione comparirà quindi l'espressione nplurals=2; plural=(n != 1); che significa: esistono due forme da utilizzare e il plurale va impiegato in tutti i casi in cui n!=1. Come illustrato in fig. 15, per ogni messaggio contenente un plurale ci saranno dunque due msgstr, uno marcato da [0] e l'altro da [1]: la scelta fra la prima e la seconda forma dipende dal calcolo effettuato di volta in volta sulla base della stringa contenuta nell'intestazione.
|
La situazione può diventare più complicata anche rimanendo all'interno delle lingue neolatine. In francese, ad esempio, pur esistendo due forme come in italiano, per lo zero si usa il singolare quindi nell'intestazione comparirà nplurals=2; plural=(n>1);. In romeno, dove per lo zero si usa il plurale, per l'1 il singolare, per i numeri da 2 a 19 il plurale, per i numeri da 20 a 100 il plurale preceduto dalla preposizione de, dal 101 al 119 il plurale senza alcuna preposizione, dal 120 al 200 nuovamente de, ecc. l'espressione è la seguente:
nplurals=3;
plural=(n==1 ? 0 : (n==0 || (n%100 > 0 && n%100 < 20)) ? 1 : 2);
Il valore di Plural-Forms nell'intestazione, in realtà, non è così importante per il traduttore. Utilizzando msginit o un editor dedicato, infatti, il campo verrà completato in modo automatico. In alternativa, è sempre possibile procurarsi un file PO precedentemente tradotto nella propria lingua e copiarne il contenuto.
Le implementazioni del formato PO
Il PO si è imposto con il passare del tempo come standard al punto da essere utilizzato in diversi ambiti. Si tratta, infatti, di un formato estremamente flessibile e di facile consultazione, nato per la localizzazione degli elementi dell'interfaccia grafica delle applicazioni (contenuti dinamici) ma in seguito adottato anche per la documentazione relativa al software (contenuti statici).
È possibile distinguere fra tre diverse macro-aree di applicazione di tale tipo di file [KDE Techbase Wiki, 2008]:
- come formato intermedio per traduzioni statiche, ovvero per contenuti di documentazione che vengono convertiti in PO e trasformati nel formato originale dopo la traduzione;
- come formato intermedio per traduzioni dinamiche, cioè per le interfacce di programmi che utilizzano formati personalizzati per le proprie stringhe, i quali vengono convertiti in PO e in seguito riportati al formato originale per essere caricati in fase di esecuzione (come i file .dtd e .properties della Mozilla application suite);
- come formato nativo per traduzioni dinamiche, per tutti quei programmi che usano direttamente il PO e che vengono caricati dopo la sola compilazione in MO.
Il fatto che un determinato file PO sia impiegato in contesti così vari comporta che al suo interno vi siano degli elementi diversi a seconda dell'uso che ne dovrà essere fatto. Nel caso 1 ad esempio, essendo la documentazione in un formato diverso dal PO (tipicamente HTML testo semplice o PDF) all'interno dei messaggi saranno presenti elementi di markup. Nei casi 2 e 3, invece, i PO vengono utilizzati per le interfacce grafiche e contengono alcuni tipi di elementi che assumono un significato particolare durante l'esecuzione del programma.
Documentazione di software
La documentazione del software comprende diverse componenti: esistono le guide in linea accessibili dall'ambiente desktop (come Yelp per le applicazioni GNOME e KHelpcenter per KDE) in formato DocBook, le pagine di manuale formattate attraverso lo strumento groff (GNU troff), le pagine GNU info in formato Texinfo, la documentazione ‘impaginata per la stampa’ scaricabile da internet prodotta ancora a partire da DocBook o, più raramente, LaTeX.
Sebbene alcuni gruppi lavorino direttamente sui sorgenti della documentazione, la pratica più diffusa prevede che i file siano convertiti in PO, per motivi simili a quelli visti relativamente al codice sorgente del software.
In tal modo si evita il rischio di modificare inavvertitamente il sorgente, si semplifica molto l'aggiornamento aprendo inoltre la via all'utilizzo di strumenti di traduzione assistita. Questi ultimi, a loro volta, permettono di assicurare la coerenza con le versioni precedenti del testo o con le altre pagine dello stesso progetto (preprocessando i file con msgmerge).41
Il DocBook è un linguaggio di markup basato su XML che deve la sua grande diffusione alla possibilità di utilizzare un unico formato per diverse modalità di visualizzazione (multi-mode rendering). Un unico file sorgente è quindi in grado di adattarsi a diversi supporti di consultazione (stampa su carta, online) per ottenere materiale in formato XHTML, RTF, testo semplice, PDF, PostScript e molti altri.
Il DocBook è un linguaggio descrittivo volto a rappresentare la struttura logico-formale e semantica del testo inserendo queste informazioni (structural markup) all'interno del testo stesso con una serie di tag. All'interno del sorgente comparirà pertanto una serie di istruzioni come <chapter>, <title>, <para>, ecc. Questi tag devono essere riprodotti invariati nella traduzione, dal momento che hanno un significato particolare per il processore che si occuperà di ‘tradurle’ in testo formattato.
|
Nell'esempio in fig. 16 si può osservare la presenza del tag <link> all'interno del messaggio che ha la particolarità di richiedere un attributo il cui nome, come i tag, non è interessato dalla traduzione. Dovendo essere il valore di tale attributo racchiuso da apici doppi, questi ultimi dovranno essere inseriti con la relativa sequenza di escape in modo da assicurare la validità del PO.
