4.3 Gestione delle memorie
4.3.1 TMXCleaner e TMXMerger
| Autore: | Henry Pijffers |
| Licenza: | GNU GPLv2 |
| Pagina web: | http://www.omegat.org/it/resources.html |
| Versione: | 1.0 (novembre 2009) |
TMXCleaner e TMXMerger sono due applicazioni Java sviluppate in origine per essere affiancate a OmegaT per rendere più facile la manutenzione delle risorse di traduzione. Quest'ultimo programma infatti non immagazzina tutti i segmenti tradotti in una base di dati unica ma tende piuttosto a mantenere separate le TM di ciascun progetto. Quel che ne consegue è un grande vantaggio in termini di modularità, in quanto è possibile decidere di volta in volta quali TM andranno a costituire la base di dati per ciascun nuovo incarico di traduzione.
Alla lunga, però, si rischia di produrre un numero considerevole di memorie di piccole dimensioni sparse fra le cartelle di progetto e scollegate le une dalle altre, che potrebbero contenere ripetizioni o, peggio, incongruenze, ossia l'esatto opposto di quel che dovrebbe assicurare l'impiego della tecnologia TM.
Le due applicazioni sono disponibili come archivio Java e quindi possono essere eseguite su qualsiasi piattaforma dove sia presente un JRE. Si tratta in entrambi i casi di strumenti a riga di comando che svolgono il loro compito in maniera non interattiva: vengono lanciati da riga di comando e accettano una serie di argomenti e opzioni che permettono di indicare i file da modificare e, eventualmente, alcune opzioni aggiuntive. Le informazioni sull'utilizzo in ogni caso sono scaricabili assieme ai sorgenti oppure possono essere richiamate lanciando i programmi con l'opzione -help oppure -usage e sono disponibili soltanto in in lingua inglese. Infine, entrambi i programmi operano in ingresso su file TMX e restituiscono file TMX in uscita.
TMXCleaner, in particolare, accetta come argomento la sola TM che deve essere ripulita, e produce come output una nuova memoria rinominata con l'aggiunta del suffisso -clean. Tutte le TU eventualmente ripetute nella memoria di partenza compariranno una sola volta mentre verranno eliminate tutte quelle in cui sia presente solo uno dei due segmenti (solo l'originale senza la traduzione o viceversa) e quelle in cui il segmento di partenza e quello d'arrivo sono identici.
Quest'ultima è un'eventualità non così infrequente dal momento che in OmegaT la distinzione fra file di progetto bilingui (PO o XLIFF in altri ambienti di traduzione) e le TM è molto sfumata: entrambi sono in formato TMX e i primi possono svolgere la funzione delle seconde nei lavori futuri (cfr. sez. 3.3.1). Tutti i casi in cui il un segmento sia stato copiato dall'originale alla traduzione (es. se contiene immagini, elementi di markup, ecc.) vengono quindi salvati nella TM e rischiano di farne aumentare le dimensioni senza motivo oltre che produrre fuzzy match inutili.
TMXMerger, invece, ha la funzione di riunire più file TMX in un un'unica memoria di grandi dimensioni: accetta come argomenti i nomi dei file che devono essere uniti (necessariamente più di uno) e il nome della memoria finale da generare.
Va sottolineato che il programma è molto efficiente e svolge in parte anche i compiti di ‘pulizia’: le TU eventualmente contenute in più memorie fra quelle unite compaiono infatti una sola volta in quella finale. Per gli eventuali segmenti ‘orfani’ conviene invece eseguire TMXCleaner sui file di partenza prima di unire le TM oppure sulla memoria finale in quanto essi non vengono eliminati in fase di fusione.
In via opzionale è possibile specificare prima degli argomenti l'opzione source=LL(-CC) in modo da stabilire la lingua di partenza che verrà utilizzata nella memoria finale; lanciando lo script senza alcuna opzione la lingua predefinita della memoria generata sarà invece la lingua di partenza della prima TM passata come argomento.