Il valore dell'attributo d'esempio ha poi la particolarità di contenere la chiave per un riferimento ipertestuale interno al manuale, ma in genere nemmeno i valori degli attributi vengono tradotti, quando non sono visibili all'utente finale.
Un'altra caratteristica tipica della documentazione in formato DocBook è la presenza delle entità e cioè delle macro per la sostituzione di determinate stringhe utilizzate, ad esempio, per rendere uniforme e abbreviare il modo in cui viene citato il nome di un'applicazione o di un tasto (fig. 17).
|
Traducendo la documentazione del SL è possibile da ultimo imbattersi anche in formati diversi dal DocBook, soprattutto per le pagine di manuale. In fig. 18, è stato riportato un esempio tratto dal manuale di debconf, lo strumento di configurazione interattiva dei pacchetti utilizzato in Debian GNU/Linux e nelle distribuzioni derivate. In questo caso gli sviluppatori hanno scelto di scrivere il manuale in POD (Plain Old Documentation, il formato della documentazione di Perl), dal momento che debconf stesso è sviluppato in Perl.
Le informazioni di markup quindi, e anche in questo caso si tratta di collegamenti ipertestuali, appaiono secondo la sintassi tipica del formato POD e cioè nella forma L<…>.
|
Interfaccia utente
I file di localizzazione dell'UI, sebbene in alcuni casi possano contenere anch'essi una sintassi di markup simile a HTML con tag di formattazione o entità (ad esempio nei tooltip o in determinate finestre di dialogo) hanno caratteristiche diverse.
In primo luogo possono contenere riferimenti alla situazione concreta in cui verranno mostrati all'utente finale che non possono essere determinati a priori. Tali elementi dovranno essere sostituiti in fase di esecuzione del programma con il contenuto appropriato e, in questo caso, il messaggio da tradurre conterrà dei placeholder.
All'interno del testo del messaggio questi ultimi possono apparire in diversi formati: in KDE, ad esempio, si presentano in forma di numeri (%1, %2) indipendentemente dal loro tipo (cfr. fig. 19, tratto ancora da Kate).
|
In altri casi invece, come nel progetto GNOME, appaiono come gli specificatori di formato utilizzati nel C/C++ con la funzione printf, per cui si troverà %s per le stringhe, %d oppure %i per i numeri interi decimali, e così via, come si può osservare nei messaggi tratti dal famoso client IRC multipiattaforma XChat riportati nell'esempio in fig. 20.
|
Dagli esempi 19 e 20 è possibile anche notare come prima di ogni messaggio contenente un placeholder compaia un nuovo flag che ne specifica il tipo. Questo genere di commenti (segnalati dai caratteri #,), in genere inseriti in modo automatico da xgettext salvo diverse istruzioni del programmatore,42 viene preso in considerazione da msgfmt che per ogni messaggio marcato da uno di questi flag controllerà la corrispondenza dei placeholder con l'originale garantendo così che non siano stati dimenticati o riportati in maniera errata.
Questo non significa però che tali elementi debbano essere riportati sempre letteralmente. Se un placeholder facente riferimento alla stessa entità compare più volte all'interno di un messaggio è possibile evitare la ripetizione, ad esempio con un pronome, procedimento auspicabile in molte lingue per rendere il testo più scorrevole.
L'omissione di un placeholder di numero è frequente, anche in inglese, quando tale numero compare nella forma singolare di un messaggio, ma questo non è possibile in lingua d'arrivo, ad esempio quando in base al calcolo delle forme plurali il caso con indice [0] viene utilizzato, oltre che per il singolare, anche con numeri diversi da 1.43
In determinati casi può essere necessario cambiare l'ordine dei placeholder nella traduzione, in modo che la frase rispetti la struttura sintattica o informazionale tipica della lingua d'arrivo. In progetti come KDE, dove sono numerati, questi sono univoci e quindi è possibile permutarne l'ordine senza problemi (v. fig. 21).
|
Dove viene usato il formato con le lettere, invece, quando sono presenti più placeholder dello stesso tipo e se ne vuole invertire l'ordine è necessario adottare una notazione che li renda univoci (v. fig. 22). La tecnica viene spiegata in questo caso dagli sviluppatori attraverso un commento estratto automaticamente.
|
Infine, i PO utilizzati nelle interfacce grafiche si caratterizzano per un'ultima peculiarità. Nelle barre e nel corpo dei menu, ma anche nei pulsanti di molte finestre di dialogo e in alcune caselle di spunta compaiono delle lettere sottolineate che permettono all'utente di ottenere lo stesso risultato di uno o più clic del mouse con la pressione del tasto Alt e della relativa lettera. Tali lettere, che prendono il nome di acceleratori, vengono rappresentate nei file PO attraverso dei marcatori speciali.
|
In GNOME per segnalare gli acceleratori viene utilizzato il carattere _ (v. fig. 23 con un esempio tratto ancora dall'UI di XChat) mentre nei programmi di KDE è adottato &. È necessario, quindi, non confondere il carattere di ‘e commerciale’ utilizzato per le entità con il marcatore degli acceleratori.
Inoltre, nei file PO dell'ambiente KDE, è possibile inserire un carattere & letteralmente inserendolo due volte, in modo simile a quanto avviene con la barra inversa nelle sequenze di escape (v. esempi in fig. 24).
|
Gli acceleratori rappresentano un'ulteriore sfida in fase di traduzione perché dev'essere evitata, nel limite del possibile, la creazione di conflitti fra combinazioni di tasti, soprattutto all'interno dello stesso menu. Qualora vi fossero acceleratori duplicati, infatti, questi potrebbero risultare inutilizzabili, funzionare in maniera non prevista o poco intuitiva.