Unendo fra loro TM dove le lingue sono invertite si ottiene una TM unica in cui la direzione linguistica è data dal valore dell'attributo srclang nell'intestazione del TMX, indipendentemente dall'ordine in cui compaiono le varianti (cioè gli elementi <tuv>) all'interno delle TU.
Infine va segnalato che se si uniscono più TM aventi la stessa lingua di partenza ma diverse lingue di arrivo, si ottiene ancora una TM avente come lingua di partenza la lingua di partenza dei file di origine, in cui le TU contengono due varianti qualora i segmenti fossero presenti solo in uno dei file originari oppure (se il segmento di partenza è comune alle varie memorie) tre o più varianti, segnalate da un elemento del tipo <prop type="x-merge-mt">true</prop>, il che si rivela molto utile quando si debbano gestire progetti che comprendono più lingue e si desideri unificare tutte le memorie per futuri riferimenti.167
Volendo formulare un giudizio complessivo i due programmi, per quanto semplici, sono perfettamente funzionali allo scopo per cui sono stati progettati e semplificano molto il lavoro del traduttore nell'uso quotidiano di OmegaT.
Nonostante si tratti di utilità eseguibili solo in modalità testuale, sono di utilizzo molto semplice e la documentazione, disponibile in inglese assieme ai sorgenti, è sintetica ma esaustiva. Altro aspetto da non sottovalutare è che a prescindere dalle intenzioni originarie degli sviluppatori questi strumenti possono essere utilizzati con le memorie prodotte da qualsiasi strumento di traduzione assistita, in virtù dello standard aperto TMX.
4.3.2 TMXValidator
| Autori: | Rodolfo M. Raya et al. |
| Licenza: | EPL168 |
| Pagina web: | http://www.maxprograms.com/products/tmxvalidator.html |
| Versione: | 1.0-6 (agosto 2008) |
Il programma è sviluppato dalla casa produttrice di software Maxprograms come parte di Swordfish II, una suite di traduzione assistita (proprietaria) scritta in Java, cross-platform e interamente basata sugli standard aperti dell'industria dei LSP. I programmi principali, come l'editor/strumento CAT, l'allineatore o l'applicazione di gestione della terminologia, sono purtroppo closed source e disponibili solo in versione dimostrativa.
Tuttavia alcuni programmi ‘accessori’ di questa collezione di software sono scaricabili a parte e sono rilasciati con una licenza libera come la EPL: un'utilità di validazione delle TM, un editor di regole di segmentazione, uno strumento per facilitare la localizzazione di programmi Java, e così via. In particolare, fra questi applicativi può essere interessante considerare TMXValidator, utile per verificare la validità delle memorie in formato TMX.
Quest'ultimo, in quanto formato di scambio, è utilizzato da più programmi di traduzione assistita che ne fanno usi potenzialmente diversi. Non è infatti detto che tutte le TM siano valide così come prodotte dal programma e un file non valido non verrà riconosciuto correttamente da applicazioni di terze parti, venendo così a inficiare la possibilità di scambio e di indipendenza dai singoli produttori per cui il formato TMX è stato creato. È questo il motivo per cui si sono resi necessari degli strumenti di validazione come TMXValidator.
L'applicazione può essere scaricata sia in formato di installatore binario sia come sorgenti che, essendo in Java, possono essere eseguiti direttamente a patto che sul sistema in uso sia installato un JDK. I sorgenti inoltre sono corredati da una serie di script bash per renderne l'esecuzione quanto più facile su qualsiasi piattaforma. In quanto a facilità d'uso il programma è anche dotato di una semplice e intuitiva interfaccia grafica localizzata in numerose lingue (anche se non in italiano).