Non è possibile concludere senza menzionare l'abbondante documentazione disponibile online riguardo il formato PO soprattutto riguardo gli aspetti di maggior interesse per i localizzatori messi in rilievo nelle due sottosezioni precedenti.
Oltre al già citato manuale di GNU Gettext, preziose informazioni si trovano in [Ferretti, 2004], relativamente al Translation Project (GNOME) e [KDE Techbase Wiki, 2008] per l'ambiente desktop KDE.
Le informazioni specifiche per ciascun progetto e le accortezze da osservare per le differenze nell'utilizzo del formato, cui qui è stato possibile fare solo un breve accenno, sono spiegate con dovizia di particolari e illustrati con ulteriori esempi, in modo da permettere anche ai nuovi arrivati di collaborare fin da subito senza difficoltà.
È da sottolineare a questo proposito che il PO, nonostante l'apparente complessità, nasce con lo scopo di semplificare la vita ai traduttori che non debbono necessariamente essere esperti programmatori per portare a termine il loro compito. Molti editor di PO permettono di gestire automaticamente (o quasi) gli aspetti più ‘tecnici’ del formato, come la compilazione dell'intestazione, l'inserimento dei plurali, l'impiego degli apici doppi come delimitatori e delle sequenze di escape.
Gli aspetti pratici dell'estrazione e dell'aggiornamento dei cataloghi dei messaggi, invece, spesso non sono nemmeno responsabilità del localizzatore, nonostante alcuni editor di file di risorse integrino funzionalità di gestione anche mediamente avanzata (cfr. 3.3.4 e 3.3.9).
Infine, l'utilizzo di tag ed entità, frequenti nella documentazione e in certe parti delle UI, non è molto diverso da ciò cui qualsiasi traduttore è abituato trovandosi a lavorare con testi formattati, specialmente se basati su XML. In sostanza i due unici aspetti ‘nuovi’ a cui è necessario prestare maggiore attenzione sono gli acceleratori e i placeholder in merito ai quali, però, la documentazione disponibile non manca.
2.4.3 Soluzioni complementari a Gettext
L'infrastruttura GNU Gettext è focalizzata sulla traduzione delle stringhe contenute nel codice sorgente dei programmi, vale a dire i messaggi che saranno presentati all'utente finale in fase di esecuzione. Il procedimento è ugualmente efficiente tanto che il programma sia dotato di interfaccia grafica, di interfaccia semi-grafica (ad es. basata sulla libreria ncurses) o di interfaccia a riga di comando.44
Il modello di GNU Gettext è senza dubbio vincente per i programmi scritti in C/C++, tuttavia non è sempre possibile applicarlo in maniera automatica a contesti in cui siano utilizzati linguaggi diversi. Da un lato sono stati sviluppati moduli che permettono l'estensione dell'infrastruttura come Locale::gettext per Perl o il modulo gettext per Python grazie ai quali, con le dovute modifiche al codice sorgente, si rende possibile la sostituzione delle stringhe in fase di esecuzione (e la marcatura delle stesse nel sorgente per l'estrazione e la creazione dei PO).
Esistono però dei programmi che adottano un sistema di internazionalizzazione diverso e sono pertanto caratterizzati da un proprio formato per i file di risorse e da un proprio sistema di referenziare i messaggi da tradurre nel codice sorgente collegandoli a tali file.
D'altra parte, se gli strumenti messi a disposizione da GNU Gettext hanno molti pregi dal punto di vista dello sviluppatore software, possono rivelare alcune carenze per i project manager o per i traduttori nel caso dei progetti di grandi dimensioni.
Un ulteriore limite di GNU Gettext, infine, è l'essere stato pensato appositamente per la traduzione delle interfacce grafiche di applicazioni e non per la relativa documentazione. Volendo gestire attraverso i file PO anche la documentazione di tale tipo di contenuti ‘statici’ si rendono necessarie soluzioni alternative.
Il Translate Toolkit
Nell'esigenza di risolvere parte di questi problemi è nato e si è sviluppato il Translate Toolkit (TTK). Nella forma più semplice, il TTK può essere definito come un insieme di strumenti sviluppati in Python (oltre ad alcuni script bash) volti a integrare le funzionalità di GNU Gettext, i cui più importanti rappresentanti sono riportati a continuazione.
È giusto precisare, però, che il TTK in realtà è anche molto di più, in quanto i vari componenti sono disponibili anche sotto forma di API (Application Programming Interface), cioè come un set di ‘funzioni’ che è possibile riutilizzare all'interno di nuove applicazioni per la localizzazione.
Gli strumenti del TTK possono essere quindi richiamati in modo dinamico all'interno di nuove applicazioni, per sfruttarne la potenza e la flessibilità senza bisogno di reinventare da zero i componenti. Al termine di questa sottosezione si tenterà di offrire una breve panoramica anche su alcune delle implementazioni del TTK.
L'insieme degli strumenti del TTK venne sviluppato inizialmente da D. Fraser per l'organizzazione no-profit sudafricana Translate.org.za.45
Tale organizzazione, ancora attiva nella localizzazione, aveva come proposito iniziale la localizzazione dell'ambiente grafico KDE nelle undici lingue ufficiali del Sudafrica. La traduzione dell'interfaccia utente di KDE, come si è detto, è basata sui PO e sull'infrastruttura Gettext per cui questo fu il modello iniziale di riferimento.
Quando il progetto si estese alla localizzazione dei prodotti come Mozilla Firefox e Mozilla Thunderbird, che facevano uso di formati diversi, vennero creati nuovi strumenti nell'esigenza di estendere il workflow basato su PO al nuovo contesto in modo da riutilizzare gli strumenti (allora KBabel), le competenze maturate e i vantaggi di questo formato. Una sintesi dei problemi di questa situazione può essere utile a rendere conto della filosofia che sta alla base di un progetto ambizioso come il TTK.
L'interfaccia grafica del browser Firefox e, più in generale, delle applicazioni della famiglia Mozilla, è realizzata attraverso XUL (XML User interface Language), un linguaggio basato su XML che permette la definizione degli oggetti contenuti nell'interfaccia principale e nelle finestre di dialogo (barre di menu, pulsanti, barre di avanzamento, ecc.) come elementi di una struttura gerarchica ad albero simile a quella di un documento HTML.
Le azioni derivanti dall'interazione con l'utente sono associate agli oggetti manipolabili dell'interfaccia mediante JavaScript. L'interfaccia viene quindi definita da una serie di file .xul contenenti l'XML vero e proprio e file .js contenenti JavaScript. Il concetto di applicazione basata sull'interfaccia XUL va quindi sfumando, per certi versi, verso quello di pagina web dinamica.
Per permettere la localizzazione di tali applicazioni, gli elementi traducibili vengono inseriti nel file .xul sotto forma di entità XML specificate in una DTD esterna, dove ogni entità corrisponde a una stringa di testo usata in una finestra (es. il titolo della finestra, il contenuto dei pulsanti o le scorciatoie da tastiera). Modificando il contenuto della DTD e rigenerando l'albero di struttura sulla base delle nuove entità è quindi possibile ottenere il cambiamento di lingua dell'applicazione mantenendo inalterato il codice principale. Per i file .js, invece, la parte localizzabile viene inserita all'interno di file .properties separati.
Alla luce di tale considerazione, è chiaro perché le componenti della Mozilla application suite, che si presentano in genere sotto forma di archivi Java .jar e sono situate all'interno della directory chiamata chrome del percorso di installazione, contengono all'interno della loro struttura almeno uno dei seguenti tre elementi: content (per l'interfaccia XUL e i file JavaScript associati), skin (per gli aspetti puramente esteriori, costituiti da immagini .png e fogli di stile a cascata), e una sottodirectory chiamata locale contenente i file .dtd e .properties distribuiti assieme all'estensione.
Il browser stesso, in quest'ottica, è concepito come un componente (browser.jar) costituito dalla directory content con i dati dell'interfaccia (file .xul) e le azioni ad essi associate (.js). Le impostazioni dell'aspetto fanno parte di un componente separato (ad es. classic.jar) e anche i language pack sono distribuiti separatamente come pacchetti contenenti la sola categoria locale. Il tutto viene integrato al momento dell'esecuzione grazie al motore XUL e JavaScript, in modo approssimativamente vicino a quanto avviene con l'associazione fra HTML e JavaScript per le pagine web.46
La diretta conseguenza di quanto detto è che la localizzazione di dei programmi Mozilla avviene modificando in maniera opportuna i relativi file .dtd e .properties. L'editor utilizzato a tale scopo agli inizi del TTK era un programma chiamato Mozilla Translator il quale da un lato non offriva tutte le funzionalità messe a disposizione da KBabel, l'editor PO utilizzato per la traduzione di KDE, e in secondo luogo non permetteva di sfruttare la conoscenza del mezzo (PO) e degli strumenti acquisita dal gruppo.
Il primo nucleo di strumenti del TTK è nato quindi allo scopo di fornire una serie di convertitori da e verso i file .dtd o .properties e il PO. Il vantaggio, oltre a non dover investire per sviluppare nuove competenze, era anche la possibilità di lavorare con file bilingui come i PO. Questo facilitava in modo significativo la revisione e l'aggiornamento in occasione dei nuovi rilasci del programma, perché non va dimenticato che un file PO può essere utilizzato come TM: ben oltre, quindi, il semplice principio della separazione delle stringhe!
I primi script di conversione sviluppati, la suite MozPOTools, permettono quindi di estrarre in maniera automatica le stringhe da localizzare convertendo i file .dtd e .properties in formati standard come PO e XLIFF. A questo primo nucleo di programmi si sono andati aggiungendo con il tempo diversi strumenti di verifica della qualità della traduzione (ad es. pofilter) o che rendono più facile l'inserimento delle correzioni (pomerge) e la valutazione del lavoro da fare (pocount). In un secondo momento, sono stati sviluppati anche dei convertitori per gestire la localizzazione di OpenOffice.org.
Anche la suite di produttività individuale di Oracle, infatti, ha i propri formati per i file di risorse. Le stringhe traducibili sono infatti contenute all'interno della directory dei sorgenti nei file .src/.hrc per quanto concerne l'interfaccia grafica, .ulf per il programma di installazione e in una serie di documenti XML (.xcu .xrm e .xhp), rispettivamente per la configurazione, le informazioni/licenza d'uso e per la guida in linea.