La verifica delle TM è basata sulla conformità dei documenti alle regole di validità imposte dallo standard TMX e codificate nelle DTD realizzate dalla LISA.169 Il programma è già fornito al momento dell'installazione delle DTD per le versioni più recenti dello standard TMX (vale a dire 1.1, 1.2, 1.3 e 1.4) in modo da essere compatibile con i formati di TM più diffusi. È possibile controllare la versione dello standard TMX cui aderisce un documento verificando il valore dell'attributo version contenuto all'interno dell'elemento radice <tmx>.
TMXValidator accetta in ingresso memorie esclusivamente in formato TMX ed è dotato di un'interfaccia grafica per caricare i file di partenza e controllare lo svolgimento delle operazioni che sono essenzialmente due: la validazione della TM e l'eliminazione dei caratteri non validi. Queste due azioni sono riproposte negli unici due pulsanti che corredano l'interfaccia, la cui parte principale è un'area di testo in cui vengono visualizzati i messaggi destinati all'utente (errori o messaggi di stato).
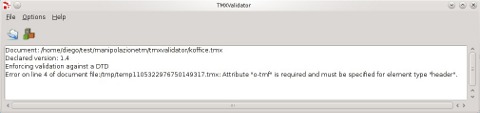 |
Alcuni fra gli errori più comuni riconosciuti correttamente dal programma sono: la mancanza di attributi obbligatori o la presenza all'interno degli elementi di attributi diversi da quelli specificati o sovrabbondanti; la presenza di elementi di natura, numero o posizione diversi da quanto consentito nelle specifiche della DTD e, infine, errori nell'annidamento degli elementi quando non viene rispettato il vincolo di well-formedness. Viene rilevata anche la presenza di caratteri non consentiti come le parentesi angolari e il simbolo di ‘e commerciale’ (al di fuori delle entità XML) all'interno degli elementi e, all'interno dei valori delle attributi, anche la presenza di apici singoli e doppi.
In caso di mancato superamento del test di validità, il programma non interviene direttamente sulla TM ma si limita a mostrare a schermo una breve descrizione della natura dell'errore e il numero di riga in cui si è verificato lasciando all'utente il compito di intervenire manualmente sul documento con un'applicazione esterna. È da segnalare tuttavia che, se un documento contiene più di un errore di sintassi, TMXValidator si limita a segnalare il primo perché al verificarsi di un errore il processo di validazione si interrompe: gli eventuali errori successivi devono essere rilevati eseguendo più volte il programma.
Oltre alla validazione il programma permette anche, in via opzionale, di ripulire la memoria dai caratteri non validi per l'XML: alcuni strumenti di traduzione assistita potrebbero infatti inserire caratteri di controllo all'interno delle TM (come, ad esempio, ^N, ^H, ecc.). Anche in questo caso la modifica non è interattiva: il file viene modificato senza richiedere conferma né segnalare l'entità delle modifiche apportate, ma ne viene salvata una copia di ripristino con un nome modificato.170
Per concludere, TMXValidator è funzionale e di facile utilizzo grazie soprattutto alla sua interfaccia grafica. I problemi principali sono rappresentati dai messaggi di stato che si limitano a mostrare il numero di riga e una descrizione dell'errore un po' criptica per chi non abbia dimestichezza con la grammatica delle DTD e dal fatto che il programma riconosce solo un errore per volta (comportamento spiegabile in base al fatto che gravi errori di sintassi potrebbero rendere impossibile il parsing dell'albero XML nel seguito del documento).
Un ulteriore difetto è che la documentazione è al momento praticamente inesistente, al contrario di quanto accade per i programmi non liberi di Maxprograms che invece sono ben pubblicizzati e documentati.
Un'alternativa al programma TMXValidator è stata sviluppata da Raymond Martin nel tentativo di creare una suite di programmi completa per la traduzione assistita attraverso SL. L'idea alla base del progetto era una più stretta integrazione fra una versione modificata di OmegaT chiamata ‘OmegaT Plus’, un allineatore (Bitext2tmx) e uno strumento di validazione delle TM chiamato appunto ‘Validator’.