Questi elementi devono essere processati da uno script Perl fornito assieme agli stessi sorgenti (localize.pl), il quale produce un file in formato di scambio (.sdf) contenente il testo di tutti i messaggi e una serie di metadati (ad es. la posizione delle stringhe all'interno della directory dei sorgenti). Per evitare di intervenire direttamente su questo tipo di file di cui, peraltro, è molto facile compromettere senza volerlo la struttura formale, il TTK si è esteso fino a integrare delle utilità di conversione da .sdf a PO e viceversa.
Gli elementi traducibili possono essere estratti dal file .sdf per ricavare i modelli POT comuni alle varie lingue attraverso lo strumento oo2po del TTK. Dai modelli vengono poi ricavati i file per i singoli localization team, tipicamente attraverso pot2po (TTK) o msginit (Gettext) e, a traduzione ultimata, viene eseguito il ciclo di controlli e correzioni sui file PO attraverso pofilter e pomerge.
Infine viene generato un nuovo file .sdf sulla base del precedente (grazie al convertitore po2oo) ma contenente anche le nuove traduzioni.47 Per la verifica di errori formali nel file .sdf (eventuale cancellazione del messaggio in lingua di partenza, codifica caratteri inaccettabile, cancellazione di alcuni campi, ecc.) può rivelarsi necessario ricorrere a un ulteriore strumento esterno al TTK e a GNU Gettext, gsicheck, messo a disposizione dagli stessi sviluppatori di OpenOffice.
Gli strumenti oo2po e po2oo si affiancano quindi ai convertitori già esistenti per le traduzioni Mozilla e permettono di rendere più gestibile la traduzione dei componenti più diffusi e fondamentali nell'uso di computer in ambito desktop: un web browser, un client di posta elettronica e una suite di produttività individuale.
Alla luce di quanto visto finora, gli strumenti forniti dal TTK possono essere divisi in categorie a seconda del loro scopo.
Un primo gruppo è rappresentato dai convertitori, cioè quei programmi che permettono di trasformare i formati in uso nei vari progetti in PO/XLIFF per garantire il massimo della flessibilità e dell'interoperabilità (e viceversa). I principali componenti di questo tipo sono:
- i convertitori di file di risorse (come quelli già visti per Mozilla e OpenOffice), ma anche ini2po e rc2po utili a trasformare rispettivamente i file INI e RC normalmente utilizzati in ambiente Windows oppure ancora prop2po, specifico per i file .properties Java;
- i convertitori per le TM come po2tmx e po2wordfast;48
- le utilità di conversione fra formati di scambio bilingui, quali (csv2po, che permette di realizzare la traduzione anche senza un editor dedicato ma con un semplice foglio di calcolo o editor di testo e xliff2po, che permette di passare da PO a XLIFF e viceversa;
- gli strumenti per la creazione di file bilingui a partire da testi di origine in formato OpenDocument (odf2xliff), testo semplice (txt2po) o HTML (.html2po);
- un convertitore per banche dati terminologiche (csv2tbx) che, come dice il nome stesso, trasforma file comma separated in TBX;
- pot2po, il cui scopo è convertire un file POT in PO recuperando al tempo stesso le traduzioni già presenti in una TM (sotto forma di compendium PO oppure di TM) e permettendo di impostare anche una soglia di fuzzy matching personalizzata.
Un secondo gruppo è costituito invece dagli strumenti che permettono di manipolare i file PO oppure di crearne di nuovi estraendo determinate porzioni da quelli preesistenti. Rientrano in questa categoria:
- le utilità del ciclo di QA, vale a dire poconflicts (che individua i conflitti diretti e inversi all'interno di una directory contenente numerosi file PO), porestructure (il quale ri-organizza l'output di poconflicts in un albero di directory simile a quello dei sorgenti), pomerge (il cui compito è sostituire i file contenenti messaggi in conflitto reintegrando le correzioni del traduttore), pofilter (che esegue una serie di controlli sui messaggi al fine di verificare la qualità della traduzione) e infine pogrep (grazie al quale è possibile individuare facilmente i messaggi contenenti certe parole o espressioni regolari all'interno di directory molto grandi);49
- posegment, che permette di dividere le coppie di messaggi contenute in un PO riducendole all'ampiezza di una singola frase, in modo da permettere di utilizzare il PO come memoria di traduzione;
- pocompendium, attraverso il quale molti PO possono essere riuniti in un unico file da utilizzare come compendium o convertire in TMX per essere impiegato in ambienti di traduzione diversi;
- poswap, utilizzato per ottenere da un PO un nuovo file in cui la lingua di partenza sia la lingua d'arrivo del precedente, se questo può essere utile ai fini della traduzione;50
- pocommentclean, grazie al quale è possibile rimuovere in maniera automatica tutti i commenti del traduttore da un file PO;
- poterminology, che permette di estrarre un file di terminologia, e cioè un PO contenente i candidati termini, a partire da uno o più file PO (bilingui) o POT (monolingui) sulla base della loro frequenza.
Esiste infine un terzo gruppo di strumenti utili a monitorare l'andamento del lavoro e ripartirlo fra i membri del gruppo di localizzazione, fra i quali vale la pena citare posplit, uno script bash che permette di dividere un file PO nelle sue tre componenti fondamentali (messaggi tradotti, messaggi fuzzy e non tradotti) e pocount che permette di effettuare in maniera automatica una valutazione statistica del lavoro svolto e del lavoro da fare calcolando i messaggi contenuti anche ricorsivamente all'interno di una directory.