Tuttavia così come la versione modificata dello strumento CAT non si distacca che nominalmente dal progetto originale senza apportare nulla di innovativo, anche ‘Validator’ si configura come un fork fine a se stesso e non aggiunge niente al programma cui si ispira se non un tema grafico leggermente diverso e più coerente con ‘OmegaT Plus’ (cioè il toolkit grafico Swing).
Le funzionalità offerte invece, ma anche la stessa interfaccia, non si differenziano in nulla e per nulla dall'originale, così come i problemi di licenza e la quasi totale assenza di documentazione. Per tale motivo si è deciso di non dedicare una trattazione separata a quest'alternativa. Una delle poche differenze introdotte da Martin è la possibilità di eseguire il programma sia in modalità grafica che in modalità testuale, in modo da permetterne l'utilizzo con script creati dall'utente. Tenendo però conto che, come si vedrà nella sez. 4.3.4, esistono altri strumenti da riga di comando molto più flessibili e potenti anche questa ‘innovazione’ diviene trascurabile.
4.3.3 Translate Toolkit per le memorie
Come già visto, alcuni componenti del TTK permettono di operare sulle memorie, crearne di nuove, modificarle e consultarle [Murray, 2009]. Il TTK fornisce però in massima parte strumenti per la localizzazione di software, dove il formato preferito per le memorie di traduzione è il PO (cfr. sec:postrutt). Va ricordato che in quanto formato bilingue il PO viene utilizzato tanto come memoria di traduzione quanto come documento di lavoro finalizzato al testo d'arrivo: in questa sezione ci si occuperà esclusivamente dei programmi adatti a manipolare file PO come memorie di traduzione.
Un primo esempio è pocompendium che accetta in ingresso una serie di file PO o, in alternativa, una directory contenente una serie di file PO e produce un file PO unico. Dal punto di vista concettuale il programma svolge una funzione molto simile a TMXMerger dal momento che permette permette di riunire le traduzioni svolte in precedenza in un'unica memoria, utile ad esempio alla fine di un progetto per controllare il lavoro effettuato o il leveraging delle TU nei futuri lavori.
Lo strumento è inoltre in grado di svolgere alcune delle funzioni di base di modifica delle TM come, ad esempio, invertire la direzione linguistica (attraverso l'opzione -invert), preparare le memorie in modo da essere sfruttate come riferimento per nuovi progetti nonché permettere l'interrogazione di più memorie allo stesso tempo.
A questo proposito, ad esempio, è molto utile la possibilità di rimuovere gli acceleratori che potrebbero abbassare il livello di corrispondenza nelle statistiche di confronto fra segmenti se si intende utilizzare un file PO come TM in consultazione.
Quest'ultima funzionalità, più che ‘interrogare’ le TM, intende fornire uno strumento utile per scopi diagnostici. Utilizzando pocompendium con l'opzione -errors è possibile infatti estrarre da più file PO o da una directory contenente file PO tutti i messaggi contenenti ‘errori’, dove cioè una stessa stringa è associata a più traduzioni diverse. Laddove la stringa coincida con una singola parola, caso non infrequente quando si lavora sulla localizzazione di interfacce grafiche, la procedura permette di individuare facilmente gli eventuali usi incoerenti della terminologia. Combinando invece le opzione -invert e -errors è possibile trovare i casi in cui due stringhe diverse sono state tradotte nello stesso modo in modo da adottare eventuali soluzioni correttive volte per eliminare il conflitto.171
Il TTK comprende altri due strumenti per la manipolazione delle TM già citati all'interno della categoria delle utilità di conversione nella sezione 2.4.3. Attraverso il TTK questa operazione avviene in modalità non interattiva e gli unici metadati che possono essere modificati riguardano la specificazione delle lingue e della direzione linguistica. In particolare le utilità in questione sono po2wordfast e po2tmx che trasformano le memorie in formato PO, rispettivamente, nel formato TXT di Wordfast e in TMX. La trasformazione inversa, cioè da TMX a PO, non è ancora supportata dal TTK ma può essere realizzata facilmente con gli strumenti dell'infrastruttura Okapi (cfr. sez. 4.4).