Appare abbastanza evidente che è possibile tracciare un parallelismo fra molte delle utilità del TTK e quelle offerte da GNU Gettext: a msgmerge può essere associato pomerge, msggrep è l'equivalente di pogrep, msgfilter somiglia a pofilter, e così via. Tuttavia, a dispetto delle somiglianze nominali, vi sono importanti differenze fra le due serie di programmi. Ad esempio, msgfmt e pocompile sono entrambi responsabili della compilazione in formato MO, ma il primo accetta come input solo file PO, il secondo sia PO che XLIFF.
Dal punto di vista concettuale, pot2po corrisponde a msginit perché entrambi hanno la funzione di generare il PO a partire dal file modello. Questo non è del tutto vero, però, in quanto il secondo svolge solo una parte delle funzionalità del primo. Infatti pot2po può essere utilizzato in associazione con una TM (in formato PO o TMX) per il riconoscimento automatico dei fuzzy match (in maniera simile a quanto fa msgmerge con i compendia) e permette di configurare una soglia di match personalizzata. Il TTK mette a disposizione, inoltre, uno script chiamato pomigrate2 che rende ancor più automatizzata la procedura per un coordinatore che deve smistare il lavoro fra più team linguistici e si trova a gestire grandi quantità di file in più cartelle.
Per quanto riguarda, infine, gli strumenti di unione di PO, pomerge a differenza di msgmerge non è nato per gli aggiornamenti quanto piuttosto per apportare le correzioni durante il ciclo di QA. Tale comando accetta come input e output anche un intero albero di directory ed è in grado di sovrascrivere le correzioni dove a percorso uguale corrisponde file uguale fra le due cartelle.
Dal momento che, per esigenze di spazio e di tempo, trattare in maniera esaustiva il TTK in questo lavoro sarebbe impossibile, per ulteriori approfondimenti si rimanda al sito internet del progetto e alla gran quantità di documentazione disponibile online. Gli strumenti del TTK particolarmente interessanti perché in grado di intervenire in più parti del workflow di traduzione con le conversioni saranno accennati nel cap. 3 mentre i programmi del TTK utili per l'amministrazione e l'elaborazione di TM e TB saranno presentati nel cap. 4.
Progetti basati sul Translate Toolkit Il TTK, grazie alle API messe a disposizione dagli sviluppatori, può essere integrato in maniera modulare all'interno di nuove applicazioni per la localizzazione. Nel corso del tempo grazie al TTK sono andati nascendo nuovi progetti e nuovi software, tanto ad opera di Translate.org.za quanto di terze parti.
Queste implementazioni del TTK possono essere divise in due categorie: da un lato i programmi stand-alone corrispondenti all'idea più ‘tradizionale’ di TEnT (Translation Environment Tool), dall'altro applicazioni web-based orientate a fornire tutto il necessario per la gestione di progetti collaborativi anche di grandi dimensioni. Due esempi della prima categoria di applicazioni sono Virtaal e Wordforge (per cui si rimanda rispettivamente alle sezioni 3.3.5 e 3.3.7) mentre alcuni esempi del secondo approccio sono Pootle o Rosetta.
Pootle, creato da David Fraser per Translate.org.za, nasce come strumento di traduzione online basato sul TTK. Si tratta di una piattaforma realizzata in Python che ha lo scopo di facilitare e di coordinare il lavoro dei traduttori di SL, principalmente nell'ambito delle interfacce grafiche. Uno dei più celebri casi di utilizzo di tale sistema è rappresentato dalla localizzazione di OpenOffice.org.
La piattaforma Pootle (PO-based Online Translation/Localization Engine) è dotata di numerosissime funzioni e supporta tutti i formati di file che possono essere elaborati con il TTK: dai .dtd e .properties di Mozilla al .sdf di OpenOffice, dagli standard LISA (TMX e TBX) ai file di scambio bilingui XLIFF e PO.
Oltre alle utilità di conversione, manipolazione e QA offerti dal TTK (46 controlli specifici per la lingua e il tipo di file tramite pofilter), Pootle integra funzionalità di ricerca nei messaggi e di project management permettendo l'assegnazione di compiti e permessi ai membri registrati e di monitorare il lavoro svolto attraverso milestones e visualizzare il lavoro ancora da fare in ogni directory attraverso grafici di immediata comprensione.
Se opportunamente configurato, Pootle può anche interagire direttamente con i sistemi di controllo versione di software (come CVS, Subversion o Git) in modo da depositare direttamente upstream agli sviluppatori i file contenenti la localizzazione, gli aggiornamenti e quant'altro senza ulteriori passaggi intermedi.
Tuttavia, l'aspetto più importante ai fini di questo lavoro è l'editor di traduzione online integrato in Pootle. Infatti i traduttori di un progetto che utilizzi un server Pootle in genere possono sia scaricare i file PO/XLIFF loro assegnati per lavorare off-line quanto lavorare online attraverso l'interfaccia web. Anche lavorando con l'editor online sono disponibili le funzionalità di riconoscimento della terminologia, TM51 e di traduzione automatica, su richiesta dell'utente.
Inoltre, traducendo in formato PO, sono visibili i commenti estratti automaticamente, i riferimenti al sorgente e i commenti del traduttore (modificabili) e i contesti di disambiguazione. Per facilitare il lavoro del traduttore l'editor supporta l'evidenziazione della sintassi (ad es. segnalando i tag XML con un colore diverso) e la possibilità di inserire le voci di glossario semplicemente con un clic.
L'interfaccia dell'editor online di Pootle è a sua volta disponibile in numerose lingue locali e gestisce correttamente l'inserimento di caratteri in entrambe le direzioni per le lingue bidirezionali. Nel caso in cui il traduttore non avesse a disposizione la tastiera della propria lingua o non potesse modificarne la disposizione, l'editor contiene una serie di pulsanti per inserire (a seconda della lingua in questione) i caratteri contenenti i segni diacritici necessari.
Quest'ultima caratteristica si deve al fatto che l'interfaccia web di Pootle è pensata per permettere ai traduttori di dedicarsi alla propria attività in qualsiasi posto, anche lontano dalla consueta postazione di lavoro, e da una qualsiasi macchina dotata di connessione a internet e di un web browser, indipendentemente dal sistema operativo utilizzato e senza bisogno di installare software in locale né di portare con sé i dati (glossari, file di progetto, TM) su alcun supporto ‘fisico’ ricreando però un ambiente simile a quello dei TEnT tradizionali (cfr. 3.3).
La finalità di un simile approccio è rendere la localizzazione del SL quanto più accessibile, perché così come lo sviluppo di questi progetti è basato sul contributo volontario di chiunque sia dotato della volontà e delle adeguate capacità, così pure la traduzione intende essere ‘aperta’ a tutti coloro che sono in grado di aiutare e ne manifestano la volontà.
A questo proposito, in Pootle può anche essere implementata la modalità ‘a suggerimenti’, che permette agli utenti di lasciare dei suggerimenti di traduzione da sottoporre alla successiva approvazione di un revisore o dell'amministratore. In tal modo si permette anche a soggetti esterni al team di localizzazione di partecipare attivamente allo sviluppo e di segnalare eventuali sviste, in modo simile a quanto avviene per la segnalazione e correzione di bug nel codice del SL.
Abilitare i suggerimenti è inoltre un modo per accettare contributi da terzi senza dare necessariamente a questi ultimi la possibilità di intervenire sui messaggi contenuti nei file: Pootle permette infatti di assegnare livelli di privilegi diversi agli utenti non registrati e agli utenti registrati e, anche fra questi ultimi, di consentire determinate azioni (adattando l'interfaccia stessa) a seconda del livello gerarchico di privilegi di ciascuno.
Rosetta, lo strumento utilizzato per la localizzazione della distribuzione GNU/Linux Ubuntu, ha molti aspetti in comune con quanto finora detto a proposito di Pootle. Tale utilità, anch'essa basata in parte sul TTK, è integrata nella piattaforma Launchpad di Canonical Ltd. (la stessa società che finanzia e promuove lo sviluppo di Ubuntu) diventata open source nel 2009. Su Rosetta, gli aspiranti traduttori possono registrarsi e contribuire lasciando suggerimenti relativi ai moduli che necessitano di traduzione.
È evidente che in tal modo Ubuntu è in grado di sfruttare il potenziale derivante dal fatto di essere una delle distribuzioni GNU/Linux più diffuse in ambito desktop. Il modello è molto vicino quindi al crowdsourcing: è la comunità stessa degli utenti a farsi responsabile di localizzare il proprio sistema operativo e le sue componenti. Il vantaggio di questo approccio sta nel grande numero di potenziali collaboratori, considerato il vasto bacino d'utenza di Ubuntu: potenzialmente chiunque, con il solo requisito di essersi registrato su Launchpad, può lasciare suggerimenti che saranno in seguito valutati dai traduttori ‘approvati’ della comunità.
Al contempo, lo svantaggio deriva dal problema di gestire l'alto numero di suggerimenti, di assicurare la coerenza a fronte di un team molto esteso per una sola lingua e di mantenere un alto livello di qualità. Per questo motivo, pur essendo in teoria possibile per tutti gli utenti lasciare suggerimenti, tale pratica è fortemente sconsigliata e prima di prendere iniziative è necessario contattare i coordinatori, prendere in carico ‘individualmente’ la traduzione e procedere solo una volta ricevuta l'autorizzazione in questo senso. Il processo di revisione, invece, torna ad essere collaborativo dal momento che tutta la comunità è invitata a partecipare in modo attivo.
La suite PO4A
Trasferire l'ideale ‘catena di montaggio’ dei file PO anche agli aspetti statici della localizzazione comporta numerosi vantaggi. Inoltre alcune componenti, come le guide in linea, sono spesso installate assieme alle applicazioni, per cui è anche logico che la loro localizzazione segua un ciclo di sviluppo simile a quello dell'applicazione. Il problema è che l'ambito della documentazione esula dalle finalità per cui è stato progettato GNU Gettext, motivo per cui si è resa necessaria la creazione di strumenti ‘complementari’.
Il progetto PO4A (PO for Anything) ha appunto lo scopo di sfruttare al massimo gli strumenti di GNU Gettext anche nell'ambito della documentazione di software, trasformando i vari formati in uso in un unico formato di scambio per la localizzazione, il PO, in modo da rendere meno problematico l'aggiornamento dei manuali e il mantenimento di progetti di localizzazione durante il ciclo di vita del programma.
Il rationale alla base di PO4A è la convinzione che disporre della traduzione di un manuale aggiornata sia altrettanto importante quanto la localizzazione del programma stesso. Affinché infatti un utente non di madrelingua inglese possa godere appieno del diritto di utilizzare il software nella propria lingua (idea alla base del Native Language Support) è necessario che anche la relativa documentazione sia disponibile in versione localizzata.