In conclusione, gli strumenti del TTK per la manipolazione delle TM svolgono in modo molto efficiente il compito per cui sono stati progettati, sono leggeri in termini di risorse di sistema e, una volta compresone il funzionamento, si dimostrano di grande utilità. La documentazione è esaustiva e corredata da numerosi esempi sia nelle pagine di manuale (ancora non localizzate in italiano) sia in internet sulla pagina web del progetto. Nonostante si tratti di strumenti rivolti più ai coordinatori di progetti di localizzazione di medie e grandi dimensioni che ai singoli traduttori, il loro utilizzo è alla portata dell'utente medio così come l'installazione.
4.3.4 Strumenti generici per controllo formale e statistiche
Grazie alla loro natura di documenti XML-compliant i TMX si prestano a essere analizzati anche con strumenti più semplici ma non per questo meno potenti adatti alla verifica dei documenti XML generici.
A questo proposito una prima utilità è xmllint, che fa parte di una serie di strumenti e per il parsing e la manipolazione di documenti XML conosciuta come libxml. Tale libreria è in genere già presente nella maggior parte dei sistemi GNU/Linux perché richiesta come dipendenza per il funzionamento di numerose applicazioni di uso comune ma se così non fosse può essere installata con attraverso il gestore di pacchetti della propria distribuzione.172 In alternativa è possibile scaricare i sorgenti del software dalla pagina principale del progetto.
Lo strumento xmllint, tra le sue molteplici funzionalità, permette di analizzare uno o più documenti XML al fine di controllarne non solo il requisito di well-formedness ma anche la validità, ovvero la conformità alle regole specificate all'interno di file DTD o di uno schema XML. Si tratta di un'utilità eseguibile solo da riga di comando senza alcuna interfaccia grafica ma di facile utilizzo grazie alla documentazione molto completa (in inglese) consultabile alla pagina di manuale xmllint (1).
A titolo esemplificativo, immaginando di avere il file DTD173 nella stessa posizione in cui si trova il file da validare, il programma può essere eseguito come xmllint --dtdvalid tmx14.dtd --valid --noout <memoria tmx>.
In questo modo il programma non produrrà alcun output se il documento supera il test di validità mentre restituirà un dettagliato messaggio d'errore qualora dovessero verificarsi dei problemi. In caso di errore infatti il messaggio include il numero di riga, una descrizione della situazione anomala con il riferimento a quanto atteso secondo le istruzioni contenute nella DTD e la visualizzazione del punto del documento interessato.
|
I casi di errore riconosciuti sono gli stessi già visti a proposito di TMXValidator: nel riquadro 44, ad esempio, è possibile vedere quel che succede se si sottopone alla verifica un TMX contenente un errore nella posizione degli attributi. In questo caso l'elemento tuid alla riga 17 è stato riferito all'elemento <tuv>, quando invece secondo la DTD la sua posizione dovrebbe essere solamente all'interno di un elemento <tu>.
Rispetto ad altre utilità di validazione, xmllint rende molto facile individuare e correggere gli eventuali errori perché non si limita a specificarne la posizione e la natura ma mostra anche un'anteprima del testo segnalando con esattezza il punto problematico con un accento circonflesso nella riga successiva. Inoltre, altro indubbio vantaggio, qualora nel documento fossero presenti più errori allo stesso tempo il programma analizza il documento fino alla fine e segnala tutti i punti su cui intervenire già alla prima esecuzione, rendendo così più semplice l'intervento di correzione.