PO4A è in grado di gestire i formati più utilizzati per la documentazione del SL: man (pagine di manuale Unix), POD, SGML, TeX, LaTeX, Texinfo e XML. Il funzionamento di PO4A è per certi versi simile a quanto visto per la localizzazione delle applicazioni: gli elementi traducibili vengono estratti dal sorgente del documento in un formato intermedio (PO) da sottoporre ai localizzatori per il lavoro di traduzione.52
PO4A è una suite costituita da un insieme di script Perl. Il primo, po4a-gettextize, permette di generare un file POT a partire dal documento sorgente, oppure di ottenere il PO specifico per una determinata combinazione linguistica avendo a disposizione sia l'originale che una traduzione preesistente. Il ruolo di questo script è molto vicino a quello di un allineatore inteso in senso tradizionale e il PO così prodotto può essere visto come una TM pronta per essere implementata in occasione dei futuri aggiornamenti.
La funzionalità di allineamento, su cui si tornerà nella sezione 3.2.4, si basa principalmente sul fatto che a riga uguale nei due documenti corrisponda segmento uguale, per cui la struttura dei file deve essere perfettamente sovrapponibile. Qualora non lo fosse, è necessario intervenire a mano con le modifiche del caso. Lo script può essere d'aiuto anche in questo senso, perché nel caso in cui la struttura dei file non coincida (ad es. non hanno lo stesso numero di righe), il programma restituisce un messaggio d'errore e informa l'utente sulla natura dei problemi riscontrati.
Nel momento in cui viene rilasciata una nuova versione dell'originale, può essere utilizzato lo script po4a-updatepo per fare in modo che i cambiamenti siano rispecchiati anche nei messaggi all'interno file PO. Tale strumento, a sua volta, invoca l'utilità msgmerge di GNU Gettext per eseguire l'aggiornamento e, se specificato attraverso la relativa l'opzione (-previous), permette di recuperare anche i precedenti campi msgid dei messaggi fuzzy.
A traduzione ultimata, il documento d'arrivo viene generato attraverso lo strumento po4a-translate sulla base dell'originale e del file PO tradotto. Nel caso in cui fosse necessario aggiungere del testo nel documento d'arrivo, ad es. il nome del traduttore o dei traduttori oppure informazioni sul documento, è possibile farlo scrivendo un file addendum da specificare come ulteriore argomento al comando contenente le informazioni necessarie (le stringhe da inserire e il punto di inserimento specificato attraverso espressioni regolari).
PO4A è fornito anche di un'utilità di debug e, ultimo ma non meno importante, comprende uno strumento in grado di automatizzare tutte le precedenti operazioni (eccetto l'allineamento) con un solo comando, po4a.
Se configurato in modo corretto, po4a permette di svolgere in maniera autonoma il ciclo di localizzazione: sincronizza il file POT con il nuovo documento originale e aggiorna le traduzioni qualora i file PO delle singole lingue fossero stati modificati.
Il programma è in grado di gestire contemporaneamente più lingue, più originali anche in formati diversi (es. man e POD), ciascuno con le sue relative opzioni (es. la soglia per i fuzzy match) e con gli addenda per ogni lingua.53
La gran quantità di lavoro iniziale dovuta, ad esempio, all'allineamento e alla stesura del file di configurazione di po4a viene ripagata a detta degli sviluppatori con la facilità di gestione dei progetti di localizzazione, anche complessi, in occasione di tutti gli aggiornamenti dei documenti.
Nell'intenzione degli autori, Nicolas François e Martin Quinson (entrambi sviluppatori Debian), grazie a PO4A è possibile colmare il divario fra le versioni dei programmi nelle varie lingue locali e la versione della documentazione.
I primi sono in genere aggiornati frequentemente grazie all'eccellente supporto dell'infrastruttura GNU Gettext, mentre la documentazione in versione localizzata è spesso obsoleta a causa delle difficoltà di ordine ‘pratico’ dell'aggiornamento delle traduzioni più che della maggior quantità di parole da tradurre in proporzione nel manuale rispetto all'interfaccia dell'applicazione.
Considerazioni finali
In conclusione si ritiene che la presentazione, per quanto sommaria, dell'infrastruttura GNU Gettext sia un buon esempio sia delle logiche che stanno alla base dell'internazionalizzazione e della localizzazione di software che di come si sviluppano le soluzioni nell'ambito del SL.
Al contempo, la descrizione di questo modello ha reso possibile spaziare anche dal punto di vista cronologico dagli esordi dell'internazionalizzazione con la marcatura dei sorgenti in uno dei più ‘antichi’ linguaggi di programmazione fino alle soluzioni di stampo web 2.0 per la traduzione assistita dei giorni nostri.
Naturalmente, molto potrebbe essere ancora detto sia riguardo la localizzazione di SL (ad es. sulle piattaforme online come Rosetta e Transifex)54 che riguardo la possibilità di applicare gli strumenti liberi alla localizzazione di software non libero, ad esempio grazie ad alcuni convertitori del TTK (rc2po) con cui è possibile ottenere PO a partire dai file di risorse (.rc) più utilizzati in ambiente Windows.
Non essendo possibile trattare la questione nella sua interezza, tuttavia, in questo lavoro si è scelto di concentrare l'attenzione sul solo ambito ‘libero’ e sui soli strumenti utilizzabili ‘in locale’ in maniera simile ai programmi di traduzione assistita tradizionali, accennando soltanto alle piattaforme collaborative e alla localizzazione di software non libero.
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/