In questo modo è possibile verificare in maniera autonoma non solo le TM, ma anche i glossari (TBX), le regole di segmentazione (TBX), i file bilingui (XLIFF) e tutti i documenti basati su XML coinvolti nel processo traduttivo a patto di essere in possesso dei relativi file DTD. Inoltre, qualora venissero rilasciate nuove versioni delle specifiche di formato, è sufficiente inserire il nuovo file come argomento dell'opzione -dtdvalid per la portare a termine la validazione, senza più bisogno di attendere le nuove versioni di un'applicazione creata ad hoc da terzi.
Per quanto semplice, xmllint è molto versatile e permette di verificare la validità di documenti XML non solo sulla base dei file DTD ‘tradizionali’ ma anche di schemi XML con l'opzione -relaxng per quelli di tipo RelaxNG o -schema per gli schemi di tipo XSD redatti secondo il relativo standard del W3C.
Esistono altri strumenti a riga di comando molto diffusi nei sistemi GNU/Linux che permettono di avere accesso in modo molto rapido a informazioni sulle TM come, ad esempio, il numero di unità immagazzinate in un determinato file. L'idea più semplice è sfruttare il comando grep (Global Regular Expression Print), che permette di cercare in uno o più documenti sequenze specificate come espressioni regolari, in modo da contare le occorrenze del tag di chiusura dell'elemento TU ad esempio con grep -c "<\/tu>" <memoria tmx>.
In alternativa, se le memorie sono in formato PO, è possibile ottenere un risultato in modo molto più dettagliato ed elegante utilizzando l'utilità pocount del TTK. Questo programma, eseguibile ancora una volta da riga di comando, accetta in ingresso uno o più file PO e visualizza il conteggio delle stringhe e delle parole tradotte, non tradotte, fuzzy sia sullo stantard output (che eventualmente può essere rediretto su un file di testo con l'operatore >) oppure come documento CSV.174
4.3.5 Considerazioni finali
Le caratteristiche comuni a tutte le utilità di manipolazione, correzione e verifica delle TM qui considerate sono la mancanza di un'interfaccia grafica funzionale (anche TMXValidator la utilizza solo per mostrare gli errori e caricare i file di partenza) e la modalità di esecuzione non interattiva, dal momento che all'utente non è lasciato alcun margine di intervento, nemmeno per attuare misure correttive una volta che sono rilevati errori.
Questi programmi tuttavia possono essere suddivisi in due gruppi. Da un lato, è possibile riconoscere gli strumenti volti a rilevare errori formali (es. sintassi XML) che potrebbero pregiudicare il funzionamento delle memorie soprattutto ai fini dell'interoperabilità, dall'altro quelli che si focalizzano sul ‘contenuto’ e permettono di ottimizzare le TU o rilevare errori concettuali.
Questi ultimi, a loro volta, possono essere suddivisi in due gruppi a seconda dei formati di ingresso: TMX oppure PO. In alcuni casi, strumenti diversi permettono di effettuare lo stesso tipo di operazione sui due formati, ad esempio la fusione con TMXMerger e con pocompendium. In altri casi tuttavia si notano delle discrepanze che pongono su un livello più avanzato il secondo gruppo di utilità.
Con gli strumenti del TTK (ad esempio pofilter, pogrep e pomerge) è possibile estrarre i messaggi che soddisfano determinate condizioni, modificarli a parte e in seguito reintegrarli nel documento di partenza. Nel caso di memorie basate su TMX invece non è disponibile alcuna funzione di ‘manutenzione’ nemmeno semi-interattiva e l'unica possibilità disponibile è intervenire ‘a mano’ sul file TMX con un editor di testo per apportare le modifiche. Rispetto alle soluzioni presenti nel software non libero, anche se gli strumenti di gestione delle TM spesso sono poco ‘visibili’ e integrate all'interno di altre applicazioni, questo non può non essere segnalato come una (seppur lieve) mancanza.
©inTRAlinea & Diego Beraldin (2013).
Una panoramica sugli strumenti di traduzione assistita
disponibili come software libero, inTRAlinea Monographs
This work can be freely reproduced under Creative Commons License.
Permalink: http://www.intralinea.org/monographs/beraldin/